Deductor 5.3 – что нового
С момента выхода версии 5.2 прошел немалый срок. За это время на базе Deductor было реализовано множество проектов, значительно расширился функционал платформы. Изменения коснулись практически всех модулей системы.
Веб-сервисы
Deductor 5.3 позволяет полноценно интегрироваться с веб-сервисами.
Платформа позволяет работать в режиме клиента для любого веб-сервиса, имеющего WSDL-описание. Обращения к внешнему сервису могут производиться на любом этапе обработки. Связывание и настройка XML-запросов производится без программирования, при помощи мастеров.
В состав Deductor включен новый серверный компонент – Deductor Integration Server, который является веб-сервисом. Таким образом, результат любой аналитической обработки становится доступным для всех продуктов, взаимодействующих при помощи обмена XML-запросами. WSDL-описание формируется автоматически, без программирования и использования дополнительных инструментов.
Масштабируемая архитектура
Использование Deductor Integration Server позволяет строить отказоустойчивые системы, поддерживающие автоматическую балансировку нагрузки, горячую замену аналитических серверов и повышение производительности обработки за счет включения в кластер дополнительных Deductor Analytic Server-ов.
Обработчики
Серьезно переработан блок очистки данных. Вместо одного обработчика «Парциальная обработка» появилось несколько модулей:
- Оценка качества данных
- Заполнение пропусков
- Редактирование выбросов
- Спектральная обработка
Обработчик «Оценка качества данных» предназначен для проведения профайлинга и аудита данных с целью определения степени их пригодности для решения задач анализа по объективным критериям. Выполнив единственную операцию, пользователь может сразу увидеть «масштаб бедствия» и наметить способы улучшения качества данных.
Добавлены новые обработчики:
- Сэмплинг. Построение репрезентативной выборки. Варианты сэмплинга: случайный, равномерный, стратифицированный, пользовательский, отбор со смещением.
- Разбиение данных на обучающее и тестовое множество. Обеспечивает возможность строить Data Mining модели на идентичных выборках.
- Конечные классы. Расчет оптимальных способов квантования, с удобной визуализацией, расчетом показателей качества разбиения, возможностью ручной правки конечных классов.
- Масштабируемые алгоритмы кластеризации: CLOPE, EM.
- Декомпозиция временных рядов. Выделение тренда, сезонной составляющей и остатка, с возможностью удобной ручной правки полученных коэффициентов.
- Нечеткая фильтрация данных и Изменение переменных
Доработаны и значительно улучшены имеющиеся обработчики:
- Факторный анализ: методы вращения варимакс и квартимакс;
- Логистическая регрессия: пошаговые методы отбора, внесение поправок на априорные вероятности, взвешенная регрессия, расчет баллов скоринговых карт, взаимодействия второго уровня на основе кросс-переменных.
- Линейная регрессия: пошаговые методы отбора переменных.
- Калькулятор: повторное использование полей, обращение по абсолютным адресам, новые функции.
- Групповая обработка: упрощение процесса построения сценариев
Визуализаторы
Многочисленные улучшения и новые возможности в диаграмме, OLAP-кубе и кросс-диаграмме.
Существенная переработка визуализатора ROC-кривая, который переименован в Качество классификации с включением диаграмм Lift-кривых и расчетом индекса Gini.
Импорт и экспорт данных
Deductor Academic отныне, помимо csv-файлов и хранилища данных на базе Firebird, поддерживает быстрый «родной» формат Deductor Data File.
Добавлена поддержка импорта/экспорта данных из/в файлы MS Excel 2007, 2010.
Улучшена работа с платформой 1С: поддержка импорта 1С:Предприятия 8.2, а также построение запросов к 1С:Предприятие 8.0, 8.1, 8.2.
Добавлена возможность импорта данных из CRM-систем:
- Terrasoft CRM
- Microsoft Dynamics CRM
Переработан импорт и экспорт из XML-документов на основе хранилища XSD-схем.
Новый уровень аналитики
Deductor 5.3 поднимает возможности аналитической обработки на новый уровень.
Поддержка веб-сервисов и новых источников данных позволяет проще интегрировать систему в разнородное программное окружение. Теперь аналитика не ограничивается только внутрикорпоративными данными, любой внешний веб-сервис может быть встроен в конвейер принятия решений. Сам Deductor тоже может стать источником данных для других систем.
Новые обработчики и визуализаторы значительно упрощают процесс анализа: автоматический перебор вариантов обработки, выбор и предложение оптимальных способов очистки, удобная визуализация результатов анализа.
Включение многих новых обработчиков и изменение существующих, в значительной степени направлены на повышение уровня автоматизации работы аналитика. Они позволяют строить гибкие, универсальные, но при этом простые для понимания и поддержки сценарии обработки.
В новой версии значительное внимание уделено повышению скорости обработки больших объемов данных: добавлены новые масштабируемые Data Mining алгоритмы, оптимизирована работа существующих обработчиков. Применение Deductor Integration Server позволяет производить аналитические расчеты на кластере серверов, что значительно снижает время отклика и повышает отказоустойчивость комплекса.
- Описание платформы
- Преимущества
- Функционал
- Слайдшоу
- Деморолики
- Документация
- Компоненты платформы
- Варианты поставки
- Скачать бесплатно
- Системные требования
Смотрите также:
-
Записи выступлений
- Deductor 5.3 — новые возможностиПрезентации
- Deductor 5.3 — новые возможности
4. Содержание отчета
Отчет по лабораторной работе представляется в виде документа Word. В состав документа входят:
- Название работы
- Цель работы
- Копии экрана, иллюстрирующие выполнение задания лабораторной работы
- Выводы по работе
5. Контрольные вопросы
- Для чего предназначен мастер импорта программы Deductor Studio?
- Для чего предназначен мастер обработки программы Deductor Studio?
- Для чего предназначен мастер отображений программы Deductor Studio?
- Для чего следует проводить подготовку данных для анализа?
- Что такое шумы и аномалии в данных?
- Какими методами можно убрать шумы в системе Deductor?
- Какими методами можно убрать аномалии данных в системе Deductor?
- Для чего используется парциальная предобработка?
- Для чего используется спектральная обработка?
- Какие виды спектральной обработки имеются в системе Deductor?
6. Список рекомендуемой литературы
- Барсегян А.А., Куприянов М.С., Степаненко В.В., Холод И.И. Методы и модели анализа данных: OLAP и Data Mining. – Спб.: БХВ-Петербург, 2004. – 336 с.: ил
- Загоруйко Н.Г. Прикладные методы анализа данных и знаний. – Новосибирск: Изд-во Ин-та математики, 1999. – 270 с.
- Тюрин Ю.Н., Макаров А.А. Статистический анализ данных на компьютере / Под ред. В. Э. Фигурнова – М.: ИНФРА-М, 1998. – 528 с., ил.
2. Теоретические сведения
Факторный анализ. Факторный анализ – группа методов многомерного статистического анализа, которые позволяют представить в компактной форме обобщенную информацию о структуре связей между наблюдаемыми признаками изучаемого объекта на основе выделения некоторых непосредственно не наблюдаемых факторов.Факторный анализ служит для понижения размерности пространства входных факторов. Обработку можно выполнять как в автоматическом режиме (с указанием порога значимости), так и самостоятельно (основываясь на значениях матрицы значимости). Первым этапом факторного анализа является выбор новых признаков, которые являются линейными комбинациями прежних и «вбирают» в себя большую часть общей изменчивости входных факторов. Поэтому они содержат большую часть информации, заключенной в первоначальных данных. В обработчике «Факторный анализ» это осуществляется с помощью метода главных компонент. Этот метод сводится к выбору новой ортогональной системы координат в пространстве наблюдений. В качестве первой главной компоненты избирают направление, вдоль которого массив данных имеет наибольший разброс. Выбор каждой последующей главной компоненты происходит так, чтобы разброс данных вдоль нее был максимальным и чтобы эта главная компонента была ортогональна другим главным компонентам, выбранным прежде. Корреляционный анализ. Корреляционный анализ- совокупность основанных на математической теории корреляции методов обнаружения корреляционной зависимости между двумя случайными признаками или факторами. Корреляционный анализ применяется для оценки зависимости выходных полей данных от входных факторов и устранения незначащих факторов. Принцип корреляционного анализа состоит в поиске таких значений, которые в наименьшей степени взаимосвязаны с выходным результатом. Такие факторы могут быть исключены из результирующего набора данных практически без потери полезной информации. Критерием принятия решения об исключении является порог значимости. Если степень взаимозависимости между входным и выходным факторами меньше порога значимости, то соответствующий фактор отбрасывается как незначащий.
Импорт данных из 1С с помощью мастера
Аналитическая платформа Deductor 5.3 позволяет импортировать в сценарий обработки данных из 1С все объекты, регистры, реквизиты. Обеспечивается импорт из любого прикладного решения, построенного на базе 1С:Предприятие.
В этом коротком деморолике наглядно показано, как в Deductor Studio 5.3:
- Настроить подключение к 1С.
- Импортировать данные из 1С, используя настроенное подключение.
-
Доступ к данным
- 1С:Предприятие 8.xДоступ к данным
- 1С:Предприятие 7.7Функционал
- Доступ к даннымБаза знаний
- Переменные: применение при импорте из 1С
Рассылка о платформе Loginom
Loginom Company (бывш. BaseGroup Labs) — профессиональный поставщик программных продуктов и решений в области бизнес-аналитики. Мы специализируемся на разработке систем для глубокого анализа данных, охватывающих вопросы сбора, интеграции, очистки данных, построения моделей и визуализации.
© 2023 Loginom Company
ООО «Аналитические технологии»
Пользовательское соглашение.
Лабораторная работа 7 Аналитическая платформа Deductor: импорт и предобработка данных
Цель работы: познакомиться с системой Deductor Studio, получить навыки импорта данных, научиться осуществлять предобработку данных.
1. Импорт данных
Импорт данных является отправной точкой анализа данных. Импорт в Deductor может осуществляться из популярных форматов хранения данных, таких как Excel, Access, MS SQL, Oracle, Текстовый файл и прочих. Кроме того, имеется универсальный доступ к любому источнику данных посредством ADO или ODBC.  Рассмотрим пример импорта данных из текстового файла с разделителями, который будет необходим при апробировании технологий платформы Deductor на предлагаемых примерах. Импорт осуществляется путем вызова мастера импорта на панели «Сценарии»
Рассмотрим пример импорта данных из текстового файла с разделителями, который будет необходим при апробировании технологий платформы Deductor на предлагаемых примерах. Импорт осуществляется путем вызова мастера импорта на панели «Сценарии»  После запуска мастера импорта укажем тип импорта “Текстовый файл с разделителями” и перейдем к настройке импорта. Укажем имя файла, из которого необходимо получить данные (пример для парциальной обработки). В окне просмотра выбранного файла можно увидеть содержание данного файла.
После запуска мастера импорта укажем тип импорта “Текстовый файл с разделителями” и перейдем к настройке импорта. Укажем имя файла, из которого необходимо получить данные (пример для парциальной обработки). В окне просмотра выбранного файла можно увидеть содержание данного файла. 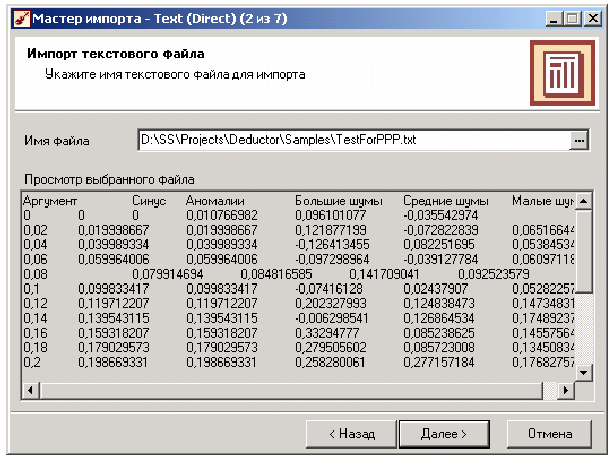 Далее перейдем к настройке параметров импорта. На этой странице мастера предоставляется возможность указать, с какой строки следует начать импорт, указать, то, что первая строка является заголовком, возможность добавить первичный ключ. Указать, что является символом–разделителем столбцов, а также указать ограничитель строк, разделитель целой и дробной части вещественного числа, разделитель компонентов даты и ее формат.
Далее перейдем к настройке параметров импорта. На этой странице мастера предоставляется возможность указать, с какой строки следует начать импорт, указать, то, что первая строка является заголовком, возможность добавить первичный ключ. Указать, что является символом–разделителем столбцов, а также указать ограничитель строк, разделитель целой и дробной части вещественного числа, разделитель компонентов даты и ее формат. 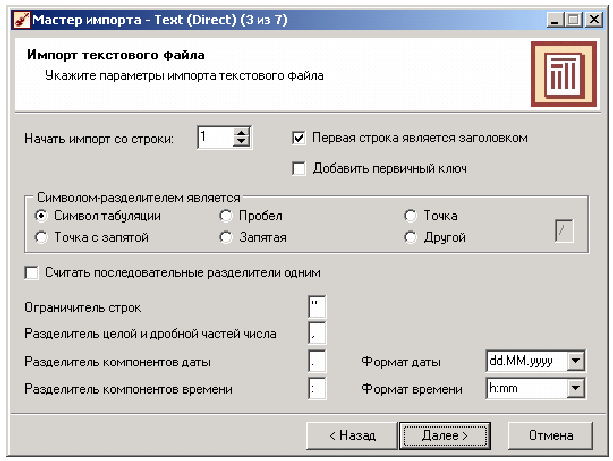 В данном случае параметры по умолчанию на этой странице мастера установлены правильно, а именно: начать импорт с первой строки, первая строка является заголовком, разделителем между столбцами является знак табуляции, разделителем целой и дробной частей является запятая. Далее перейдем к настройке свойств полей. На этом шаге мастера предоставляется возможность настроить имя, название (метку), размер, тип данных, вид данных и назначение. Некоторые свойства (например, тип данных) можно задавать для выделенного набора столбцов. Вид данных определяет – конечный ли это набор (дискретные) или бесконечный (непрерывные). Назначение столбцов определяет характер их использования в алгоритмах обработки (при импорте можно оставить значение по умолчанию).
В данном случае параметры по умолчанию на этой странице мастера установлены правильно, а именно: начать импорт с первой строки, первая строка является заголовком, разделителем между столбцами является знак табуляции, разделителем целой и дробной частей является запятая. Далее перейдем к настройке свойств полей. На этом шаге мастера предоставляется возможность настроить имя, название (метку), размер, тип данных, вид данных и назначение. Некоторые свойства (например, тип данных) можно задавать для выделенного набора столбцов. Вид данных определяет – конечный ли это набор (дискретные) или бесконечный (непрерывные). Назначение столбцов определяет характер их использования в алгоритмах обработки (при импорте можно оставить значение по умолчанию).  Для правильного импорта данных необходимо изменить тип данных у первых трех столбцов («АРГУМЕНТ», «СИНУС», «АНОМАЛИИ»). Тип данных по умолчанию неверный, поскольку программа определяет его, основываясь на значениях первой строки данных. В данном случае там находятся нули – целые числа. Поэтому программа определила, что столбец содержит целочисленные значения. Выделим их с помощью мыши и укажем им тип данных – «Вещественный». Далее осталось только выполнить импорт данных, нажав на кнопку «Пуск» на следующем шаге мастера импорта. После импорта данных на следующем шаге мастера необходимо выбрать способ отображения данных. В данном случае самым информативным является диаграмма, выберем ее.
Для правильного импорта данных необходимо изменить тип данных у первых трех столбцов («АРГУМЕНТ», «СИНУС», «АНОМАЛИИ»). Тип данных по умолчанию неверный, поскольку программа определяет его, основываясь на значениях первой строки данных. В данном случае там находятся нули – целые числа. Поэтому программа определила, что столбец содержит целочисленные значения. Выделим их с помощью мыши и укажем им тип данных – «Вещественный». Далее осталось только выполнить импорт данных, нажав на кнопку «Пуск» на следующем шаге мастера импорта. После импорта данных на следующем шаге мастера необходимо выбрать способ отображения данных. В данном случае самым информативным является диаграмма, выберем ее.  От того, какие способы отображения будут выбраны на этом этапе, зависят последующие шаги мастера. В данном случае необходимо настроить, какие столбцы диаграммы следует отображать и как именно.
От того, какие способы отображения будут выбраны на этом этапе, зависят последующие шаги мастера. В данном случае необходимо настроить, какие столбцы диаграммы следует отображать и как именно. 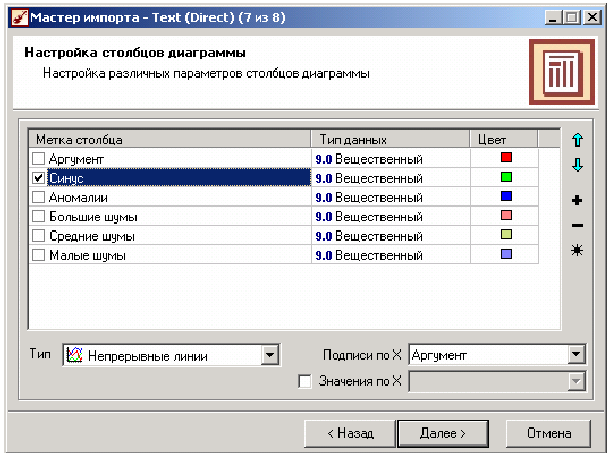 Выберем для отображения поле «СИНУС» и тип диаграммы «Линии». На последнем шаге мастера необходимо указать название ветки в дереве сценариев. Напишем в поле заголовка окна «Импорт примера для демонстрации парциальной обработки» и нажмем «Готово». На этом работа мастера импорта заканчивается. Теперь в дереве сценариев появится новый узел с необходимыми данными. В главном окне программы представлены все выбранные отображения данных этого узла. В данном случае только диаграмма. При подготовке материала использовались источники:
Выберем для отображения поле «СИНУС» и тип диаграммы «Линии». На последнем шаге мастера необходимо указать название ветки в дереве сценариев. Напишем в поле заголовка окна «Импорт примера для демонстрации парциальной обработки» и нажмем «Готово». На этом работа мастера импорта заканчивается. Теперь в дереве сценариев появится новый узел с необходимыми данными. В главном окне программы представлены все выбранные отображения данных этого узла. В данном случае только диаграмма. При подготовке материала использовались источники:
https://studfile.net/preview/3875492/page:4/
https://basegroup.ru/deductor/video/1s-data-import
https://studfile.net/preview/3356938/
Поделитесь:
Сейчас смотрят:
- Обновление не применимо к этому компьютеру
- При воспроизведении видео нет звука
- InsydeH20 Setup Utility rev 5.0: Как сделать загрузку с USB
- Прохождение Snowrunner на русском
- Call of Duty: Warzone настройка графики
Studio
Цель работы Deductor — формализовать процесс принятия решений и поставить его «на поток». Например, сотрудник, оформляющий кредиты, должен внести данные по потребителю, а система автоматически выдать ответ, на какую сумму данный потребитель может рассчитывать, либо сотрудник отдела закупок при оформлении заказа получить автоматически рассчитанный, рекомендуемый объем закупки каждого товара.
Ключевым лицом в данном процессе является аналитик. Для него необходим инструмент, позволяющий формализовать и гибко перестраивать логику принятия решений. Таким инструментом является Deductor Studio – рабочее место аналитика.
Работа аналитика со Studio сводится к визуальному построению сценариев. Сценарий – последовательность действий, позволяющих получить из данных знания. Вся работа выполняется при помощи мастеров и сводится к комбинированию всего 5 операций:
- Подключение коннектора. Для взаимодействия со сторонними системами необходимо настроить параметры доступа: местоположение, пользователь, пароль и прочее. Через единожды настроенное подключение осуществляется выгрузка и загрузка данных во внешнюю систему. Deductor поддерживает десятки систем: СУБД, хранилища данных, учетные системы, веб-сервисы, офисные программы, файлы.
- Импорт данных. Анализ в Deductor начинается с получения набора данных. При помощи мастера выбираются интересующие таблицы, объекты, файлы и запускается процесс импорта.
- Обработка. Под обработкой подразумевается любое преобразование данных. Поддерживаются десятки методов обработки от расчета по формулам до самообучающихся алгоритмов: очистка данных, трансформация, Data Mining. Механизмы обработки можно комбинировать произвольным образом, реализуя сколь угодно сложную логику анализа.
- Визуализация. Просмотреть данные в Deductor Studio можно на любом этапе обработки. Программа самостоятельно анализирует, каким образом можно отобразить информацию, пользователь должен только выбрать нужный вариант. Deductor включает множество удобных интерактивных визуализаторов: OLAP, таблицы, графики, деревья, карты.
- Экспорт результатов. Завершающим шагом в сценарии обработки чаще всего является экспорт данных. Результаты выгружаются для последующего использования в других программах, например, прогноз продаж передается в систему для формирования заказа на поставку или на корпоративном web-сайте публикуются рассчитанные KPI.
Схема работы Deductor Studio:
Deductor Studio позволяет аналитику автоматизировать рутинные операции по обработке данных и сосредоточиться на интеллектуальной работе: формализация логики принятия решений, построение моделей, прогнозирование. Остальные сотрудники компании могут легко воспользоваться готовыми результатами, не вникая в сложности анализа:
- Аналитическая отчетность. Аналитик перетаскивает мышкой на специальную панель необходимые отчеты. Конечный пользователь при помощи Deductor Viewer просто выбирает интересующий отчет из списка и получает результат. Никаких дополнительных действий делать не требуется. Вся сложная аналитическая обработка выполняется автоматически.
- Интеграция в бизнес-процесс. Аналитик экспортирует результаты в стороннюю систему: сайт, ERP, CRM и т.п., а конечный пользователь увидит в привычной ему программе итог сложной аналитической обработки. Обмен данными может производиться в режиме online или по регламенту. Для встраивания в бизнес-процесс необходимо воспользоваться Analytic или Integration Server.
Объединение всех описанных выше механизмов в Deductor Studio обеспечивает принципиально новое качество анализа: быстрая разработка и адаптация решений, интеграция в существующую инфраструктуру, эволюционное развитие от простой отчетности к глубокой аналитике.
При подготовке материала использовались источники:
https://basegroup.ru/deductor/whatsnew53
https://online-radio24.ru/1-dlya-chego-prednaznachen-master-importa-programmy-deductor-studio/
https://basegroup.ru/deductor/components/studio