Советы по открытию файла PEG
Не удается открыть файл PEG? Ты не единственный. Тысячи пользователей ежедневно сталкиваются с подобными проблемами. Ниже вы найдете советы по открытию файлов PEG, а также список программ, поддерживающих файлы PEG.
PEG расширение файла
| Имя файла | Peggle Replay Format |
|---|---|
| Разработчик файлов | PopCap Games |
| Категория файла | Файлы игр |
Файл PEG поддерживается в операционных системах 2. В зависимости от вашей операционной системы вам может потребоваться другое программное обеспечение для обработки файлов PEG. Ниже приводится сводка количества программ, которые поддерживают и открывают файл PEG на каждой системной платформе.
Операционные системы
 1
1 1
1 0
0 0
0 0
0 0
0
Что такое файл PEG?
Файл в формате PEG относится к категории Файлы игр. Создателем этого файла является PopCap Games. Файлы игр состоит из # ЧИСЛА # похожих файлов. Peggle Replay Format чаще всего встречается в операционных системах 2. Файл будет работать на Mac OS, Windows системах, но, к сожалению, не на других. Для обработки этого файла рекомендуется использовать Peggle. Это программа, созданная PopCap Games, Inc.. В качестве альтернативы вы можете использовать # ЧИСЛО # других программ.
Как открыть файл PEG?
Основная проблема с Peggle Replay Format заключается в том, что файл PEG неправильно связан с программами. Это приводит к тому, что файл PEG открывается системными приложениями, не предназначенными для этой цели, или отображает сообщение об отсутствии связанной программы. Эту проблему можно быстро решить, следуя приведенным ниже инструкциям.
Первое, что вам нужно сделать, это просто «дважды щелкнуть » по значку файла PEG, который вы хотите открыть. Если в операционной системе есть соответствующее приложение для ее поддержки, а также существует связь между файлом и программой, файл следует открыть.
Шаг 1. Установите Peggle
В этом случае вы должны сначала убедиться, что на компьютере установлено приложение Peggle. Это можно сделать, набрав Peggle в поисковой системе операционной системы. Если у нас нет этой программы, стоит ее установить, так как она поможет вам автоматически связать файл PEG с Peggle. Ниже приведен список программ, поддерживающих файл PEG.
Программы для открытия файла PEG
Не забывайте загружать программы, поддерживающие файлы PEG, только из проверенных и безопасных источников. Предлагаем использовать сайты разработчиков программного обеспечения.

Peggle
Peggle
Шаг 2. Создайте ассоциацию Peggle с файлами PEG.
Если, несмотря на установленное приложение, файл PEG не запускается в приложении Peggle, необходимо создать ассоциацию файлов. Связь может быть создана с помощью раскрывающегося списка, доступного, если щелкнуть файл правой кнопкой мыши и выбрать « Свойства». Информация о файле и программе, с которой он связан, доступна здесь. Изменения можно внести с помощью кнопки «Изменить» . Если в списке нет программного обеспечения, просто выберите «Обзор» и вручную выберите каталог, в котором установлено приложение. Установка флажка «Всегда использовать выбранную программу . » навсегда связывает файл PEG с программой Peggle.
Шаг 3. Обновите Peggle до последней версии.
Неисправность также может быть связана с программой Peggle, возможно, что Peggle Replay Format требует более новую версию программы. Некоторые приложения позволяют выполнять обновление с уровня программы, а для других вам необходимо загрузить установщик со страницы PopCap Games, Inc. и установить.
Шаг 4. Проверьте наличие следующих проблем с файлом PEG.
Если описанные выше действия не помогли, вы можете предположить, что сам файл неправильный. Файловые проблемы можно разделить на следующие:
Файл № ROZ # пуст или неполный.
Очень часто файл может иметь размер 0 или быть неполным. Это предполагает усечение содержимого файла PEG при загрузке или копировании. Единственный вариант восстановления — снова загрузить файл.
Файл PEG инфицирован вредоносным ПО.
Самая частая причина здесь — компьютерные вирусы. Проверка на вирусы с использованием новейшей антивирусной программы должна решить проблему. Некоторые поставщики антивирусов также предоставляют бесплатные онлайн-сканеры. Для достижения наилучших результатов мы просканируем всю операционную систему, а не только наш файл PEG. Однако помните, что не каждый зараженный файл PEG можно восстановить, поэтому важно регулярно делать резервные копии.
Файл более старой версии
Более старая версия файла PEG не всегда может поддерживаться последней версией программного обеспечения. За помощью следует обращаться к разработчику программного обеспечения, поскольку они обычно рекомендуют использовать бесплатные конвертеры файлов или установить более старую версию программы.
Файл поврежден
Причин неудачи может быть много. В зависимости от типа файла его необходимо исправить. Иногда в самой программе есть опции для восстановления самого популярного повреждения файла PEG. Самый простой способ — восстановить файл из резервной копии, если она есть, или связаться с PopCap Games
Файл PEG можно зашифровать
При чтении появляется сообщение о том, что файл был зашифрован или поврежден. Зашифрованные файлы PEG нельзя воспроизводить на других компьютерах, кроме того, на котором они были зашифрованы, их необходимо расшифровать перед использованием на другом устройстве.
У вас ограниченный доступ к файлу
Операционная система защищает файлы в некоторых местах (например, в корне системного раздела) от несанкционированного доступа. Проблема только в записи в файл, а не в его чтении. Лучше всего переместить PEG в другой каталог.
PEG файл используется другой программой
Эта проблема обычно затрагивает более сложные файлы. Некоторые типы файлов могут быть открыты только в одной программе за раз. Просто закройте ненужные программы. Если ошибка сохраняется после закрытия других программ, подождите некоторое время. Антивирусные программы или создаваемая резервная копия могут заблокировать файл на некоторое время без ведома пользователя. Если и это не помогло, перезагрузите устройство.
Визуализация работы PEG парсера
В прошлый раз получился простой генератор парсера PEG. Сейчас же я покажу, что на самом деле делает сгенерированный парсер при разборе программы. Я погрузился в ретро-мир ASCII-арта, в частности, библиотеку с именем «curses», которая доступна в стандартной поставке Python для Linux и Mac, а также как дополнение для Windows.
Содержание серии статей о PEG-парсере в Python
- PEG парсеры
- Реализация PEG парсера
- Генерация PEG парсера
- Визуализация работы PEG парсера
- Леворекурсивные PEG грамматики
- Добавление экшенов в грамматику PEG
- Мета-грамматика для PEG парсера
- Реализация остальных возможностей PEG
- PEG на Core Developer Sprint
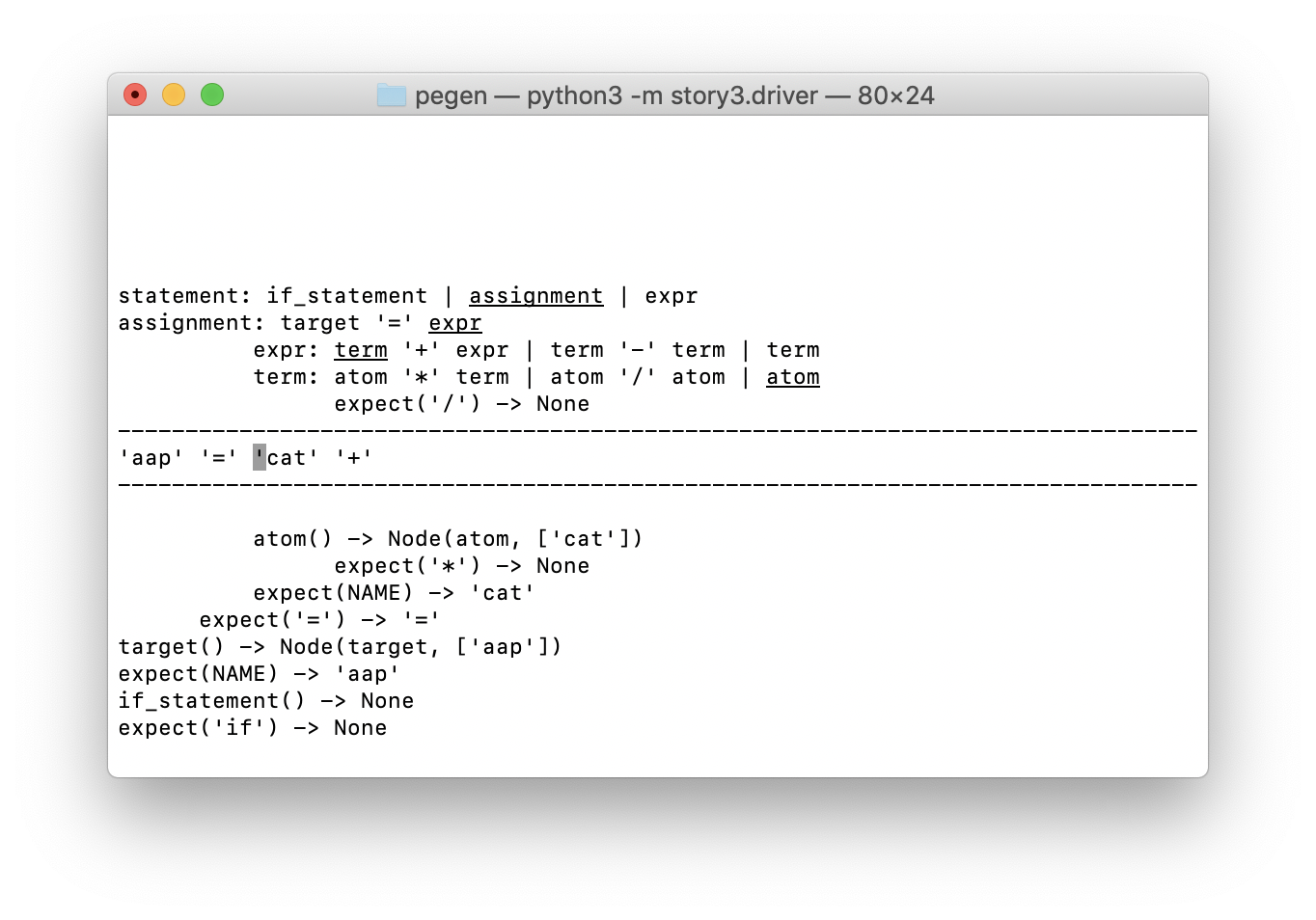
Давайте посмотрим на визуализацию. Экран разделён на три части, как это и принято в ASCII, линией дефисов:
- В верхней части показан стек вызовов синтаксического анализатора, который, как вы помните, является анализатором рекурсивного спуска с неограниченным возвратом. Чуть ниже я объясню более подробно.
- Однострочный раздел в середине показывает содержимое буфера токенов с курсором, указывающим на токен, который будет анализироваться следующим.
- Внизу мы визуализируем кэш-память, используемую алгоритмом packrat-парсера. Запись его элементов несколько похожа на некоторые элементы стека парсера (с результатами).
Главное, что нужно знать, чтобы понимать эту визуализацию, это то, что отступы строк в верхней и нижней частях соответствуют буферу токенов.
- Первые две строки (начинающиеся с statement и assignment ) показывают вызовы соответствующих методов парсера, которые проводят анализ прямо сейчас. Они были вызваны, когда указатель токенизатора был перед первым токеном ( ‘aap’ ).
- Следующие две строки (начинающиеся с expr и term ) выровнены с началом токена ‘cat’ , где были вызваны соответствующие методы парсера.
- Пятая и последняя строка визуализации стека показывает вызов expect(‘/’) , который возвращает None . Он вызвался в позиции токена ‘+’ .
Отступы элементов в кэше также соответствуют позиции в буфере токенов. Например, внизу есть отрицательные записи в кэше, они были получены при поиске токена ‘if’ и правила if_statement в начале буфера токенов. Мы также находим и успешные записи в кэше для токена ‘=’ и для NAME (в частности, ‘cat’ ), соответствующих дальнейшим позициям ввода.
Как в блоке стека анализатора, так и в блоке кэша возвращённые вызовы отображаются как function(args) -> result . Иногда в стеке парсера отображается несколько возвращаемых методов — я сделал это, чтобы уменьшить дрожание текста от частой смены содержимого.
(Говоря о дрожании, верхние строки стека анализатора перемещаются вверх, когда в стек добавляется вызов, и опускаются, когда он извлекается из стека. Т.е. каждый новый вызов вставляется в самый низ блока визуализации стека, сдвигая существующие строки вверх. Мне кажется, что наблюдать за этой частью экрана особых проблем не составляет, ну по крайней мере для меня. Вероятно, значительная часть нашего мозга посвящена отслеживанию движущихся объектов. 🙂
Кэш визуализируется как LRU, с часто используемыми элементами в верхней части; более редкие опускаются вниз экрана. (Прототип packrat-парсера, который я показал в предыдущих статьях, не использует LRU, но, вероятно, будет хорошей идеей оптимизировать потребление памяти.)
Давайте посмотрим на некоторые детали при визуализации стека синтаксического анализа. Верхние четыре записи соответствуют методам парсера, которые ещё в обработке, каждая строка представляет собой строку из грамматики. Подчеркнутый пункт — тот, который породил следующий вызов.
Т.е. судя по скриншоту, мы находимся на второй альтернативе для statement , а именно на assignment . В этом правиле мы находимся на третьем пункте, а именно на expr . В правиле expr мы находимся только в первом пункте первой альтернативы ( term ‘+’ expr ); и в правиле для term мы находимся в последней альтернативе ( atom ).
Ниже мы видим результат, который привел к сбою второй альтернативы ( atom ‘/’ term ): expect(‘/’) -> None отступ с токеном ‘+’ . На следующем шаге, мы увидим, как она попадает в кэш.
Но наверняка вы бы предпочли сами увидеть всю анимацию!
Я записал полный анализ канонического примера программы
Вы также можете поиграть с уже готовым кодом, но учтите, что это не спортивно.
Когда вы просматриваете записанный GIF, может показаться несколько странным, что иногда следующий токен не отображается (например, в самом начале стек увеличивается на несколько записей до того, как обнаруживается токен ‘aap’ ). Это именно то, что анализатор видит: буфер токенов заполняется лениво. Токены не сканируются, пока синтаксический анализатор не запросит их, вызвав функцию expect() . Как только токен попадает в буфер, он же там и остаётся, даже если анализатор отматывает последовательность токенов назад. Обратный трекинг показывается в буфере токенов курсором, который прыгает влево; на записи много таких ситуаций. Вы также можете наблюдать за заполнением кэша, когда анализатор не делает дополнительных рекурсивных вызовов. (Я должен выделить, когда это происходит, но у меня не хватило времени.)
На следующей неделе я буду развивать синтаксический анализатор, возможно, добавив свой взгляд на левые правила рекурсивной грамматики. (Они великолепны!)
Благодарности: для записи я использовал ttygif от Ильи Чоли и ttyrec от Мэтью Йординга.
Лицензия на эту статью и приведенный код: CC BY-NC-SA 4.0
Визуализация работы PEG парсера
Oct 23, 2019 05:06 · 766 words · 4 minute read python peg
Оригинал: ‘Visualizing PEG Parsing’ by Guido van Rossum
В прошлый раз получился простой генератор парсера PEG. Сейчас же я покажу, что на самом деле делает сгенерированный парсер при разборе программы. Я погрузился в ретро-мир ASCII-арта, в частности, библиотеку с именем «curses», которая доступна в стандартной поставке Python для Linux и Mac, а также как дополнение для Windows.
Давайте посмотрим на визуализацию. Экран разделён на три части, как это и принято в ASCII, линией дефисов:
- В верхней части показан стек вызовов синтаксического анализатора, который, как вы помните, является анализатором рекурсивного спуска с неограниченным возвратом. Чуть ниже я объясню более подробно.
- Однострочный раздел в середине показывает содержимое буфера токенов с курсором, указывающим на токен, который будет анализироваться следующим.
- Внизу мы визуализируем кэш-память, используемую алгоритмом packrat-парсера. Запись его элементов несколько похожа на некоторые элементы стека парсера (с результатами).
Главное, что нужно знать, чтобы понимать эту визуализацию, это то, что отступы строк в верхней и нижней частях соответствуют буферу токенов.
- Первые две строки (начинающиеся с statement и assignment ) показывают вызовы соответствующих методов парсера, которые проводят анализ прямо сейчас. Они были вызваны, когда указатель токенизатора был перед первым токеном ( ‘aap’ ).
- Следующие две строки (начинающиеся с expr и term ) выровнены с началом токена ‘cat’ , где были вызваны соответствующие методы парсера.
- Пятая и последняя строка визуализации стека показывает вызов expect(‘/’) , который возвращает None . Он вызвался в позиции токена ‘+’ .
Отступы элементов в кэше также соответствуют позиции в буфере токенов. Например, внизу есть отрицательные записи в кэше, они были получены при поиске токена ‘if’ и правила if_statement в начале буфера токенов. Мы также находим и успешные записи в кэше для токена ‘=’ и для NAME (в частности, ‘cat’ ), соответствующих дальнейшим позициям ввода.
Как в блоке стека анализатора, так и в блоке кэша возвращённые вызовы отображаются как function(args) -> result . Иногда в стеке парсера отображается несколько возвращаемых методов — я сделал это, чтобы уменьшить дрожание текста от частой смены содержимого.
(Говоря о дрожании, верхние строки стека анализатора перемещаются вверх, когда в стек добавляется вызов, и опускаются, когда он извлекается из стека. Т.е. каждый новый вызов вставляется в самый низ блока визуализации стека, сдвигая существующие строки вверх. Мне кажется, что наблюдать за этой частью экрана особых проблем не составляет, ну по крайней мере для меня. Вероятно, значительная часть нашего мозга посвящена отслеживанию движущихся объектов. 🙂
Кэш визуализируется как LRU, с часто используемыми элементами в верхней части; более редкие опускаются вниз экрана. (Прототип packrat-парсера, который я показал в предыдущих статьях, не использует LRU, но, вероятно, будет хорошей идеей оптимизировать потребление памяти.)
Давайте посмотрим на некоторые детали при визуализации стека синтаксического анализа. Верхние четыре записи соответствуют методам парсера, которые ещё в обработке, каждая строка представляет собой строку из грамматики. Подчеркнутый пункт — тот, который породил следующий вызов.
Т.е. судя по скриншоту, мы находимся на второй альтернативе для statement , а именно на assignment . В этом правиле мы находимся на третьем пункте, а именно на expr . В правиле expr мы находимся только в первом пункте первой альтернативы ( term ‘+’ expr ); и в правиле для term мы находимся в последней альтернативе ( atom ).
Ниже мы видим результат, который привел к сбою второй альтернативы ( atom ‘/’ term ): expect(‘/’) -> None отступ с токеном ‘+’ . На следующем шаге, мы увидим, как она попадает в кэш.
Но наверняка вы бы предпочли сами увидеть всю анимацию!
Я записал полный анализ канонического примера программы
Вы также можете поиграть с уже готовым кодом, но учтите, что это не спортивно.
Когда вы просматриваете записанный GIF, может показаться несколько странным, что иногда следующий токен не отображается (например, в самом начале стек увеличивается на несколько записей до того, как обнаруживается токен ‘aap’ ). Это именно то, что анализатор видит: буфер токенов заполняется лениво. Токены не сканируются, пока синтаксический анализатор не запросит их, вызвав функцию expect() . Как только токен попадает в буфер, он же там и остаётся, даже если анализатор отматывает последовательность токенов назад. Обратный трекинг показывается в буфере токенов курсором, который прыгает влево; на записи много таких ситуаций. Вы также можете наблюдать за заполнением кэша, когда анализатор не делает дополнительных рекурсивных вызовов. (Я должен выделить, когда это происходит, но у меня не хватило времени.)
На следующей неделе я буду развивать синтаксический анализатор, возможно, добавив свой взгляд на левые правила рекурсивной грамматики. (Они великолепны!)
Благодарности: для записи я использовал ttygif от Ильи Чоли и ttyrec от Мэтью Йординга.
Лицензия на эту статью и приведенный код: CC BY-NC-SA 4.0
При подготовке материала использовались источники:
https://file.tips/ru/extension/peg
https://habr.com/ru/articles/471866/
https://tyvik.ru/posts/peg/visualization/