Использование функции оптического распознавания символов (OCR) в Adobe Acrobat Export PDF
Adobe Acrobat Export PDF — это онлайн-сервис Acrobat. С его помощью можно легко конвертировать файлы PDF в редактируемые документы Word, Excel и RTF (расширенный текстовый формат).
Сервис Adobe Acrobat Export PDF не позволяет редактировать файлы PDF. Для редактирования файлов PDF используйте Acrobat. Перейдите на страницу продукта Acrobat.
Adobe Acrobat Export PDF поддерживает оптическое распознавание символов (OCR) при конвертации файла PDF в форматы Word (.doc и .docx), Excel (.xlsx) и RTF (расширенный текстовый формат). OCR — это преобразование изображений текста (отсканированный текст) в редактируемые текстовые данные, поддерживающие возможности поиска, исправления и копирования.
При включенной функции OCR Adobe Acrobat Export PDF выполняет оптическое распознавание символов в файлах PDF, содержащих изображения, векторную графику, скрытый текст или любое сочетание этих элементов. Оптическое распознавание символов выполняется для файлов PDF, созданных из отсканированных документов. Кроме того, Adobe Acrobat Export PDF выполняет оптическое распознавание символов в тексте, который не удается интерпретировать из-за неправильной кодировки, заданной в исходном приложении.
Поддерживаемые языки
Adobe Acrobat Export PDF поддерживает OCR для текста на следующих языках.

По умолчанию функция OCR работает с языком, выбранным в диалоговом окне «Моя информация». Модуль OCR использует выбранный язык для обработки отсканированного текста. Выбор правильного языка повышает точность преобразования, так как модуль OCR использует словари для этого языка. Если кодировка языка отлична от латиницы (например, японский), то неверный выбор языковых параметров приведет к невозможности распознавания и преобразования текста с помощью модуля OCR.
Использование веб-интерфейса Acrobat Export PDF
Для включения функции OCR при преобразовании файла PDF в Adobe Acrobat Export PDF выполните следующие действия.
Выполните вход в веб-интерфейс Adobe Acrobat Export PDF и нажмите Выбрать файлы PDF для экспорта.
Нажмите Выбрать файлы на моем компьютере и найдите нужный файл PDF. Кроме того, можно перетащить файл на панель. Чтобы выбрать файл из Document Cloud, нажмите Document Cloud в области слева и выберите файл. ПРИМЕЧАНИЕ. Можно выбрать несколько файлов для экспорта.
4 способа распознать текст с ПДФ документа: на скане, фотографии или изображении

 5.0 Оценок: 3 (Ваша: )
5.0 Оценок: 3 (Ваша: )
✅ Главная 📚 Обучение Как распознать текст с PDF
Хотите распознать текст в электронном документе?
Воспользуйтесь программой PDF Commander!
PDF Commander — универсальный софт с функцией распознавания текста с ПДФ. Программа выбрана экспертами, которые протестировали эту возможность. Результаты обработки и инструкции найдете ниже в статье. Также доступны инструменты для редактирования: выделение цветом, добавление гиперссылок, размытие конфиденциальных данных и другие.

Технология OCR (optical character recognition) выполняет оптическое распознавание символов. С ее помощью книги и документация переводятся в электронный вид. Обработанный материал можно копировать и делать по нему поиск. Это значительно упрощает документооборот в организациях, работу образовательных учреждений и многих других сфер.
В статье расскажем, в каких случаях функция доступна OCR, а также поэтапно разберем, как распознать текст в ПДФ файле в приложении на ПК.
Ознакомьтесь с видеоуроком, чтобы узнать, как распознать текст в файле:

Как распознать текст в PDF файле?
Технология OCR полезна как для работы, так и для учебы. Копирование информации для конспекта из отсканированного учебника займет с ней 2-3 минуты — не придется перепечатывать страницы вручную. Существует несколько типов объектов, в которых получится распознать символы: сканы, фото и картинки. Есть выбор русского или английского языка. Также пользователю доступно внесение изменений в файл, например можно исправить ошибки (с помощью функций «Скрыть область» и «Текст»).
В документе после сканирования
Сканы старых книг и длинные отчеты — плохой материал для обработки из-за объема и выцветшей от времени бумаги. PDF Commander способен успешно справиться с распознаванием текста с ПДФ, но стоит учесть несколько советов, чтобы все точно получилось. Инструкция:
- 1.Отсканируйте бумаги или откройте готовый файл в программе PDF Commander (нажмите «Открыть PDF»). В верхнем меню на вкладке «Редактор» выберите «Распознать текст».
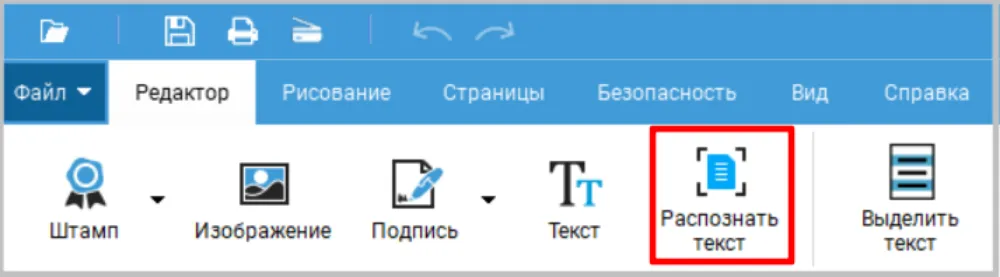
- 2. Если документ объемный, на обработку потребуется несколько минут. Можете указать страницы нужного раздела для ускорения процесса.
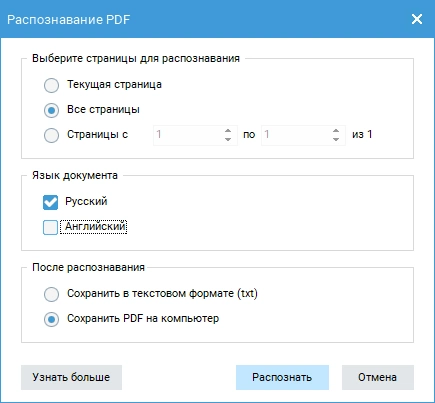
- 3. Выберите русский язык. Результат сохраните в ПДФ или как TXT-файл.
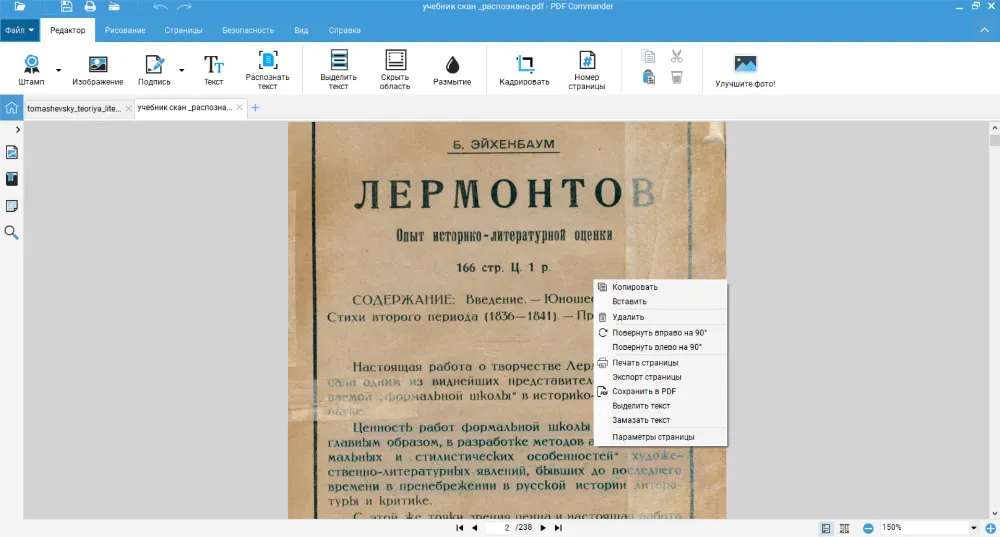
При подготовке учебных заданий важно не только распознать текст PDF, но и структурировать материал. Выделите цветом ключевые места конспекта, это поможет не потерять главную мысль научной статьи и лучше запомнить информацию.
По фотографии документа
Если требуется распознать надпись, но доступа к сканеру нет, то стоит воспользоваться телефоном или фотоаппаратом. Сделайте снимок или найдите изображение в памяти телефона. Также можно скачать его из вложений диалога в мессенджере. Для успешного определения всех слов очень важно, чтобы исходное изображение было четким и ярким.
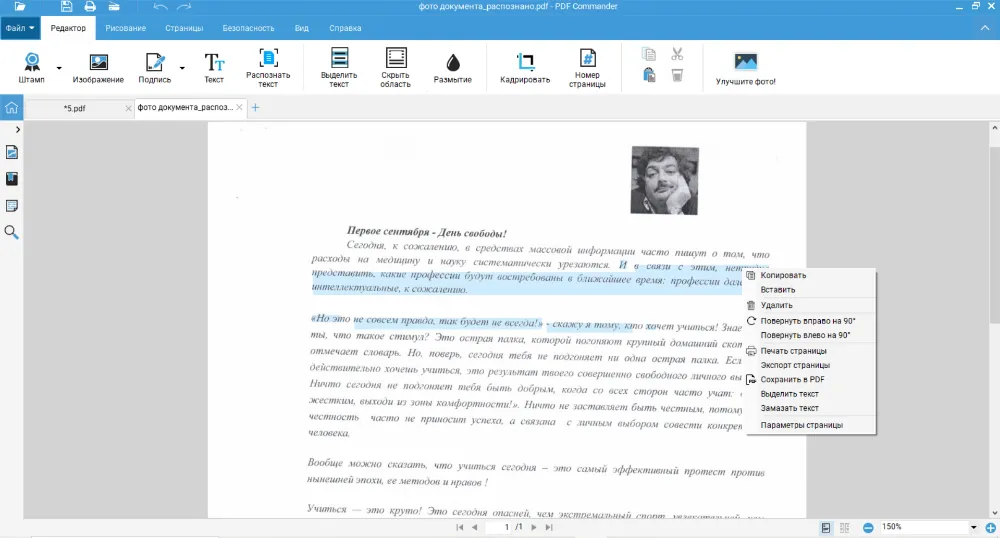
- 1. Нажмите «Открыть PDF», выберите изображение в любом формате: PNG, JPG, GIF и другие. Во вкладке «Редактор» кликните кнопку «Распознать текст».
- 2. Функция достаточно быстро найдет все символы. Выберите один из вариантов сохранения: новый ПДФ или в формате TXT.
Паспортные данные и номера карт можно убрать с помощью функций «Размытие» и «Скрыть область». Также можете поставить пароль на открытие и изменение. Они находятся в разделе «Безопасность».
Текст на изображении
В процессе обучения и на рабочих планерках принято сопровождать важную информацию презентациями, графиками, рисунками и схемами. Эти материалы стоит сохранять на случай, если они понадобятся в дальнейшем. Лучше всего для этого использовать технологию OCR, ведь с помощью нее можно быстро и удобно копировать надписи.
Функцией можно также воспользоваться в случае, если нужный учебник в интернете есть только в формате картинки. Не тратьте время на то, чтобы перепечатать текст — в программе можно конвертировать изображение в PDF и применить распознавание.
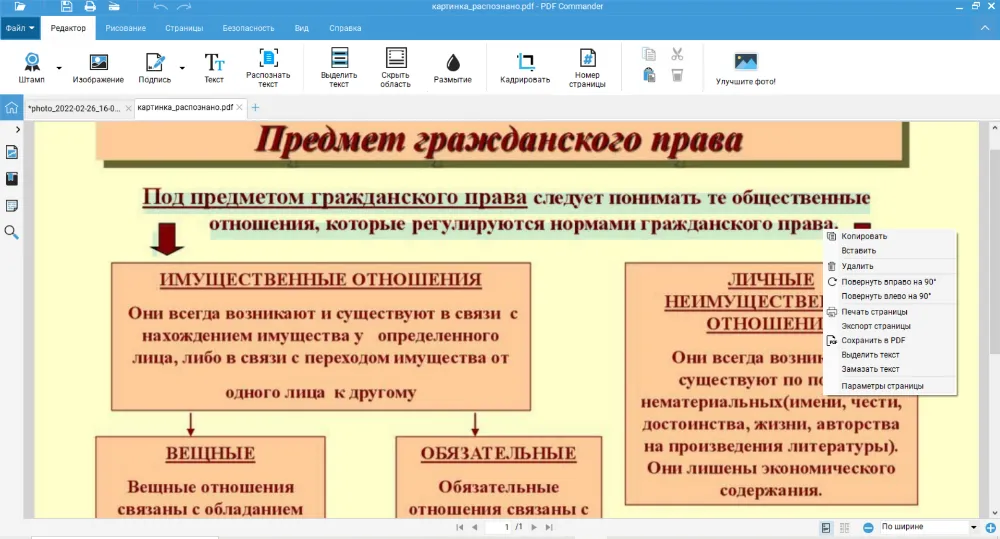
- 1. Откройте редактор и создайте новый документ. Софт работает со множеством графических форматов, поэтому предварительно конвертировать ничего не требуется. Если нужно распознать символы из картинок с презентации, то необходимо сначала подготовить скриншоты, а после загрузить их в PDF Commander.
- 2. На вкладке «Редактор» кликните «Распознать текст».
- 3. Немного подождите, пока программа найдет все символы. На слайдах,схемах и графиках может быть много информационных блоков с разным оформлением. Это привлекает внимание аудитории, но для программы определить, в каком порядке все следует — сложная задача. Выделяйте каждый элементов отдельно, чтобы расположить их в логичном порядке.
- 4. Сохраните документ в удобном формате.
Следует выбирать картинки в хорошем качестве. Если даже пользователь с трудом может прочитать информацию, то шанс успешного анализа сервисом невысок. Символы не должны сливаться с другими объектами. Также важно проверить, не накладываются ли элементы друг на друга.
Что делать, если файл на английском языке
Распознать текст с PDF будет удобно как для взаимодействия с рабочей документацией на иностранном языке, так и для обучения английскому. Функция позволяет быстро скопировать слово или выражение и найти перевод.
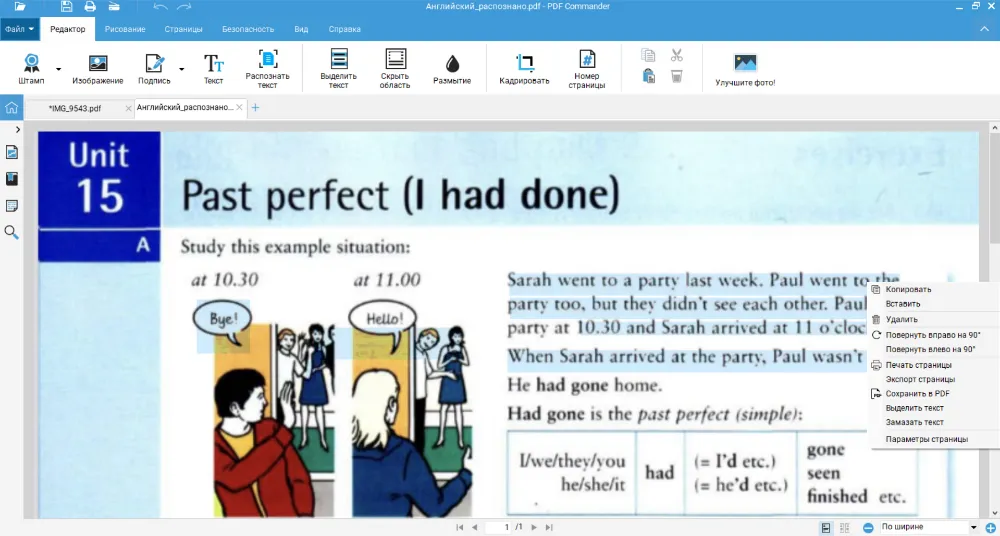
- 1. Нажмите «Открыть PDF» и выберите документ или изображение. Кликните по кнопке «Распознать текст» и перейдите к настройкам.
- 2. Обязательно отметьте английский как язык документа. Если обрабатываете учебное пособие, то не забудьте выбрать номера страниц, чтобы долго не ждать.
- 3. Останется сохранить итог. Преобразуйте его в TXT или создайте новый ПДФ.
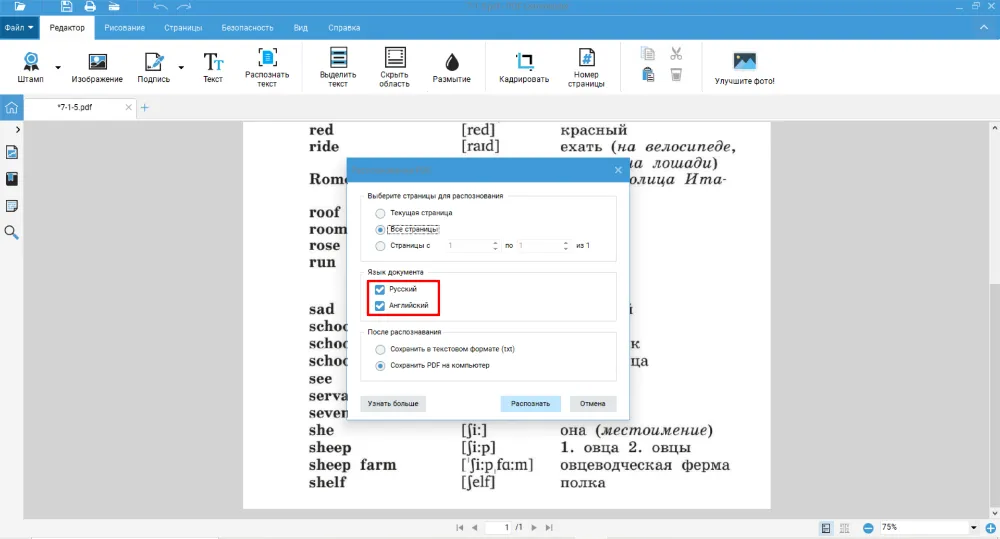
Можно выбрать оба языка — русский и английский. Например, если в учебнике есть словарь с переводом, при распознавании символов нужно учесть и это.
В профессиональной деятельности чаще всего приходится прибегать к использованию данной функции переводчикам. Если нужно адаптировать американский комикс для читателей из России, достаточно соединить сохраненный текст и страницы.
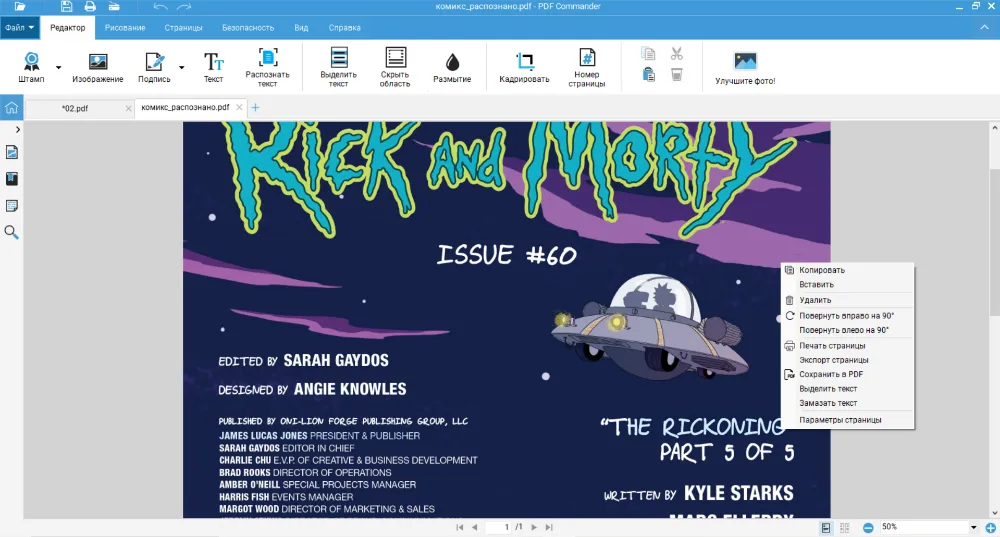
Также PDF Commander подойдет тем, кто хочет читать комиксы, которые только вышли и не получили перевода на русский. Иногда их можно скачать бесплатно в ПДФ формате. В программе легко приближать страницы и скрывать верхнюю панель. Для перемещения используйте инструмент «Рука».
Результаты тестирования
Редактор показал себя хорошо в обработке разных типов файлов. Даже в старом учебнике, который имеет повреждения, PDF Commander смог различить символы. На выцветших страницах и в проклеенных скотчем местах программа опознала все элементы.
Хотя в программе доступна обработка сложного для восприятия материала, лучше заранее подготовить изображения, провести обработку при необходимости. Слова должны хорошо читаться, не сливаться с другими элементами (таблицами, рисунками, схемами) и друг другом. Это снижает вероятность ошибки и упрощает работу.
Часто задаваемые вопросы
OCR распознает 100% текста?
Многое зависит от качества используемого материала. Труднее всего работать со сканами старых книг: в них выцветают страницы, появляются повреждения. Иногда во время сканирования появляются засветы, текст смазывается. При обработке таких объектов могут возникнуть неточности. Если использовать изображения в хорошем качестве, где символы четкие и не сливаются, проблем, как правило, не бывает.
Как исправить ошибки в PDF после распознавания текста?
После обработки с помощью OCR PDF файла результат сохраняется как новый документ, программа автоматически откроет его во втором окне. Используйте инструменты «Скрыть область» и «Текст», чтобы исправить ошибку.
Как защитить ПДФ документ от распознавания текста?
В программу PDF Commander добавлена специальная функция для ограничения доступа. Во вкладке «Безопасность» нажмите «Установить пароль». Доступ будет только у тех пользователей, которым вы его сообщите.
Как выполнить OCR для извлечения текстов из PDF [Полное руководство]

Последнее обновление 27 сентября 2022 г. by Тина Кларк Просто сделайте несколько снимков для презентации и хотите легко извлечь из них тексты, что вам делать? Оптическое распознавание PDF-файлов на основе изображений — это простой способ получить нужные файлы. Когда вам нужно превратить файл PDF в файл с возможностью поиска и редактирования, что является самым сложным для применения алгоритма OCR к файлам PDF? База данных языков должна быть правильным ответом. Вы можете обнаружить, что функция OCR работает для одного языка, но не для другого. Просто узнайте больше о 6 часто используемых Распознавание PDF решения и выберите подходящий в соответствии с вашими требованиями.
- Часть 1. Простой способ конвертировать PDF в текст с помощью PDF OCR
- Часть 2: 5 решений OCR PDF для извлечения слов из PDF
Часть 1. Простой способ конвертировать PDF в текст с помощью PDF OCR
PDFelement это универсальный PDF-редактор для выполнения алгоритма OCR, который поддерживает 23 различных языка с передовыми технологиями. Он выполняет решение OCR PDF, чтобы сохранить тот же макет, что и исходный контент, а текст будет доступен для поиска и выбора. Он также предоставляет буквально тысячи функций, которые упрощают понимание идей, связанных с PDF, и позволяют применять их в самых разных ситуациях.
1. Применяйте алгоритмы OCR как к отсканированным PDF-файлам, так и к PDF-файлам на основе изображений.
2. Извлекайте нужные тексты из файлов PDF на более чем 20 языках.
3. Преобразование на основе изображений PDF к Слову, Excel, PPT и другие форматы файлов.
4. Сохраняйте исходное содержимое PDF-файла, чтобы сделать его доступным для поиска и редактирования.
Шаг 1: импортируйте PDF-файлы на основе изображений или отсканированные PDF-файлы в PDFelement. Вы также можете использовать PDFelement iOS для захвата PDF-файлов с помощью камеры вашего iPhone или iPad. Существуют различные стратегии, которые можно использовать для обеспечения отображения изображения.

Шаг 2: После того, как вы импортировали нужный PDF-файл, вы можете найти Выполнить OCR кнопку для извлечения нужных текстов. Более того, нажмите кнопку OCR кнопку, чтобы выбрать режим OCR, и нажмите кнопку Изменить язык кнопку, чтобы выбрать другой язык для содержимого изображения.

Шаг 3: решение OCR PDF распознает текст на вашем изображении, что позволит вам изменить текст. Кроме того, он сохраняет тот же макет, что и ваш исходный PDF-контент, и текст будет доступен для поиска и выбора. После этого вы можете внести некоторые изменения в тексты PDF.
Шаг 4: после преобразования PDF-файла на основе изображения с помощью алгоритма OCR будет создан полностью редактируемый PDF-файл. Чтобы мгновенно изменить текст, выберите значок Редактировать в раскрывающемся меню в верхнем левом углу экрана перед сохранением.

Win Скачать Mac Скачать
Часть 2: 5 решений OCR PDF для извлечения слов из PDF
Sejda — онлайн-решение для оптического распознавания символов PDF
Sejda это онлайн-решение OCR PDF для извлечения текста из PDF-файлов. Он поставляется с настольным клиентом для Windows, macOS и Linux, а также с программой OCR на основе браузера для использования в Интернете. Вы можете получить документ PDF с возможностью поиска, где невидимый текст должен быть наложен на исходные изображения в правильных местах.
1. Обеспечьте простой и быстрый способ применения некоторых основных функций OCR.
2. Бесплатный сервис для PDF-файлов до 10 страниц или 50 МБ и 3 задач в час.
3. Поддерживайте нерегулируемые сервисы и вольны делать то, что хотите редактировать.
1. Ограниченные задачи в течение дня и ограниченный размер файла до 50 МБ.
2. Необходимо оптимизировать яркость и контрастность PDF перед распознаванием PDF.

Omni Page — OCR PDF на 120 языках
Омни-страница позволяет быстро и эффективно использовать возможности OCR. Алгоритм OCR PDF работает не только с PDF, но и BMP и GIF-файлы изображений легко для более чем 120 языков. Кроме того, он также предоставляет расширенный алгоритм для сохранения исходного контента, включая столбцы, таблицы, маркеры, графику и т. д.
1. Обеспечьте сохранение исходного макета и общее результирующее форматирование.
2. Усовершенствованные механизмы OCR обеспечивают превосходную точность преобразования PDF.
3. Включите расширенный облачный коннектор Nuance Cloud Connector на базе Gladinet.
1. Рекламное ПО загружается в систему при использовании функции OCR.
2. Пользовательский интерфейс программы не такой интуитивно понятный, как у других программ.

Microsoft Word — встроенный OCR PDF для Office
Нет необходимости загружать и устанавливать отдельную программу OCR, если вы уже подписаны на Microsoft Office. Для преобразования PDF-файлов и фотографий в текст в Microsoft интегрирована технология оптического распознавания символов PDF, включая Microsoft Word, Excel и OneNote. Все, что вам нужно сделать, это открыть файл PDF в Word, чтобы преобразовать его в редактируемый файл.
1. Преобразуйте текст в формате PDF на основе отсканированного изображения в документ Word.
2. Скопируйте текст с изображений и распечаток файлов с помощью OCR в OneNote.
3. Добавляйте текст непосредственно в свои заметки после извлечения таблиц в Excel/Word.
1. Требовать подписки на Office 365 для извлечения таблиц в онлайн-версии.
2. Невозможно сохранить исходные PDF-таблицы, маркеры, графику и т. д.

Tesseract — мощный движок OCR PDF
Тессеракт — еще один профессиональный пакет OCR PDF с открытым исходным кодом. Пользуется высоким уровнем уважения среди профессионалов бизнеса. Вы можете использовать его для преобразования отсканированных бумажных документов в виде файлов PDF или изображений в редактируемые данные с возможностью поиска. Обычно это включает в себя сканер, который преобразует документ во множество разных цветов, известный как растровое изображение.
1. Предоставьте бесплатное решение OCR PDF для Windows, Mac и Linux бесплатно.
2. Внесите некоторые базовые изменения в программу, чтобы сделать ее более многоязычной.
3. Работайте с частью документа, а не со всем документом.
1. Используйте интерфейс командной строки, это не простая программа.
2. Оптическое распознавание символов менее точное, чем думают его разработчики.

Fine Reader — решение для оптического распознавания символов PDF на основе искусственного интеллекта
Прекрасный читатель является одним из самых опытных сервисов оптического распознавания символов PDF. Он широко известен как одно из приложений на основе ИИ, которое способствовало общему улучшению качества жизни пользователей. Он предоставляет как онлайн, так и автономные функции OCR для быстрого извлечения текста из отсканированных изображений в формат TXT на вашем устройстве без подключения к Интернету.
1. Поддержка 192 различных языков и проверка орфографии для 47.
2. Определить размер документа в AR для нестандартных документов и дальнейшей печати.
3. Преобразуйте в другой формат и сохраните исходное форматирование документа.
1. Невозможно эффективно работать из-за медлительности программы.
2. Эта программа не может выполнять распознавание документов TXT напрямую.

Заключение
Вот некоторые популярные решения OCR PDF, доступные на рынке. Если вам нужно преобразовать какой-либо файл PDF на основе изображения или отсканированный файл в формат PDF с возможностью поиска и редактирования, вы можете узнать больше о специальных функциях решений OCR PDF, особенно о поддерживаемых языках. PDFelement — это один из лучших способов гарантировать, что при сканировании и оцифровке документов используется самое лучшее программное обеспечение для оптического распознавания символов, написанное от руки.
Вы можете быть заинтересованы
- Бесплатные редакторы PDF для Windows и Mac — вот окончательный обзор, который вы должны знать
- PDF-принтер — 6 эффективных методов печати PDF-файла на разных устройствах
- Ищете лучший конвертер PDF в Word? Вот ваша ссылка
При подготовке материала использовались источники:
https://helpx.adobe.com/ru/document-cloud/help/using-ocr-exportpdf.html
https://pdf-editor.su/raspoznat-tekst-v-pdf.php
https://ru.widsmob.com/articles/ocr-pdf.html