10.4. Принципы построения баз данных
В основе построения БД лежат определенные научные принципы, позволяющие создавать высококачественные системы, отвечающие современным требованиям.
Из множества используемых принципов создания БД (рис.10.1) выделим наиболее существенные:
- интеграции данных;
- централизации управления данными.
Оба принципа отражают суть БД. Интеграция является основой организации БД, централизация управления – основой организации и функционирования СУБД. Остальные принципы в той или иной степени связаны с первыми.
Суть принципа интеграции данных состоит в объединении отдельных, взаимно не связанных данных в единое целое, в роли которого выступает база данных, в результате чего пользователю и его прикладным программам все данные представляются единым информационным массивом. Следование принципу интеграции обеспечивает:
- упрощение поиска взаимосвязанных данных и их совместную обработку;
- уменьшение избыточности данных;
- упрощение процесса ведения БД.
Принцип централизации управления состоит в передаче всех функций управления данными единому комплексу управляющих программ – СУБД.
Рис.10.1. Основные принципы построения баз данных
10.5. Этапы создания баз данных
Процесс создания БД обычно включает следующие этапы:
- проектирование БД;
- создание проектных файлов БД;
- создание БД (формирование и связывание таблиц, ввод данных);
- создание меню приложения;
- создание запросов;
- создание экранных форм, отчетов;
- генерация приложения как исполняемой программы.
Приведенный перечень этапов не является строгим в смысле очередности. Процесс создания БД, как правило, имеет итерационный характер.
Наиболее ответственными и трудоемкими этапами считаются этапы (1-3). На сегодняшний день эти этапы могут быть автоматизированы с помощь использования CASE-средств. CASE-средства оказывают существенное содействие разработчикам БД с момента постановки задачи и начала анализа предметной области до построения физической модели данных, ориентированной на управление конкретной СУБД.
Этапы (4-7) также автоматизированы, но уже в рамках возможностей современных СУБД.
10.6. Классификация и архитектура баз данных
По количеству пользователей выделяют БД:
- персональные;
- корпоративные (многопользовательские).
Корпоративные БД, в свою очередь, различают по архитектуре построения:
- централизованные;
- распределенные.
Работа с централизованной БД напоминает работу в системе централизованной обработки данных, когда каждый пользователь для решения своих задач имеет в распоряжении терминальную часть вычислительной системы (монитор, клавиатуру, аппаратуру связи с центральной ЭВМ), а все информационные и вычислительные ресурсы размещены на центральной ЭВМ.
Распределенные БД в настоящее время строятся в соответствии с перспективной технологией клиент-сервер. В достаточно распространенном варианте она предполагает наличие компьютерной сети и распределенной БД, включающей корпоративную БД и персональные БД. Корпоративная БД размещается на компьютере-сервере, персональные БД – на компьютерах сотрудников подразделений, являющихся клиентами корпоративной БД.
Сервером определенного ресурса в компьютерной сети называется компьютер, управляющий этим ресурсом, клиентом – компьютер, использующий этот ресурс. Если управляемым ресурсом является БД, то соответствующий сервер называется сервером БД.
Достоинством организации информационной системы по архитектуре клиент-сервер является удачное сочетание:
- централизованного хранения, обслуживания и коллективного доступа к общей корпоративной информации;
- индивидуальной работой над персональной информацией.
Структура распределенной БД, построенной по архитектуре клиент-сервер, показана на рис.10.2.
Рис.10.2 Структура распределенной базы данных
Использование архитектуры клиент-сервер дает возможность постепенного наращивания информационной системы организации (фирмы):
- по мере развития предприятия;
- по мере развития самой информационной системы.
Разделение общей БД на корпоративную БД и персональные БД позволяет уменьшить сложность проектирования БД по сравнению с централизованным вариантом, а значит, снизить вероятность ошибок при проектировании и стоимость проектирования.
Основы работы с базами данных
Базы данных и системы управления базами данных. Модели данных
Студент (номер_зачетки, фамилия, имя, отчество, год_рождения).
В основе любой базы данных лежит та или иная модель данных.Модель данных – это совокупность структур данных и операций их обработки. С помощью модели данных могут быть представлены информационные объекты и взаимосвязи между ними. Рассмотрим три основных типа моделей данных: иерархическую, сетевую и реляционную. Иерархическая модельданных представляет собой совокупность узлов, расположенных в порядке их подчинения и образующих по структуре перевернутое дерево. Узел–это совокупность реквизитов данных, описывающих некоторый информационный объект. Иерархическая структура всегда удовлетворяет следующим требованиям:
- каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне;
- иерархическое дерево имеет только один корневой узел, не подчиненный никакому другому узлу и находящийся на самом верхнем уровне;
- к каждому узлу базы данных существует только один путь от корневого узла.
 Рис. 2.7.1. Пример иерархической структуры БД Пример, представленный на рисунке 2.7.1, иллюстрирует использованиеиерархической модели для построения базы данных «Институт». Информация базы данных структурирована в виде деревьев, количество которых равно количеству специальностей в институте. Для рассматриваемого примера иерархическаяструктураорганизации данных правомерна, так как каждый студент учится в определенной (только одной) группе, которая относится к определенной (только одной) специальности. Сетевая модель данных отличается от иерархической модели тем, что каждый узел может быть связан с любым другим узлом. Реляционная модельиспользует организацию данных в виде двумерных таблиц. Каждаяреляционная таблицаобладает следующими свойствами:
Рис. 2.7.1. Пример иерархической структуры БД Пример, представленный на рисунке 2.7.1, иллюстрирует использованиеиерархической модели для построения базы данных «Институт». Информация базы данных структурирована в виде деревьев, количество которых равно количеству специальностей в институте. Для рассматриваемого примера иерархическаяструктураорганизации данных правомерна, так как каждый студент учится в определенной (только одной) группе, которая относится к определенной (только одной) специальности. Сетевая модель данных отличается от иерархической модели тем, что каждый узел может быть связан с любым другим узлом. Реляционная модельиспользует организацию данных в виде двумерных таблиц. Каждаяреляционная таблицаобладает следующими свойствами:
- все столбцы в таблице однородные, т.е. все элементы в одном столбце имеют одинаковый тип (числовой, символьный и т.д.) и максимально допустимый размер;
- каждый столбец имеет уникальное имя;
- одинаковые строки в таблице отсутствуют;
- порядок следования строк и столбцов в таблице может быть произвольным.
Например, реляционной таблицей можно представить информацию о студентах, обучающихся в вузе (рис. 2.7.2). 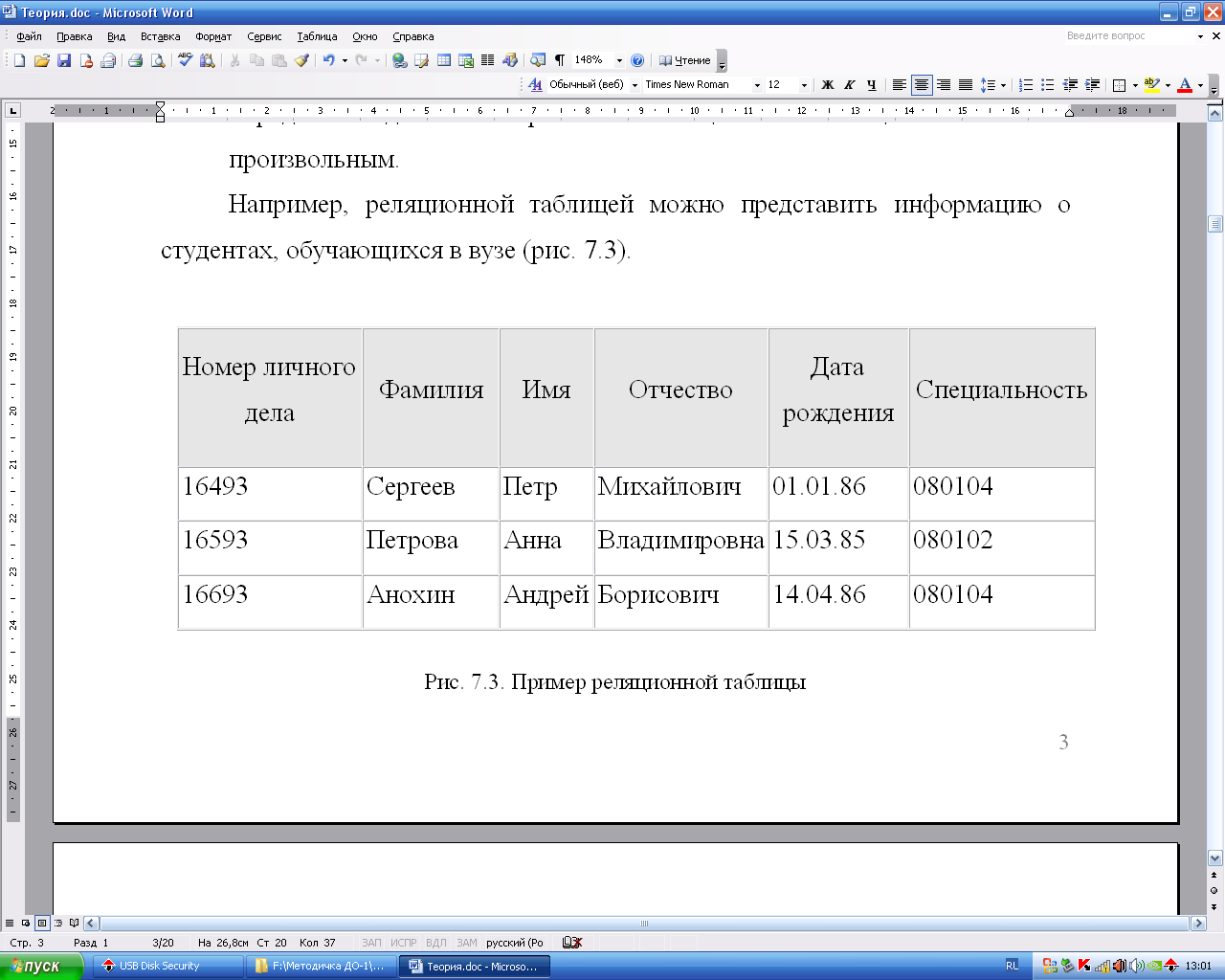 Рис. 2.7.2. Пример реляционной таблицы Объектами обработки реляционной БД являются следующие информационные единицы: поле, запись, таблица. Поле –элементарная единица логической организации данных, которая соответствует одному реквизиту информационного объекта (столбецреляционной таблицы). Запись–совокупность логически связанных полей (обобщеннаястрокареляционной таблицы).Экземпляр записи–отдельная реализация записи, содержащая конкретные значения ее полей (конкретная строка реляционной таблицы). Таблица – заданная структура полей, состоящая из конечного набора однотипных записей.
Рис. 2.7.2. Пример реляционной таблицы Объектами обработки реляционной БД являются следующие информационные единицы: поле, запись, таблица. Поле –элементарная единица логической организации данных, которая соответствует одному реквизиту информационного объекта (столбецреляционной таблицы). Запись–совокупность логически связанных полей (обобщеннаястрокареляционной таблицы).Экземпляр записи–отдельная реализация записи, содержащая конкретные значения ее полей (конкретная строка реляционной таблицы). Таблица – заданная структура полей, состоящая из конечного набора однотипных записей.
Основы систем управления базами данных
Основными функциями любой информационной системы являются хранение данных и их обработка. Под термином «данные» мы будем понимать любую информацию об объектах окружающего мира, представленную в формализованном виде, пригодном для ее передачи, хранения и обработки при помощи некоторого процесса. Для обеспечения процесса хранения и обработки данных средствами вычислительной техники во все современные информационные системы входит специальная программа, а точнее, комплекс программных средств, называемых системой управления базами данных (СУБД). Эта система обеспечивает создание, сопровождение 1 и использование специальных хранилищ данных – баз данных (БД), которые являются современной формой организации хранения и доступа к информации.
В данном разделе мы познакомимся с основными принципами организации данных, дадим классификацию баз данных по ряду признаков, рассмотрим особенности клиент/серверной архитектуры построения информационных систем. Далее мы перейдем к рассмотрению основ моделирования данных и характеристик реляционной модели организации данных, принятой в настоящее время на вооружение большинством фирм-разработчиков коммерческих версий СУБД. Завершающей частью данного раздела будет характеристика современных методов и средств проектирования баз данных.
2.1. Традиционный подход к организации данных
Как организовать хранение данных в компьютере, чтобы наилучшим образом, быстро и надежно извлекать и обрабатывать нужную информацию? Простейший подход состоит в разработке для отдельной прикладной задачи одной или нескольких компьютерных программ, называемых прикладными программами. Напомним, что программы, выполняемые под управлением операционной системы, в частности Windows, называют приложениями. Для каждого приложения во внешней памяти компьютера создается один или несколько файлов для размещения, хранения и извлечения из них информации о каком-нибудь элементе предметной области. Процедура размещения и извлечения информации в файле зависит от его типа, который в общем случае подразделяется на две категории:
- файл последовательного доступа;
- файл произвольного доступа.
Файл последовательного доступа представляет собой последовательность записей данных в виде строк произвольной длины, разделенных запятыми или специальными символами, обозначающими переход на новую строку. Особенностью данного типа файла является отсутствие возможности упорядочить хранимые записи, размещение и извлечение записей в такой файл производится построчно в определенной последовательности. Файл произвольного доступа состоит из записей фиксированной длины, которая указывается при его создании. Все записи в таком файле упорядочены, каждая имеет свой номер, что позволяет быстро переместиться на любую запись, минуя предыдущие.
К примеру, если рассматривать в качестве предметной области доменное производство (рис. 2.1), то фрагмент такой информационной системы будет содержать следующие приложения:
- приложение для мастера печи, осуществляющего выбор системы загрузки, управление тепловым режимом конкретной печи и т.п.;
- приложение для отдела снабжения, решающего задачи по бесперебойному обеспечению работы доменного цеха материалами и топливно-энергетическими ресурсами;
- приложение для главного технолога, решающего задачи по анализу технологии доменной плавки, например оптимальному распределению материалов и топливно-энергетических ресурсов между несколькими печами цеха;
- приложение для технического управления предприятием, решающего задачи управления технологией доменного производства, анализа перспективных решений, планирования работы цеха и т.п.
Каждое приложение (прикладная программа) использует для обработки данные, расположенные в одном или нескольких файлах. Чтобы приложение правильно считывало данные из файлов, последние должны быть организованы по определенным правилам, которые «понятны» приложению. Другими словами, при разработке прикладной программы необходимо продумать и реализовать хранение данных таким образом, чтобы осуществлять доступ к ним наиболее эффективным способом. Критерием эффективности в большинстве случаев является скорость доступа к данным, которая зависит от множества факторов, в частности типа накопителя, способа доступа к записям файла, размера файла и др. В этом случае говорят, что логика организации файлов данных встроена в само приложение, т.е. в код его программы.
Такой подход, который в литературе принято называть традиционным, был характерен для начальных этапов развития информационных систем, но может встречаться и сейчас, когда специалист в области, не связанной с вычислительной техникой непосредственно, создает свою персональную информационную систему, пользуясь известными ему инструментами. Каковы недостатки такой организации данных?
Избыточность данных. Некоторые элементы данных неизбежно используются во многих приложениях. Поэтому они записываются в несколько файлов, т.е. одни и те же данные хранятся в разных местах. Примером является файл данных, содержащий информацию о характеристиках шихтовых материалов (см. рис. 2.1). Такое положение называют избыточностью данных. Это, в свою очередь, делает проблематичным обеспечение непротиворечивости информации, поскольку избыточность данных требует наличия нескольких процедур ввода и своевременного обновления, как правило, разными пользователями.
Проблемы непротиворечивости данных. Одной из причин нарушения непротиворечивости данных является их избыточность, что связано, как уже отмечалось, с хранением одной и той же информации в нескольких местах. При появлении новой информации, необходимой пользователям различных структурных подразделений, ее надо ввести в разных местах. Зачастую по разным причинам выполнить это не удается или ввод осуществляется с искажениями. В результате об одном и том же объекте предметной области в разных местах хранится различная информация.
Ограниченная доступность данных. В современных условиях, когда исключительно важна оперативность управления, лицо с соответствующими правами доступа должно иметь возможность получить данные за приемлемый отрезок времени. Если же данные разбросаны по нескольким файлам, доступность данных ограничена.
Сложности в организации и управлении. Жесткая зависимость между данными и использующими их программами создает серьезные проблемы в ведении данных и делает использование их менее гибким. Разработчики прикладных программ, написанных, например, на языках программирования Basic, Pascal или С, размещают нужные им данные в файлах, организуя их наиболее удобным для себя образом с целью достижения максимальной эффективности работы программы (повышение скорости доступа к данным, оптимизация расположения данных во внешней памяти, реализация усиленных средств защиты данных и др.). Система программирования накладывает на структуру загрузочного модуля прикладной программы специфичную для этой системы логику обработки данных. Одни и те же данные могут иметь в разных приложениях совершенно разную организацию (разную длину и последовательность размещения записей, разные форматы одних и тех же полей и т.п.). Обобществить такие данные очень трудно. Например, любое изменение структуры или способа доступа к файлу данных, производимое одним из разработчиков, приводит к необходимости изменения другими разработчиками тех прикладных программ, которые используют записи этого файла. Кроме того, из-за избыточности данных в файлах трудно реализовать новые изменения данных во всей предметной области.
Дополнительные трудности создания информационных систем на базе файловых систем проявились в следующем:
- недостаточность средств защиты хранимых данных;
- низкопроизводительная работа в многопользовательской среде;
- отсутствие процедур восстановления данных после возникновения отказов;
- отсутствие средств манипулирования данными;
- высокая стоимость программирования и сопровождения;
- негибкость к изменениям и др.
Попытки интеграции, объединения данных до появления технологии систем баз данных наталкивались на ряд трудностей. Информационные системы ориентированы, главным образом, на хранение, выбор и модификацию постоянно существующей информации о предметной области. Понятно, что эта информация каким-то образом должна быть упорядочена, т.е. структурирована. Логическая структура информации зачастую очень сложна, и хотя структуры организации данных различны в разных информационных системах, между ними часто бывает много общего. Стремление выделить и обобщить общую часть информационных систем, ответственную за управление сложно структурированными данными, явилось, пожалуй, главной побудительной причиной создания систем управления базами данных (СУБД).
При подготовке материала использовались источники:
https://studfile.net/preview/7781992/page:2/
https://studfile.net/preview/4200565/
https://studfile.net/preview/9121951/