Как удалить alphago
alphago это вредоносная программа, которая обычно устанавливается на вашем компьютере за вашей спиной. Показывает рекламу и сохранение наших личных данных являются две главные задачи, почему alphago разработан. Такие объявления можно увидеть либо в виде баннеров, всплывающих окон, поддельные результаты на Google, или синий/зеленый подчеркнутые слова прямо в Контент каждый посещаемый веб-сайт.
К тому же губит Ваш опыт просмотра, alphago также занимает время, шпионить за все, что вы делаете в интернете, экономя каждый сайт вы посещаете, и каждый поиск вы делаете. alphago идет насколько анализируя то, что у вас есть на вашем компьютере, по их “статистике” только с целью, или так они утверждают на их использование лицензии. Истина заключается в том, что все эти данные сохраняются в коммерческих базах данных, содержащих коммерческого профиля, которые будут проданы впоследствии.
Используйте средство удаления вредоносных программ Spyhunter только для целей обнаружения. Узнайте больше о SpyHunter Spyware Detection Tool и шаги для удаления SpyHunter.
Установив бесплатное программное обеспечение, как alphago будет установлена на наших компьютерах. Все это занимает для вас, чтобы отвлекаться во время установки, чтобы не заметить, что это рекламное предлагается вместе с программой, которую вы намеревались установить. Вот почему мы всегда говорим, что вы всегда должны проявлять особую осторожность при установке что-то новое в свой компьютер.
Этот рекламное также может быть найден добавленные в поддельные обновления, как правило, на Java или Flash, часто встречается в видео потоковое веб-сайтов.
Если вы уже инфицированы alphago, будьте осторожны с сайтов, предлагающих вам удаления решения, потому что вы могли закончиться вверх следующие поддельные совет, который будет принимать вас, чтобы загрузить и оплатить scareware, который будет трудно удалить тоже.
Шаг 1: Остановите все alphago процессы в диспетчере задач
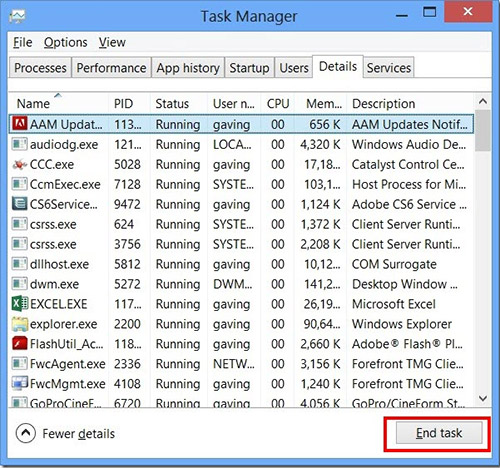
- Нажмите и удерживайте Ctrl + Alt + Del, чтобы открыть диспетчер задач
- Перейдите на вкладку Подробности и конец всех связанных с ними процессов alphago (выберите процесс и нажмите кнопку завершить задачу)
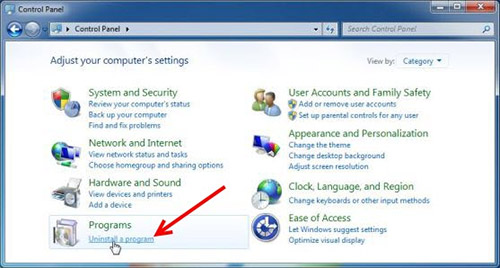
Шаг 2: Удалите alphago сопутствующие программы
- Нажмите кнопку Пуск и откройте панель управления
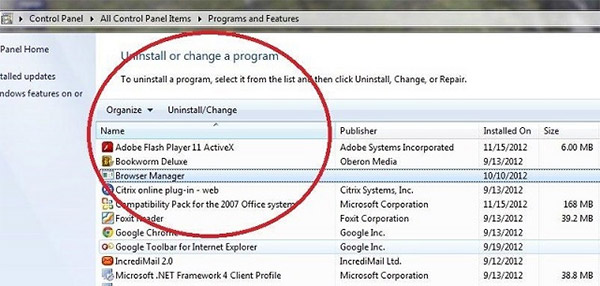
- Выберите удалить программу в разделе программы
- Подозрительного программного обеспечения и нажмите кнопку Удалить/изменить
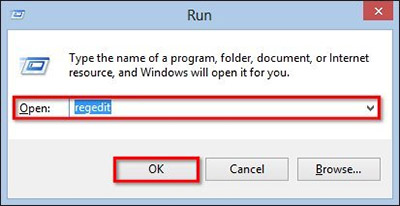
Шаг 3: Удалите вредоносные alphago записи в системе реестра
- Нажмите Win + R чтобы открыть выполнить, введите «regedit» и нажмите кнопку ОК
- Если контроль учетных записей пользователей, нажмите кнопку ОК
- Однажды в редакторе реестра, удалите все связанные записи alphago
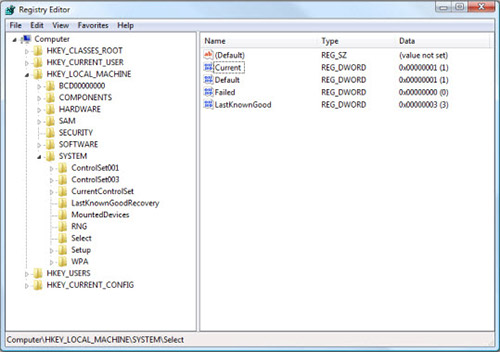
Шаг 4: Устранить вредоносные файлы и папки, связанные с alphago
- Нажмите кнопку Пуск и откройте панель управления
- Нажмите Просмотр, выберите крупные значки и откройте свойства папки
- Перейдите на вкладку Вид, проверить показывать скрытые файлы, папки или драйверы и нажмите кнопку ОК
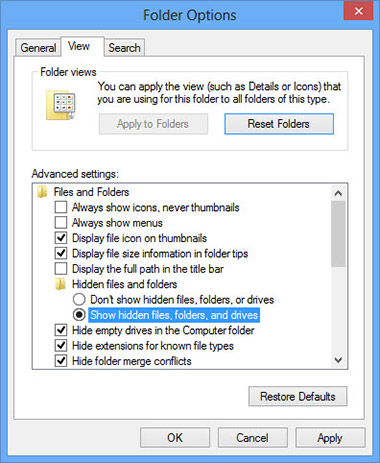
- Удалить все alphago связанные файлы и папки
%AllUsersProfile%\random.exe
%Temp%\random.exe
%AllUsersProfile%\Application Data\random
Шаг 5: Удаление alphago из вашего браузера
Используйте средство удаления вредоносных программ Spyhunter только для целей обнаружения. Узнайте больше о SpyHunter Spyware Detection Tool и шаги для удаления SpyHunter.
Используйте средство удаления вредоносных программ Spyhunter только для целей обнаружения. Узнайте больше о SpyHunter Spyware Detection Tool и шаги для удаления SpyHunter.
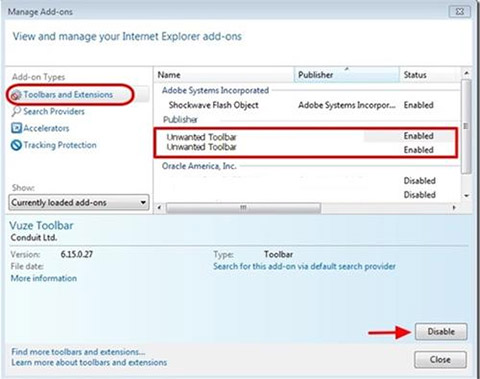
Internet Explorer
- Запуск Internet Explorer, нажмите на значок шестерни → Управление надстройками
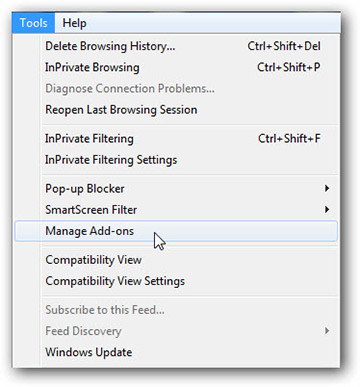
- Выбрать раздел панели инструментов и расширения и отключите подозрительные расширения
Скачать утилиту чтобы удалить alphago
Используйте средство удаления вредоносных программ Spyhunter только для целей обнаружения. Узнайте больше о SpyHunter Spyware Detection Tool и шаги для удаления SpyHunter.
Mozilla Firefox
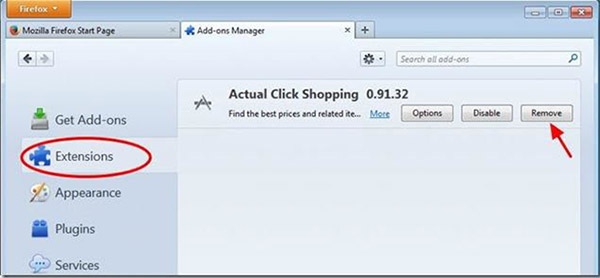
- Откройте Mozilla, нажмите сочетание клавиш Ctrl + Shift + A и перейти к расширения
- Выберите и удалите все ненужные расширения
Скачать утилиту чтобы удалить alphago
Используйте средство удаления вредоносных программ Spyhunter только для целей обнаружения. Узнайте больше о SpyHunter Spyware Detection Tool и шаги для удаления SpyHunter.
Google Chrome
- Откройте браузер, нажмите меню и выберите инструменты → расширения
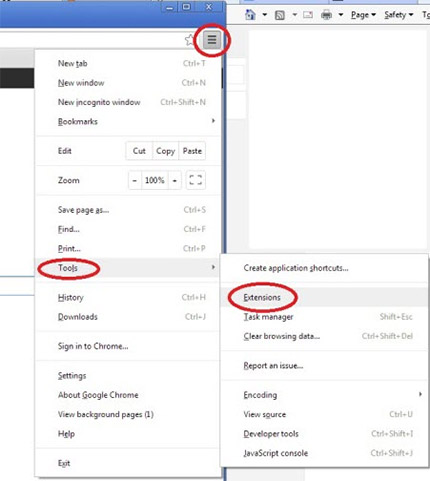
- Выберите подозрительные надстройки и нажмите на значок корзины для его удаления
* SpyHunter сканера, опубликованные на этом сайте, предназначен для использования только в качестве средства обнаружения. более подробная информация о SpyHunter. Чтобы использовать функцию удаления, вам нужно будет приобрести полную версию SpyHunter. Если вы хотите удалить SpyHunter, нажмите здесь.
AlphaGo: что это за нейросеть и как она перевернула мир ИИ?
Кинематограф постоянно повторяет нам, что искусственный интеллект скоро захватит мир и поработит людей. В качестве предвестников такой угрозы выступают программы, подобные «АльфаГо».
«АльфаГо» — это ряд программ на основе искусственного интеллекта, которые используются для игры в Го.
Среди всех версий этой программы особенно известна «AlphaGo Zero», которая победила в Го все предыдущие версии и даже чемпиона мира по этой игре. Но самое удивительное заключается в том, что «AlphaGo Zero» обучалась без помощи человека.
Хотя любой искусственный интеллект должен быть обучен и тренирован человеком, «AlphaGo Zero» научилась самостоятельно, что является огромным прорывом в исследовании искусственного интеллекта.
Возможно, такие достижения в будущем приведут к появлению более сложных и умных машин, но не стоит паниковать по поводу того, что искусственный интеллект захватит мир.
Что это за игра?
Игра Го является одной из самых старых настольных игр, ее возраст составляет около 5000 лет по разным источникам. Основное правило заключается в том, что на игровом поле, разделенном перпендикулярными линиями на множество квадратиков, играют два игрока, используя белые и черные камни.
Игроки по очереди расставляют свои камни на пересечениях линий, пытаясь окружить как можно больше территории. Если камни одного цвета окружают камни другого цвета, те, что находятся внутри, удаляются с игрового поля.
Побеждает игрок, который окружил больше территории к концу игры. Есть и другие правила, но этих достаточно для понимания того, что такое «АльфаГо».
Сложная ли игра Го?
Многие не знакомы с настольной игрой Го и ее сложностью. Чтобы лучше понять эту игру, давайте сравним ее с шашками и шахматами.
В шашках игрок имеет примерно 10 вариантов хода, что делает игру не очень сложной. Но уже в 1994 году программа обыграла чемпиона мира по шашкам.
В шахматах игроку доступно в среднем 25 вариантов хода за игру, но уже в 1997 году программа победила чемпиона мира Гарри Каспарова.
Когда игрок играет в Го, он сталкивается с 361 возможным вариантом хода на начальном этапе, что делает эту игру невероятно сложной. За игру игрок может сделать от 45 до 75 ходов, поэтому для победы ему нужно провести огромный анализ игрового поля, расставляя камни и окружая камни противника.
Игра в Го считается профессиональной и сложной из-за необходимости просчитывать все возможные комбинации ходов. При этом выбор камня на 5-м ходу может повлиять на результат игры только на 45-м ходу или вообще не повлиять.
Но в 2016 году была разработана программа АльфаГо, которая обыграла тогдашнего чемпиона Ли Седоля со счетом 4:1, однако Ли Седоль смог один раз победить программу.
Разработка алгоритма программы для шашек, шахмат и Го одинакова: программа строит дерево возможных вариантов игры и идет по ветке, которая приводит ее к победе.
Из-за огромного числа игровых вариаций, дерево для игры Го получается очень разветвленным и глубоким, требуя много времени на его разработку. Поэтому время между разработкой программ для шахмат и игры Го значительно отличается, что обусловлено сложностью игры в Го.
Программа АльфаГо
Рассматривая вопрос о программе AlphaGo, стоит обратить внимание на процесс ее обучения. Для создания алгоритма AlphaGo были использованы две нейронные сети, которые работали одновременно и пытались предсказать ход, который сделал бы человек.
Одна из них была медленной, но точной, с процентом верных предсказаний 57%, в то время как вторая была быстрой, но менее точной. Обе сети обучались на данных о реальных ходах и играх людей высокого уровня, собранных с различных серверов игры Го.
Кроме того, сети самостоятельно формировали свои деревья, дополняя их при достижении конца ветки. Затем эти две сети сталкивались между собой, играя друг с другом и улучшая свои навыки.
Позднее к этим двум натренированным сетям была добавлена третья, которая оценивала ситуацию на доске и прогнозировала ее исход: победа или поражение. В результате AlphaGo состоит из трех разных функций, каждая из которых выполняет свою задачу.
Первой проверкой программы AlphaGo стала игра с чемпионом Европы по Го в 2015 году, которую программа выиграла со счетом 5:0. Однако это не вызвало особого внимания, потому что «чемпион Европы» не является высоким титулом в мире Го.
Однако игра 2016 года запомнилась навсегда. Во-первых, это была уже вторая версия AlphaGo. Во-вторых, в соперниках был один из самых титулованных и лучших игроков по Го — Ли Седоль.
И, наконец, это был единственный игрок, который смог одолеть компьютер, хотя и проиграл в целом. В честь этой версии программы она была названа AlphaGo Lee.
После этого были еще игры в 2017 году между AlphaGo и топовыми игроками в Го, но все они проигрывали программе. Таким образом, AlphaGo одержала убедительную победу над человеком в противостоянии игры Го.
Заключение
АльфаГо является лишь началом противостояния между человеком и компьютером в области игр.
На сегодняшний день активно разрабатываются системы для нескольких игр, в которых данные не настолько открыты, как в Го, и просчитать все возможные ходы наперед будет значительно сложнее, даже при правильно построенной системе.
Человек научился создавать подобные системы для игр, что делает его бессильным перед компьютером в этой области.
Однако, как только рамки будут сняты и потребуется анализировать ситуации и думать, как действовать, возможны новые формы противостояния между человеком и компьютером в играх. Мы можем только предполагать, что ждет нас в будущем в этой области.
Самая популярная нейросеть 2023 года. ChatGPT-бот в Telegram предоставляет простой и бесплатный способ взаимодействия с ИИ, без необходимости регистрации, использования VPN и дополнительных номеров — ССЫЛКА.
Этот бот отличается от других тем, что не требует оплаты за использование и может быть использован в любом количестве — пользуйтесь на здоровье.
AlphaGo на пальцах
Итак, пока наши новые повелители отдыхают, давайте я попробую рассказать как работает AlphaGo. Пост подразумевает некоторое знакомство читателя с предметом — нужно знать, чем отличается Fan Hui от Lee Sedol, и поверхностно представлять, как работают нейросети.
Disclaimer: пост написан на основе изрядно отредактированных логов чата closedcircles.com, отсюда и стиль изложения, и наличие уточняющих вопросов
Как все знают, компьютеры плохо играли в Го потому, что там очень много возможных ходов и пространство поиска настолько велико, что прямой перебор помогает мало.
Лучшие программы используют так называемый Monte Carlo Tree Search — поиск по дереву с оценкой нодов через так называемые rollouts, то есть быстрые симуляции результата игры из позиции в ноде.
AlphaGo дополняет этот поиск по дереву оценочными функциями на основе deep learning, чтобы оптимизировать пространство перебора. Статья изначально появилась в Nature (и она там за пейволлом), но в интернетах ее можно найти. Например тут — https://gogameguru.com/i/2016/03/deepmind-mastering-go.pdf
Сначала поговорим про составные кусочки, а потом как они комбинируются
Шаг 1: тренируем нейросеть, которая учится предсказывать ходы людей — SL-policy network
Берем 160K доступных в онлайне игр игроков довольно высокого уровня и тренируем нейросеть, которая предсказывает по позиции следующий ход человека.
Архитектура сети — просто 12 уровней convolution layers с нелинейностью и softmax на каждую клетку в конце. Такая глубина в целом сравнима с сетями для обработки изображений прошлого поколения (гугловский Inception-v1, VGG, все эти дела)
Важный момент — что нейросети дается на вход:
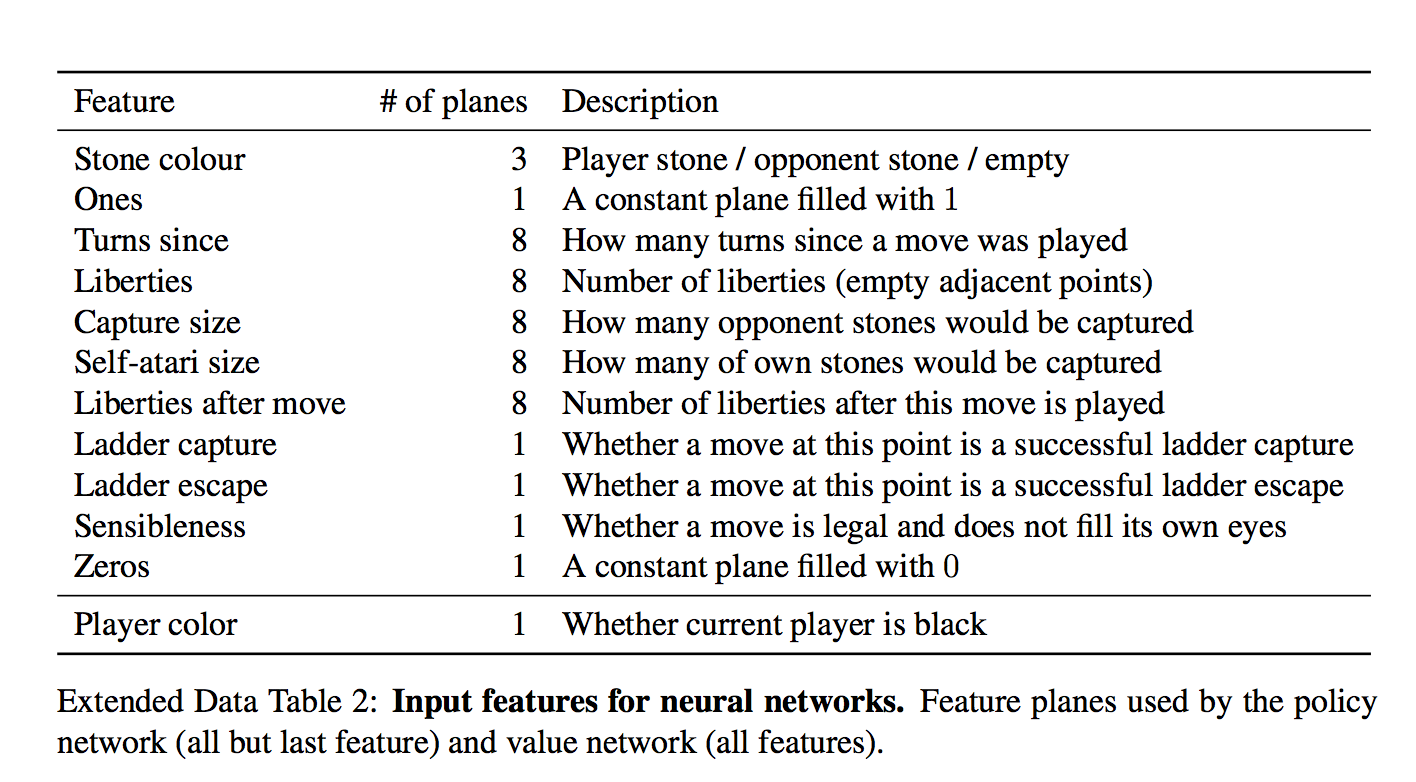
Для каждой клетки на вход дается 48 фич, они все есть в таблице (каждое измерение — это бинарная фича)
Набор интересный. На первый взгляд кажется, сети нужно давать только есть ли в клетке камень и если есть, то какой. Но фиг там!
Есть и тривиально вычисляющиеся фичи типа «количество степеней свободы камня», или «количество камней, которые будут взяты этим ходом»
Есть и формально неважные фичи типа «как давно было сделан ход»
И даже специальная фича для частого явления «ladder capture/ladder escape» — потенциально долгой последовательности вынужденных ходов.
а что за «всегда 1» и «всегда 0»?
Они просто чтобы добить количество фич до кратного 4-м, мне кажется.
И вот на этом всем сетка учится предсказывать человеческие ходы. Предсказывает с точностью 57% и к этому надо относиться осторожно — цель предсказания, человеческий ход, все же неоднозначен.
Авторы показывают, впрочем, что даже небольшие улучшения в точности сильно сказываются на силе в игре (сравнивая сетки разной мощности)

Отдельно от SL-policy, тренируют fast rollout policy — очень быструю стратегию, которая является просто линейным классификатором.
Ей на вход дают еще больше заготовленных фич
То есть, ей дают фичи в виде заранее заготовленных паттернов
Она гораздо хуже, чем модель с глубокой сетью, но зато сверх-быстрая. Как она используется — будет понятно дальше
Шаг 2: тренируем policy еще лучше через игру с собой (reinforcement learning) — RL-policy network
Выбираем противника из пула прошлых версий сети случайно (чтобы не оверфитить на саму себя), играем с ним партию до конца просто выбирая наиболее вероятный ход из предсказания сети, опять же без всякого перебора.
Единственный reward — это собственно результат игры, выиграл или проиграл.
После того, как reward известен, вычисляем как нужно сдвинуть веса — проигрываем партию заново и на каждом ходу двигаем веса, влияющие на выбор выбранной позиции, по градиенту в + или в — в зависимости от результата. Другими словами, применяем этот reward как направление градиента к каждому ходу.
(для любознательных — там чуть более тонко и градиент умножается на разницу между результатом и оценкой позиции через value network)
И вот повторяем и повторяем этот процесс — после этого RL-policy значительно сильнее SL-policy из первого шага.
Предсказание этой натренированной RL-policy уже рвет большинство прошлых программ, играющих в Го, без всяких деревьев и переборов.
Включая DarkForest Фейсбука?
С ней не сравнивали, непонятно.
Интересная деталь! В оригинальной статье пишется, что этот процесс длился всего 1 день (остальные тренировки — недели).
Шаг 3: натренируем сеть, которая «с одного взгляда» на расстановку говорит нам, какие у нас шансы выиграть! — Value network
Т.е. предсказывает всего одно значение от -1 до 1.
У нее ровно та же архитектура, что и у policy network (есть один лишний convolution layer, кажется) + естественно fully connected layer в конце.
То есть у нее те же фичи?
value network дают еще одну фичу — играет игрок черными или нет (policy network передают «свой-чужой» камень, а не цвет). Я так понимаю, это чтобы она могла учесть коми — дополнительные очки белым, за то что они ходят вторыми
Оказывается, что ее нельзя тренировать на всех позициях из игр людей — так как много позиций принадлежит игре с тем же результатом, такая сеть начинает оверфитить — т.е. запоминать, какая это партия, вместо того, чтобы оценивать позицию.
Поэтому ее обучают на синтетических данных — делают N ходов через SL network, потом делают случайный легальный ход, потом доигрывают через RL-network чтобы узнать результат, и обучают на ходе N+2 (!) — только на одной позицию за сгенерированную игру.
Итак, вот есть у нас эти обученные кирпичики. Как мы с их помощью играем?
TL;DR: Policy network предсказывает вероятные ходы чтобы уменьшить ширину перебора (меньше возможных ходов в ноде), value network предсказывает насколько выигрышна позиция, чтобы уменьшить необходимую глубину перебора
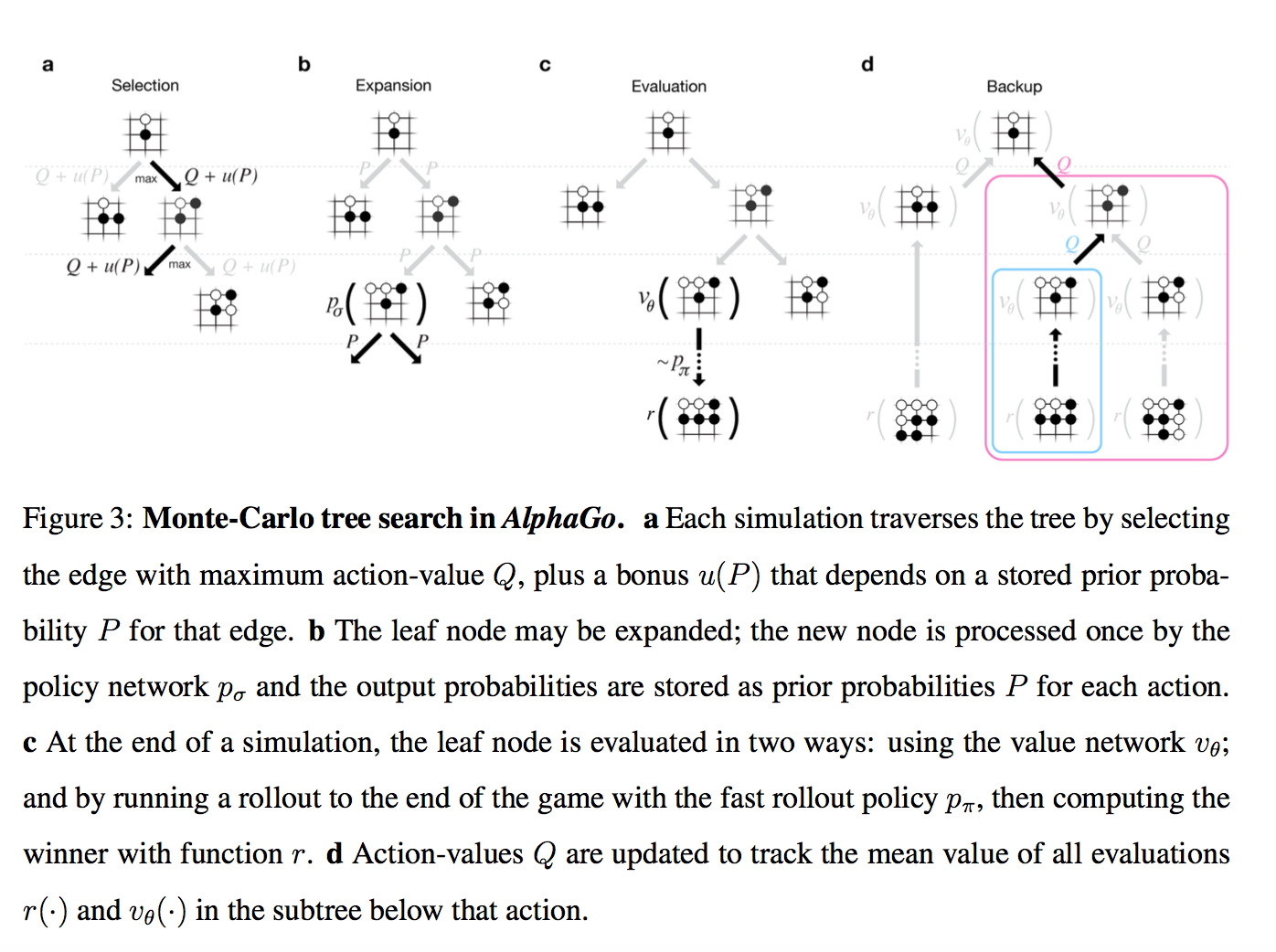
Внимание, картинко!
Итак, у нас есть дерево позиций, в руте — текущая. Для каждой позиции есть некое значение Q, которое означает насколько она ведет к победе.
Мы на этом дереве параллельно проводим большое количество симуляций.
Каждая симуляция идет по дереву туда, где больше Q + m(P). m(P) — это специальная добавка, которая стимулирует exploration. Она больше, если policy network считает, что у этого хода большая вероятность и меньше, если по этому пути уже много ходили
(это вариация стандартной техники multi-armed bandit)
Когда симуляция дошла по дереву до листа, и хочет походить дальше, где ничего еще нет…
То новый созданный нод дерева оценивается двумя способами
- во-первых, через описанный выше value network
- во-вторых, играется до конца с помощью супер-быстрой модели из Шага 1 (это и называется rollout)
Собственно, все. Лучшим ходом объявляется нод, через который бегали чаще всех (оказывается, это чуть стабильнее чем этот Q-score). AlphaGo сдается, если у всех ходов Q-score < -0.8, т.е. вероятность выиграть меньше 10%.
Интересная деталь! В пейпере для изначальных вероятностей ходов P использовалась не RL-policy, а более слабая SL-policy.
Эмпирически оказалось, что так чуть лучше (возможно, к матчу с Lee Sedol уже не оказалось, но вот с Fan Hui играли так), т.е. reinforcement learning нужен был только для того, чтобы обучить value network
Напоследок, что можно сказать про то, чем версия AlphaGo, которая играла с Fan Hui (и была описана в статье), отличалась от версии, которая играет с Lee Sedol:
- Кластер мог стать больше. Максимальная версия кластера в статье — 280 GPUs, но Fan Hui играл с версией с 176 GPUs.
- Похоже, стала больше тратить времени на ход (в статье все эстимейты даны для 2 секунд на ход) + добавился некий ML на тему менеджмента времени
- Было больше времени на тренировку сетей до матча. Мое личное подозрение — принципиально то, что больше времени на reinforcement learning. 1 день в изначальной статье это как-то даже не смешно.
- alphago
- deepmind
- deep learning
- reinforcement learning
При подготовке материала использовались источники:
http://www.4threatsremoval.com/ru/udalit-alphago/
https://vc.ru/u/1692689-neyrochat/684083-alphago-chto-eto-za-neyroset-i-kak-ona-perevernula-mir-ii
https://habr.com/ru/articles/279071/