Что такое краулинг и как управлять роботами
Выдача ответов на поисковый запрос на странице поиска за долю секунды только верхушка айсберга. В «черном ящике» поисковых систем — просканированные и занесенные в специальную базу данных миллиарды страниц, которые отбираются для представления с учетом множества факторов.
Страница с результатами поиска формируется в результате трех процессов:
- сканирования;
- индексирования;
- предоставления результатов (состоит из поиска по индексу и ранжирования страниц).
В этом выпуске «Азбуки SEO» речь пойдет о сканировании или краулинге страниц сайта.
Как работает сканирование (краулинг) сайта?
Если кратко, краулинг (сканирование, crawling) — процесс обнаружения и сбора поисковым роботом (краулером) новых и обновленные страницы для добавления в индекс поисковых систем. Сканирование — начальный этап, данные собираются только для дальнейшей внутренней обработки (построения индекса) и не отображаются в результатах поиска. Просканированная страница не всегда оказывается проиндексированной.
Поисковый робот (он же crawler, краулер, паук, бот) — программа для сбора контента в интернете. Краулер состоит из множества компьютеров, запрашивающих и выбирающих страницы намного быстрее, чем пользователь с помощью своего веб-браузера. Фактически он может запрашивать тысячи разных страниц одновременно.
Что еще делает робот-краулер:
- Постоянно проверяет и сравнивает список URL-адресов для сканирования с URL-адресами, которые уже находятся в индексе Google.
- Убирает дубликаты в очереди, чтобы предотвратить повторное скачивание одной и той же страницы.
- Добавляет на переиндексацию измененные страницы для предоставления обновленных результатов.
При сканировании пауки просматривают страницы и выполняют переход по содержащимся на них ссылкам так же, как и обычные пользователи. При этом разный контент исследуется ботами в разной последовательности. Это позволяет одновременно обрабатывать огромные массивы данных.
Например, в Google существуют роботы для обработки разного типа контента:
- Googlebot — основной поисковый робот;
- Googlebot News — робот для сканирования новостей;
- Googlebot Images — робот для сканирования изображений;
- Googlebot Video — робот для сканирования видео.
В статье о robots.txt мы собрали полный перечень роботов-пауков. Знакомьтесь 🙂
Кстати, именно с robots.txt и начинается процесс сканирования сайта — краулер пытается обнаружить ограничения доступа к контенту и ссылку на карту сайта (Sitemap). В карте сайта должны находиться ссылки на важные страницы сайта. В некоторых случаях поисковый робот может проигнорировать этот документ и страницы попадут в индекс, поэтому конфиденциальную информацию нужно закрывать паролем непосредственно на сервере.

Просматривая сайты, бот находит на каждой странице ссылки и добавляет их в свою базу. Робот может обнаружить ваш сайт даже без размещения ссылок на него на сторонних ресурсах. Для этого нужно осуществить переход по ссылке с вашего сервера на другой. Заголовок HTTP-запроса клиента «referer» будет содержать URL источника запроса и, скорее всего, сохранится в журнале источников ссылок на целевом сервере. Следовательно, станет доступным для робота.
Как краулер видит сайт
Если хотите проверить, как робот-краулер видит страницу сайта, отключите обработку JavaScript при включенном отладчике в браузере. Рассмотрим на примере Google Chrome:
1. Нажимаем F12 — вызываем окно отладчика, переходим в настройки.
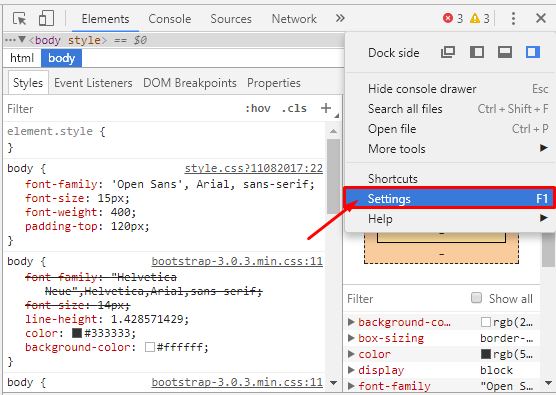
2. Отключаем JavaScript и перезагружаем страницу.
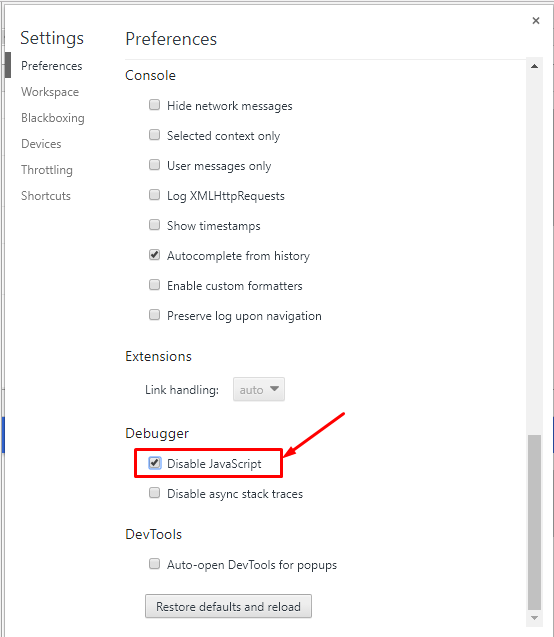
Если в целом на странице сохранилась основная информация, ссылки на другие страницы сайта и выглядит она примерно так же, как и с включенным JavaScript, проблем со сканированием не должно возникнуть.
Второй способ — использовать инструмент Google «Просмотреть как Googlebot» в Search Console.
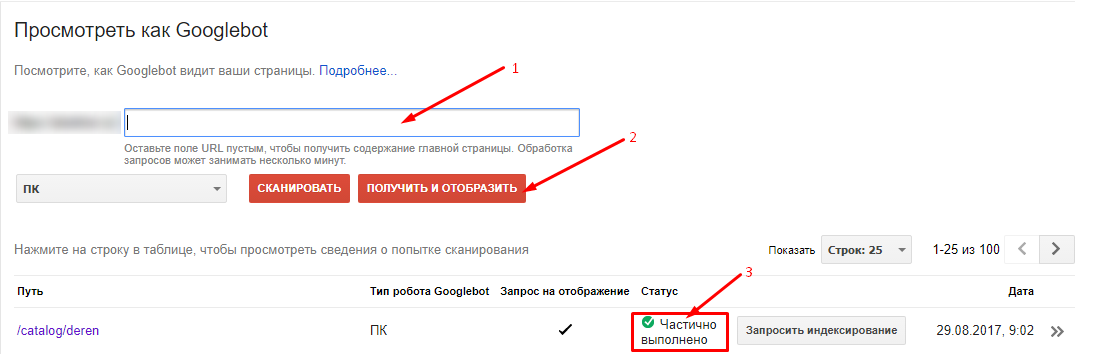
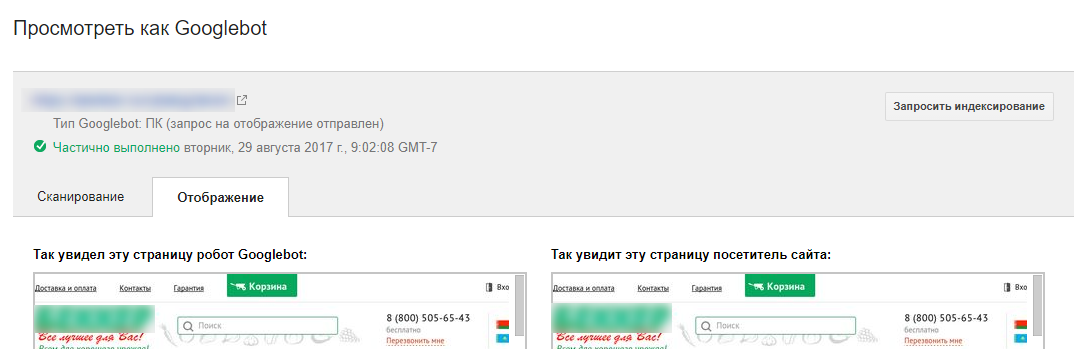
Если краулер видит вашу страницу так же, как и вы, проблем со сканированием не возникнет.
Третий метод — специальное программное обеспечение. Например, Netpeak Spider показывает более 50 разных видов ошибок, найденных при сканировании, и разделяет их по степени важности.
Если страница не отображается так, как вы ожидали, стоит проверить, доступна ли она для сканирования: не заблокирована ли она в robots.txt, в файле .htaccess.
Проблемы со сканированием могут возникать, если сайт создан с помощью технологий Javascript и Ajax , так как поисковые системы пока с трудом сканируют подобный контент.
Как управлять сканированием страниц
Запуск и оптимизация сканирования сайта
Существует несколько методов пригласить робота-паука к себе на сайт:
- Разрешить сканирование сайта, если он был запаролен на сервере, и передать информацию об URL c помощью HTTP-заголовка «referer» при переходе на другой ресурс.
- Разместить ссылку на ваш сайт на другом ресурсе, например, в соцсетях.
- Зарегистрироваться в панелях вебмастеров Google.
- Сообщить о сайте поисковой системе напрямую через кабинет вебмастеров Google.
- Использовать внутреннюю перелинковку страниц для улучшения навигации и сканирования ресурса, например, хлебные крошки.
- Создать карту сайта с нужным списком страниц и разместить ссылку на карту в robots.txt.
Запрет сканирования сайта
- Для ограничения сканирования контента следует защитить каталогов сервера паролем. Это простой и эффективный способ защиты конфиденциальной информации от ботов.
- Ставить ограничения в robots.txt.
- Использовать метатег . С помощью директивы “nofollow” стоит запретить переход по ссылкам на другие страницы.
- Использовать HTTP-заголовок X-Robots tag. Запрет на сканирование со стороны сервера осуществляется с помощью HTTP заголовка X-Robots-tag: nofollow. Директивы, которые применяются для robots.txt, подходят и для X-Robots tag.
Больше информации о использовании http-заголовка в справке для разработчиков.
Управление частотой сканирования сайта
Googlebot использует алгоритмический процесс для определения, какие сайты сканировать, как часто и сколько страниц извлекать. Вебмастер может предоставить вспомогательную информацию краулеру с помощью файла sitemap, то есть с помощью атрибутов:
- — дата последнего изменения файла;
- — вероятная частота изменений страницы;
- — приоритетность.
К сожалению, значения этих атрибутов рассматриваются роботами как подсказка, а не как команда, поэтому в Google Search Console и существует инструмент для ручной отправки запроса на сканирование.
Выводы
- Разный контент обрабатывается ботами в разной последовательности. Это позволяет одновременно обрабатывать огромные массивы данных.
- Для улучшения процесса сканирования нужно создавать карты сайтов и делать внутреннюю перелинковку — чтобы бот смог найти все важные страницы.
- Закрывать информацию от индексирования лучше с помощью метатега или http-заголовка X-Robot tag, так как файл robots.txt содержит лишь рекомендации по сканированию, а не прямые команды к действию.
Читайте больше об инструментах для парсинга сайта , необходимых SEO-специалисту в рутинной работе.
5 способов краулинга веб-сайта

Из Википедии веб-краулер или паук – бот, который с просматривает всемирную паутину, как правило, с целью индексации. Поисковики и другие веб-сайты используют краулеры для обновления своего содержимого или индексации содержимого других сайтов.
Metasploit
Вспомогательный поисковый модуль Metasploit представляет собой модульный поисковый робот, который будет использоваться вместе с wmap или автономно.
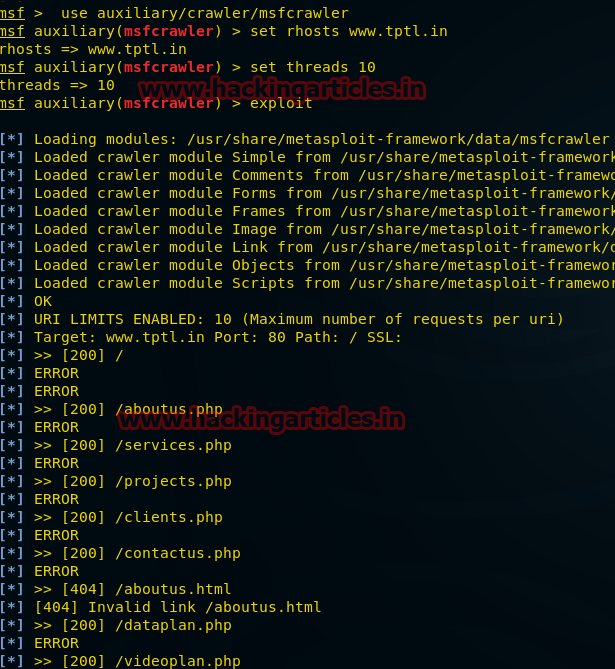
use auxiliary/crawler/msfcrawler msf auxiliary(msfcrawler) > set rhosts www.example.com msf auxiliary(msfcrawler) > exploitВидно, что был запущен сканер, с помощью которого можно найти скрытые файлы на любом веб-сайте, например:
- about.php
- jquery contact form
- html и т. д.
Что невозможно сделать вручную при помощи браузера.
Httrack
HTTrack — это бесплатный краулер и автономный браузер с открытым исходным кодом. Он позволяет полностью скачать веб-сайт, рекурсивно строя все каталоги
получая:
HTTrack упорядочивает относительную структуру ссылок исходного сайта.
Введем следующую команду внутри терминала
httrack http://tptl.in –O /root/Desktop/fileОн сохранит вывод в заданном каталоге /root/Desktop/file

На скриншоте можно увидеть, что Httrack скачал немало информации о веб-сайте, среди которой много:
Black Widow
Представляет собой загрузчик веб-сайтов и офлайн браузер. Обнаруживает и отображает подробную информацию для выбранной пользователем веб-страницы. Понятный интерфейс BlackWidow с логическими вкладками достаточно прост, но обилие скрытых возможностей может удивить даже опытных пользователей. Просто введите желаемый URL и нажмите Go. BlackWidow использует многопоточность для быстрой загрузки всех файлов и проверки ссылок. Для небольших веб-сайтов операция занимает всего несколько минут.
Введем свой URL http://tptl.in в поле адрес и нажмем «Go».

Нажимаем кнопку «Start», расположенную слева, чтобы начать сканирование URL-адресов, а также выбираем папку для сохранения выходного файла. На скриншоте видно, что просматривался каталог C:\Users\RAJ\Desktop\tptl, чтобы сохранить в нем выходной файл.
В каталоге tptl теперь будут храниться все данные веб-сайта:
Website Ripper Copier
Website Ripper Copier (WRC) — это универсальная высокоскоростная программа-загрузчик веб-сайтов. WRC может загружать файлы веб-сайтов на локальный диск для просмотра в автономном режиме, извлекать файлы веб-сайтов определенного размера и типа, такие как:
Также WRC может извлекать большое количество файлов в качестве диспетчера загрузки с поддержкой возобновления.
Вдобавок WRC является средством проверки ссылок на сайты, проводником и веб-браузером с вкладками, предотвращающим всплывающие окна. Website Ripper Copier — единственный инструмент для загрузки веб-сайтов, который может:
- возобновлять прерванные загрузки из:
- HTTP
- HTTPS
- FTP-соединений
Скачать его можно здесь.
Выбираем «websites for offline browsing».
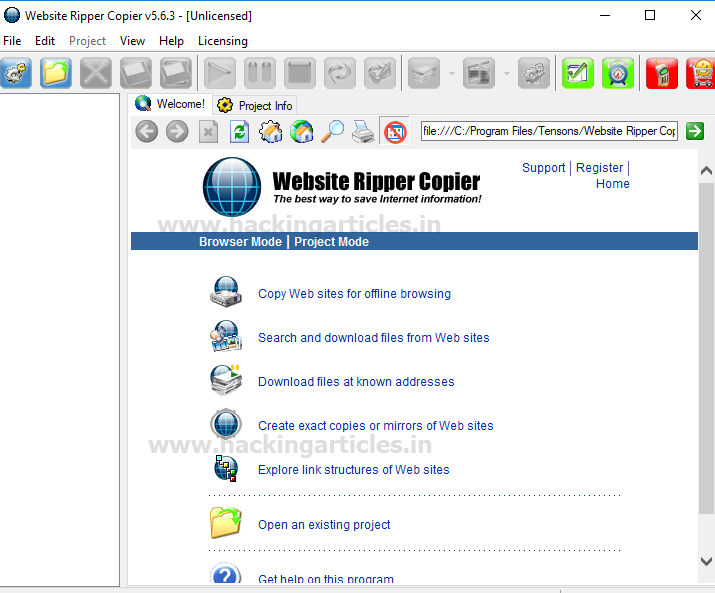
Вводим URL-адрес веб-сайта как http://tptl.in и нажимаем «next».
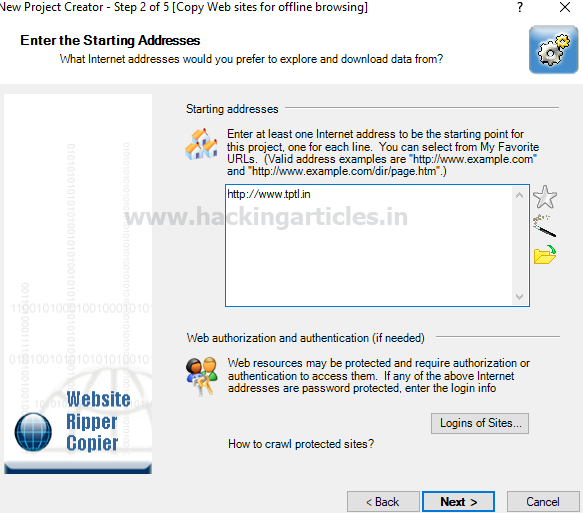
Указываем путь к каталогу, чтобы сохранить результат, после чего жмём «run now».
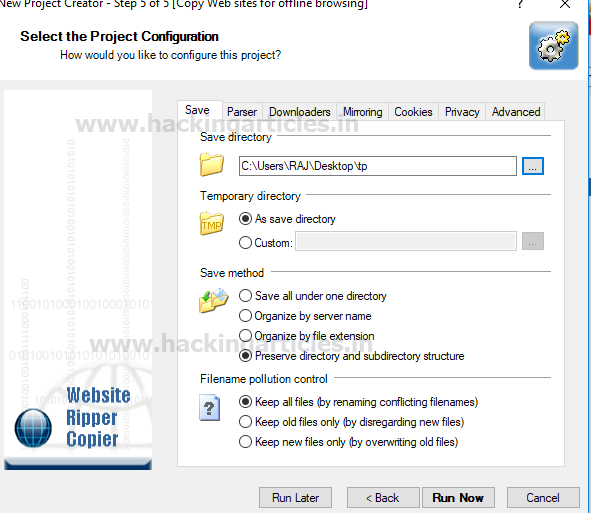
При открытии выбранного каталога tp, внутри него будут файлы:
Burp Suite Spider
Burp Suite Spider – это инструмент для автоматического сканирования веб-приложений, более подробно о котором уже писали на habr. В большинстве случаев желательно отображать приложения вручную, но с помощью Burp Spider данный процесс можно автоматизировать, что упростит работу с очень большими приложениями или при нехватке времени.
На скриншоте видно, что http-запрос был отправлен «пауку» с помощью контекстного меню.
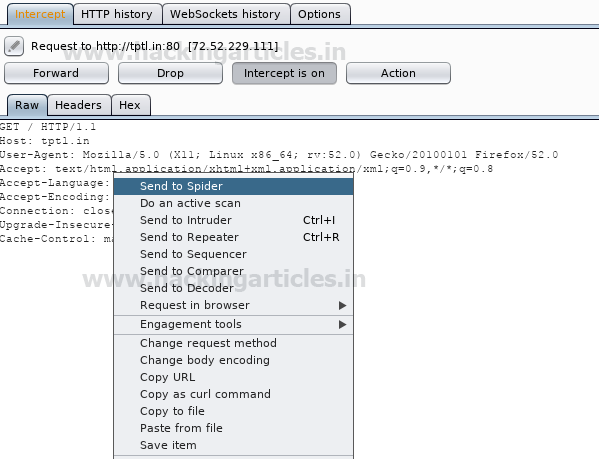
Веб-сайт был добавлен на карту сайта под целевой вкладкой в качестве новой области для веб-сканирования, в результате которого была собрана информация в форме:
Что такое веб-краулер?

Веб-краулеры (поисковые роботы) – важная часть инфраструктуры Интернета. В этой статье мы рассмотрим:
- Определение веб-краулера
- Как работают поисковые роботы?
- Примеры веб-краулеров
- Почему веб-краулеры важны для SEO
- Проблемы, с которыми сталкиваются поисковые роботы
Определение веб-краулера
Веб-краулер — это программный робот, который сканирует Интернет и загружает найденные данные. Большинство краулеров работают под управлением поисковых систем, таких как Google, Bing, Baidu и DuckDuckGo. Поисковые системы применяют свои алгоритмы поиска к собранным данным, чтобы сформировать индекс своей поисковой системы. Индексы позволяют им предоставлять релевантные ссылки пользователям на основе их поисковых запросов.
Существуют поисковые роботы, которые служат не только поисковым системам, но и другим интересам, например The Way Back Machine из Интернет-архива, который предоставляет снимки сайтов в определенный момент времени в прошлом.
Как работают поисковые роботы?
Поисковые роботы, такие как Googlebot, начинают каждый день со списка сайтов, которые они хотят просканировать. Это называется краулинговым бюджетом. Он отражает потребность в индексировании страниц. На краулинговый бюджет влияют два основных фактора: популярность и устаревание. URL-адреса, которые более популярны в Интернете, обычно сканируются чаще, чтобы они оставались свежими в индексе. Поисковые роботы также пытаются предотвратить устаревание URL-адресов в индексе.
Когда краулер подключается к сайту, он начинает с загрузки и чтения файла robots.txt. Файл robots.txt является частью протокола исключения роботов (REP), группы веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям. Владельцы сайтов могут определить, какие пользовательские агенты могут и не могут получать доступ к сайту. В robots.txt также можно определить директиву задержки сканирования, чтобы ограничить скорость запросов, которые сканер делает на сайте. В Robots.txt также перечисляются связанные с сайтом карты сайта, так что краулер может найти каждую страницу и время ее последнего обновления. Если страница не изменилась с момента последнего посещения краулером, он ее пропустит.
Когда поисковый робот, наконец, достигает страницы для сканирования, он отображает ее в браузере, загружая весь HTML, сторонний код, JavaScript и CSS. Эта информация хранится в базе данных поисковой системы, а затем используется для индексации и ранжирования страницы. Он также загружает все ссылки на странице. Ссылки, которых еще нет в индексе поисковой системы, добавляются в список для последующего сканирования.
Соблюдение директив в файле robots.txt является добровольным. Большинство основных поисковых систем следуют директивам robots.txt, но некоторые этого не делают. Злоумышленники, такие как спамеры и ботнеты, игнорируют директивы robots.txt. Даже некоторые законные поисковые роботы, такие как Архив Интернета, игнорируют файл robots.txt.
Примеры веб-краулеров
Поисковые системы имеют несколько типов поисковых роботов. Например, у Google есть 17 типов ботов:
- APIs-Google
- AdSense
- AdsBot Mobile Web Android
- AdsBot Mobile Web
- Googlebot Image
- Googlebot News
- Googlebot Video
- Googlebot Desktop
- Googlebot Smartphone
- Mobile Apps Android
- Mobile AdSense
- Feedfetcher
- Google Read Aloud
- Duplex on the web
- Google Favicon
- Web Light
- Google StoreBot
Почему веб-краулеры важны для SEO
Цель SEO заключается в том, чтобы ваш контент можно было легко найти, когда пользователь выполняет поиск по определенному поисковому запросу. Google не может знать, куда ранжировать ваш контент, если он не проиндексирован.
Поисковые роботы также могут помочь и в других областях. Сайты эл. коммерции часто сканируют сайты конкурентов для анализа выбора продукции и ценообразования. Этот тип сбора данных обычно известен как «веб-скрапинг вместо сканирования». Веб-скрапинг фокусируется на определенных элементах данных HTML. Веб-скраперы очень целенаправленны, тогда как веб-краулеры расставляют широкую сеть и собирают весь контент. На стороне пользователя также есть инструменты SERP API, которые помогают сканировать и собирать данные поисковой выдачи.
Проблемы, с которыми сталкиваются поисковые роботы
Есть ряд проблем, с которыми могут столкнуться поисковые роботы.
Проблема Описание Ограничения robots.txt Если поисковый робот соблюдает ограничения robots.txt, он не сможет получить доступ к определенным страницам или отправить запросы, превышающие произвольное ограничение. Баны IP Поскольку некоторые поисковые роботы не соблюдают ограничения robots.txt, они могут использовать ряд других инструментов для ограничения сканирования. Сайты могут блокировать IP-адреса, которые считаются вредоносными, например, бесплатные прокси данных, используемые мошенниками, или определенные IP ЦОД. Ограничения геолокации Некоторые сайты требуют, чтобы посетитель находился в определенной локации для доступа к содержимому сайта. Хорошим примером является попытка доступа к контенту Netflix USA за пределами США. Большинство гео-ограничений можно преодолеть с помощью резидентных прокси-сетей. CAPTCHA Некоторые веб-сайты, обнаружив большое количество активности из подозрительных источников, выставляют CAPTCHA, чтобы проверить, настоящий ли человек стоит за запросом. CAPTCHA могут нарушить деятельность веб-краулеров. Многие решения для веб-скрапинга имеют инструменты и технологии для преодоления подобных блокировок. Эти инструменты часто используют решение для разблокировки CAPTCHA. Подведем итоги
Поисковые роботы являются важной частью инфраструктуры Интернета. Они позволяют поисковым системам собирать данные, необходимые для создания поисковых индексов и предоставления результатов поиска по запросам пользователей. Многие компании обращаются к краулерам, чтобы помочь им в своих исследованиях. Зачастую они сосредоточены только на одном или двух сайтах, таких как Amazon, Adidas или Airbnb. В таких случаях для их нужд лучше подходят такие инструменты, как веб-парсеры IDE от Bright Data.
При подготовке материала использовались источники:
https://netpeak.net/ru/blog/chto-takoye-krauling-i-kak-upravlyat-robotami/
https://habr.com/ru/companies/alexhost/articles/529120/
https://ru-brightdata.com/blog/web-data-ru/what-is-a-web-crawler