AntConc
![]()
![]()
A freeware corpus analysis toolkit for concordancing and text analysis.
Downloads:
- Windows (Installer) (4.2.3) [Recommended]
- Windows (Portable) (4.2.3)
- MacOS 10/11-Intel (4.2.3)
[Catalina or newer] - MacOS 10/11-Silcon (4.2.3)
[BigSur or newer] - Linux (Portable) (4.2.3)
AntConc 3x series
PayPal Donations and Patreon Supporters:
Click one of the following if you want to make a small donation to support the future development of this tool.
Older Versions
Frequent asked questions (FAQ)
- What is the difference between the Windows-Installer and Windows-Portable versions?
- The Windows-Installer version will place the AntConc software in a safe location on your machine and put links to the software in the Start menu and on your desktop (if you want). This is the most common way to get software onto your computer. However, in cases where you are not allowed to install software on the computer (e.g. in a school environment) or when you want to put the software on a portable device like a USB stick, the Windows-Portable version is needed. In this version, all files are stored in a single folder. Open the folder and double click on the AntConc.exe to start. These packaging options were newly introduced with the release of AntConc 4.0.
- How do I get AntConc to work on a Apple Macintosh computer?
- AntConc should work with the latest version of Apple’s operating system. Double click the AntConc.dmg icon and follow the instructions to put the software into the Applications folder on your computer. You can then launch the software by double-clicking the icon in the Applications folder or from the Launchpad. This packaging option was newly introduced with the release of AntConc 4
- Can I use AntConc on a mobile device (e.g. iPhone, Android phone, iPad, or Chromebook)?
- No. AntConc can only run on desktop computers.
- How can I search for a question mark (or other wildcard characters) in my corpus?
- The question mark (?) is a wildcard character in AntConc meaning «any one character». To search for an actual question mark or any other wildcard character, just escape the character (e.g. \?) in the search query box. Note that you need to add these characters to the token definition when creating your corpus to be able to search for them later.
- When creating my own corpus, I get the following error: «Error: UnicodeDecodeError: ‘utf-8’ codec can’t decode byte XXX in position YYY: invalid start byte». What should I do?
- This error is telling you that the file is not properly encoded in the default UTF-8 encoding used by AntConc and so it cannot be read. To address this problem, either resave your file using the UTF-8 encoding (recommended) or change the encoding setting of AntConc to match the encoding of the file (assuming you know what encoding your file is saved in). Many users don’t know what encoding they are using which is why I recommend that the files are resaved with the UTF-8 encoding. You should be able to set the encoding in any standard text editor, e.g. NotePad or NotePad++.
User Support
Latest Help files
- YouTube Tutorials (by Laurence Anthony)
- 10-part series (Version 4.2)
- 11-part series (Version 3.4.0)
- 10-part series (Version 3.2.4)
- 6-part series (Version 3.2.0)
- 8-part series (Version 3.2.0)
- 13-part series (English) (Version 3.5.7)
- 13-part series (Urdu/Hindi)(Version 3.5.7)
- Getting Started (Version 3.2.0)
- Concordance Tool — Basic Features (Version 3.2.0)
- Guide by Warren Tang (Hiroshima University, Japan)
- AntConc 3.2.1 Tutorial (in English) Latest version available here.
- AntConc 3.2.2 Tutorial (in Japanese)
- AntConc 3.5.8 Tutorial
- AntConc3.3.5 (in Arabic) by Ahmad Haider (University of Canterbury, New Zealand
- AntConc3.2.1 (in Chinese) by Xiong Qing’an (University of Electronic Science and Technology of China, Chengdu, China)
- AntConc3.1.0 (in German) by Regine Muller
- AntConc3.2.4 (in Korean) by Dr CK Jung (Centre for Corpus Research, Yonsei University, Korea)
- AntConc3.4.4 (in Portuguese) by Laboratory of New Technologies in International Relations — LANTRI (Julia S Borba Gonçalves)
- AntConc3.4.4 (in Spanish) by Jesús Aparicio Boussif (Universidad de Córdoba, España)
Common Statistics Used In Corpus Linguistics
- The following document lists common statistics that are used in corpus linguistics focusing on those that appear in AntConc. The document is largely based on an unpublished paper written by Andrew Hardie of Lancaster University in 2014.
- Anthony, L. (2023). Common Statistics Used In Corpus Linguistics. Available at https://laurenceanthony.net/resources/statistics/common_statistics_used_in_corpus_linguistics.pdf.
Development Road Map
My current tentative plans.
- Nothing at present.
- Improve tag handling (XML/Part-Of-Speech/. )
- Your suggestions come here.
Citing/Referencing AntConc
Use the following method to cite/reference AntConc according to the APA style guide:
- Anthony, L. (YEAR OF RELEASE). AntConc (Version VERSION NUMBER) [Computer Software]. Tokyo, Japan: Waseda University. Available from https://www.laurenceanthony.net/software
For example if you download AntConc 4.2.3, which was released in 2023, you would cite/reference it as follows:
- Anthony, L. (2023). AntConc (Version 4.2.3) [Computer Software]. Tokyo, Japan: Waseda University. Available from https://www.laurenceanthony.net/software
Word frequency lists
- British National Corpus (BNC) frequency lists.
- BNC word frequency lists — written, spoken, combined (lowercase)
- BE06 and AME06 word frequency list (lowercase). Developed by Paul Baker. For more information on the design of the corpora behind these lists, see Paul Baker’s homepage.
- Brown Corpus word frequency list (lowercase)
- Brown Corpus word frequency list (mixed case)
AntConc
Корпус-менеджер AntConc разработчика Dr. Laurence Anthony предназначен для обработки корпусов первого порядка. С помощью данной программы можно производить поиск и подсчет различных элементов текста, анализировать частотность и контекст употребления словоформ, словосочетаний и морфем, сравнивать употребительность словоформ в разных текстах.
Отсутствие морфологического анализатора частично компенсируется возможностью подключения пользовательского списка лемм. Программа может быть использована для получения привязанных к заданной предметной области словарных минимумов, списков устойчивых сочетаний (в том числе терминологических), выборок к тематическим группам слов.
Использование AntConc
Программа AntConc не требует инсталляции, достаточно загрузить программу с официального сайта в зависимости от операционной системы: Windows, Linux или Mac OS и запустить её:
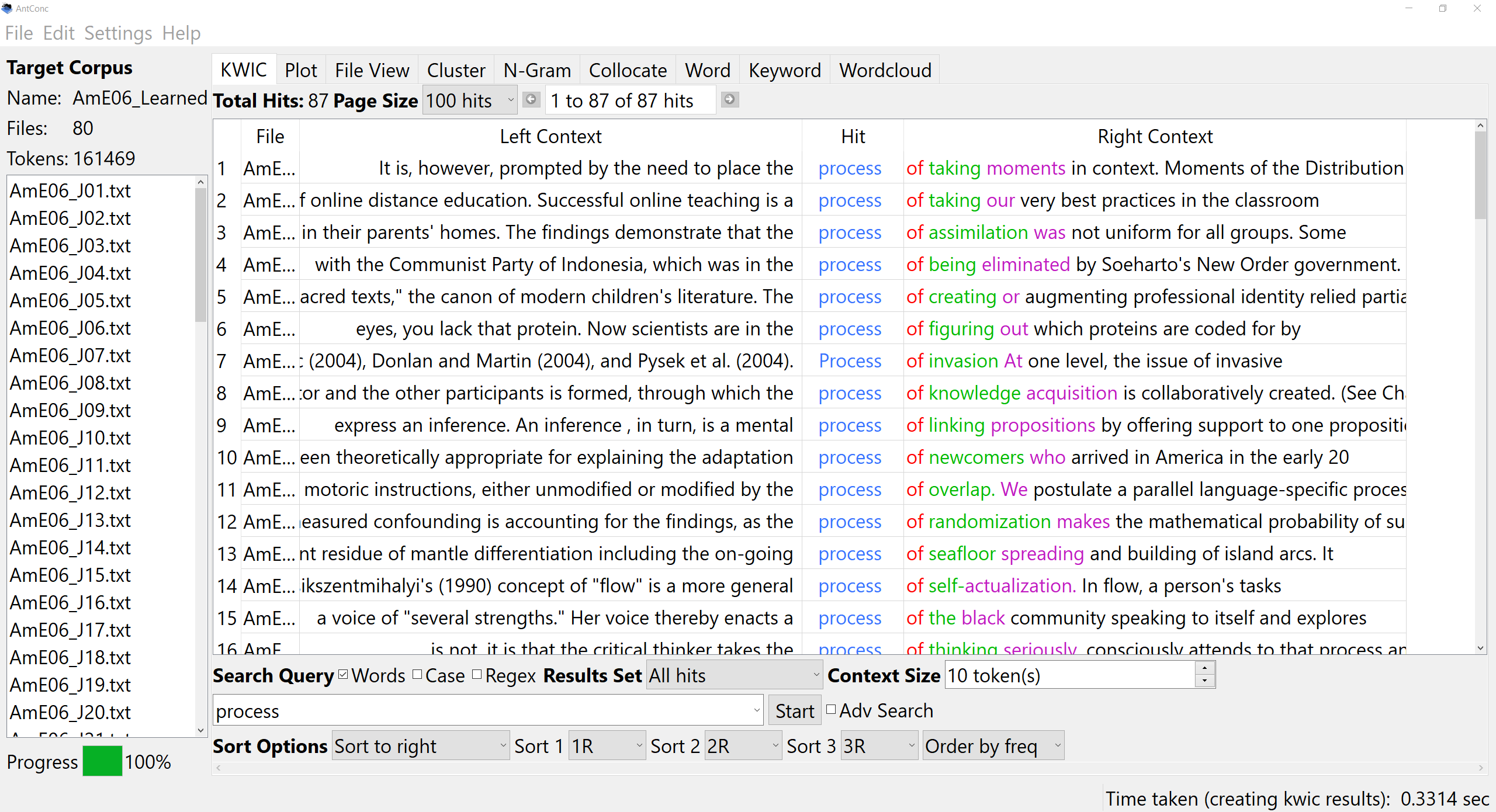
Рассмотрим работу корпус-менеджера AntConc на примере опубликованных текстов произведений Ивана Белых. Для этого файл сохраним в тексте: belykh.txt.
Открывем файл belykh.txt из верхнего левого меню File / Open file(s). Название файла появится в левом окне (под фразой «Corpus Files»).
Открываем во второй сверху строке меню кнопку «Word List» (вторяя слева) и нажимаем кнопку «Start» (внизу ближе к левому краю). Программа выстроит все словоформы текста в порядке частотности. Можно сортировать и по другим критериям. Если вместо «Sort by Freq» (в самом низу) выбрать «Sort by Word», произойдёт сортировка по алфавиту, если выбрать «Sort by Word End», сортировка пойдёт по концу слов. Ели к тому же поставим галочку между фразами «Sort by» и «Invert Order», то сортировка пойдёт в обратном порядке — от редких слов к частым или от я до а.
Можно кликнуть из списка любое слово, начнётся его автоматический поиск в окне Concordance. Если открыто окно Concordance, искомое слово можно ввести в окошко, находящееся между кнопкой «Start» и фразой «Search Term» и нажать «Start». Будет происходить поиск данного слова в контекстах. Если убрать галочку над тем же окошком между словами «Search Term» и «Words», можно будет искать не только конкретную форму слова, но и похожие формы напр. пишем пукт — выйдет пукта, пуктіс, пукты и т. п..
С помощю данной программы, в частности, нами была собрана большая часть примеров для демонстранционной словарной статьи ПОН из массива комиязычных электронных текстов (более 2 млн. словоупотреблений):
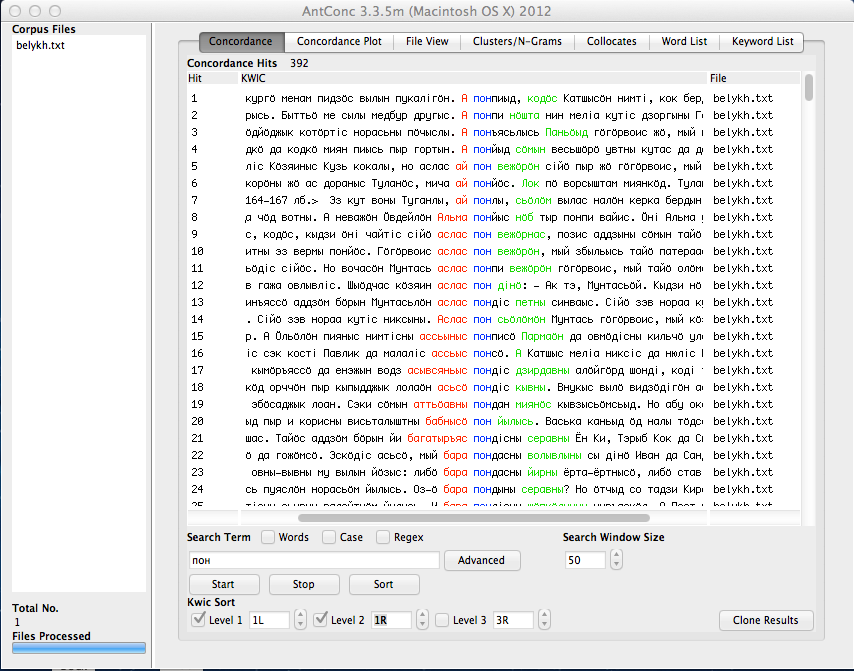
Для того, что слова с дефисом воспринимались в поиске как за одно слово, поставьте галочки:
В свободном доступе также один коми текст и 10 удмуртских текстов, предназначенных для начального этапа освоения работы с программой AntConc.
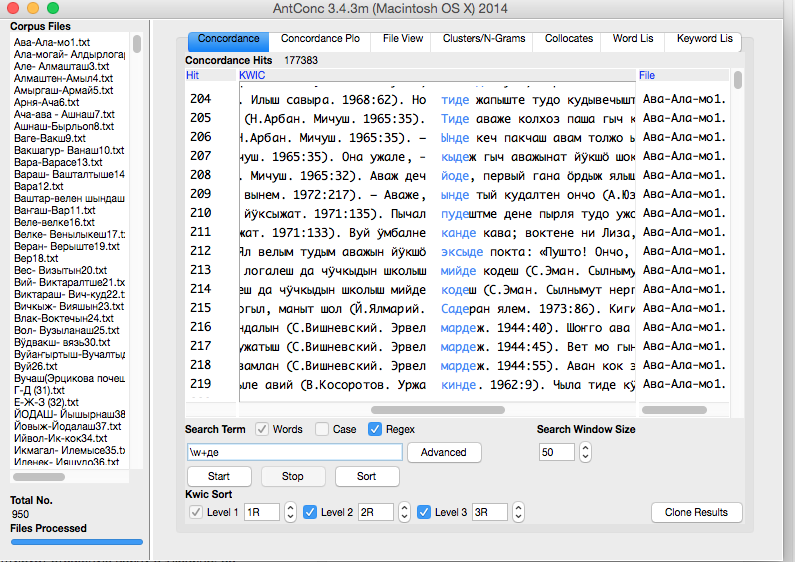
Использование регулярных выражений
Пример использования регулярного выражения «\w+де«:
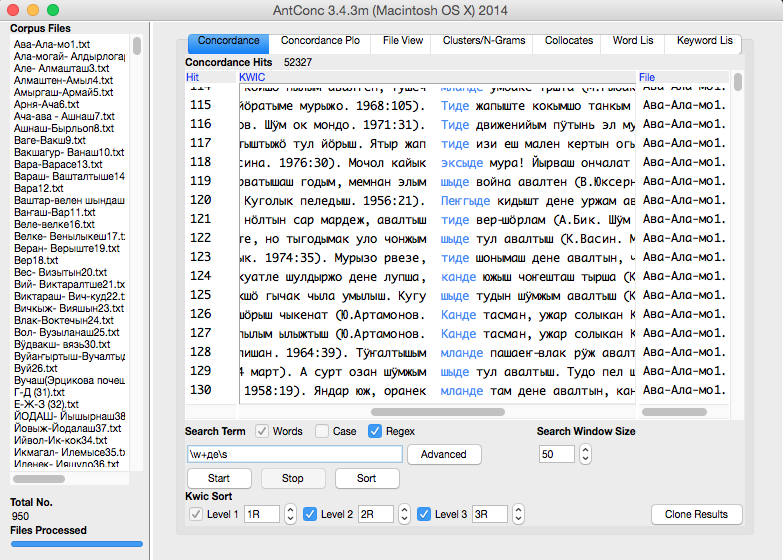
Пример использования регулярного выражения «\w+де\s» (все слова, которые заканчиваются на —де, далее пробел):
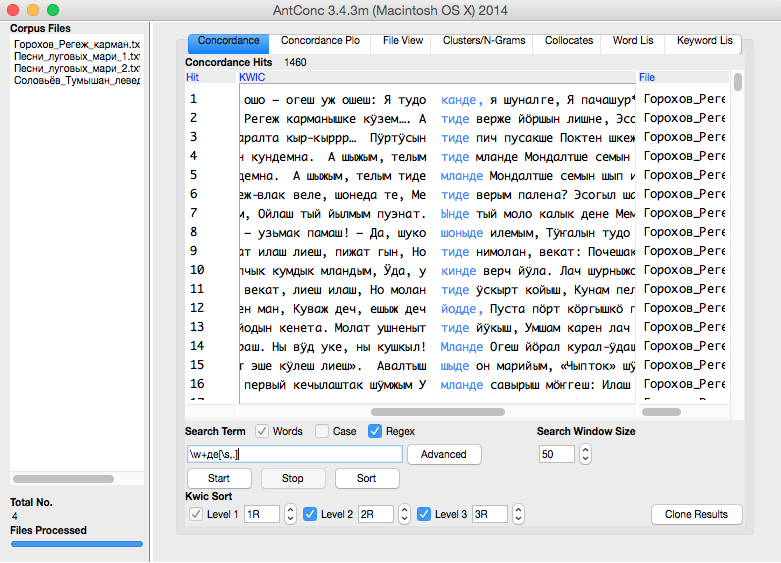
Пример использования регулярного выражения «\w+де[\s,.]» (все слова, которые заканчиваются на —де, далее пробел, запятая или точка):
Видеоурок от разработчика
Ссылки
- Официальный сайт программы
- Мастер-класс по AntConc от Лоренса Энтони
- Удмуртско-русский электронный словарь
- Станкевич,А.Ю. Поиск контекстов и оценка их типичности средствами AntConc
- Регулярные выражения, пособие для новичков. Часть 1
- Введение в регулярные выражения. Синтаксис
lingdata
Чтобы определить характерные для некоторого корпуса слова, мы должны сравнить их частоты в данном корпусе с частотами в другом корпусе — reference corpus.
- Загрузите SynTagRus в качестве reference corpus:
Settings > Tool Preferences > Keyword List
Use raw files – Add files
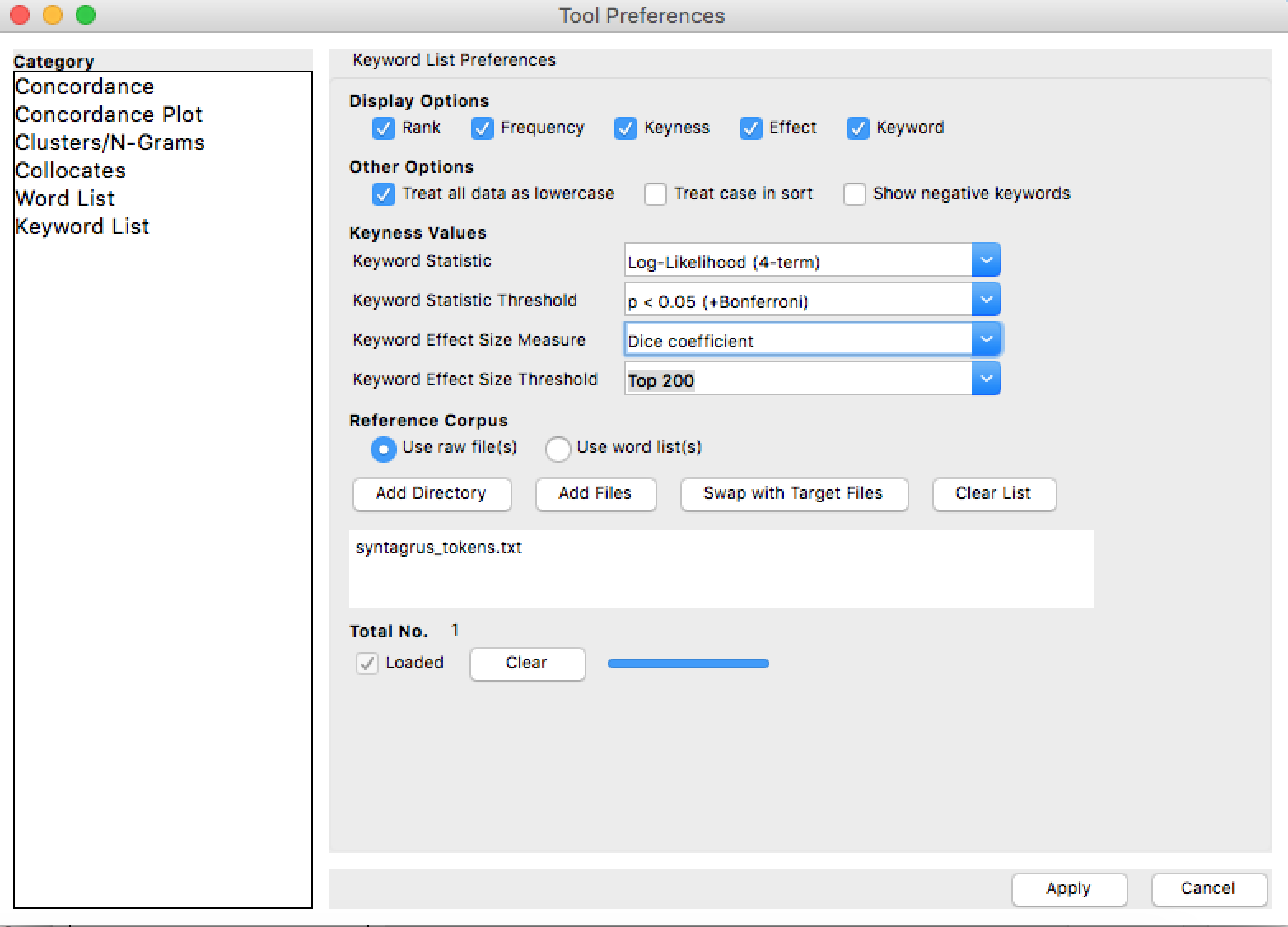
- Там же в настройках установите Log-Likelyhood (4-term) в качестве статистической метрики определения keyness и Длину списка в 1000 слов (Keyword Effect Size Threshold). – Apply
- Перейдите на вкладку Keyword List > Start Для новых файлов AntConc начнет генерацию словника (выдаст предупреждение jump to Word List). В результате на вкладке Keyword List появится список ключевых слов, отсортированный по убыванию метрики Keyness (Log-Likelyhood).
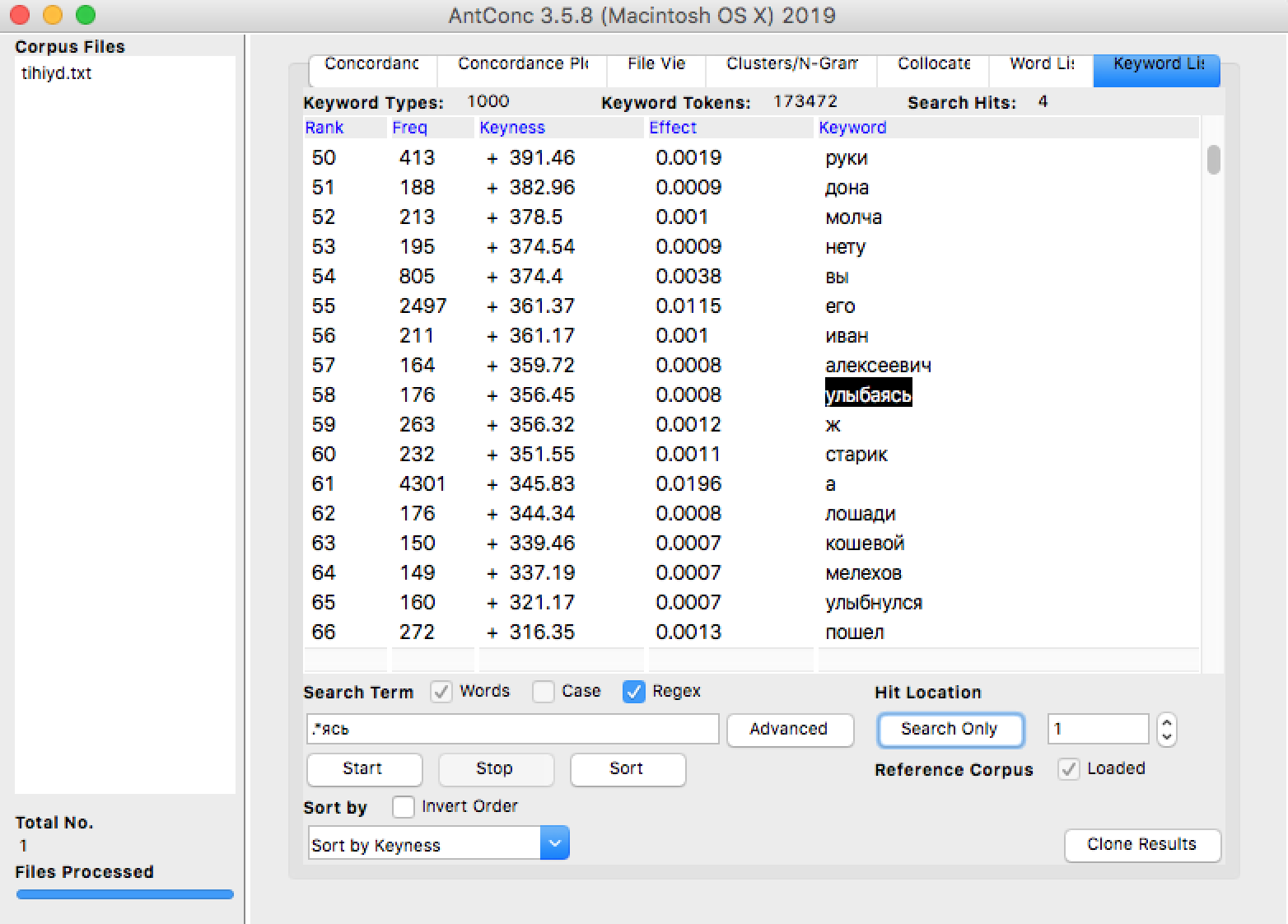
- Чтобы найти интересующее слово в этом списке, введите его в поле Search Term и нажмите кнопку Search Only (не Start!). Кликнув на слово в списке, можно перейти к конкордансу.
Частотные списки лемм и списки ключевых слов (леммы)
Чтобы построить частотный список лемм, ваш корпус должен быть лемматизирован (reference corpus, естественно, тоже). Мы будем использовать версии корпусов с подстановкой вместо токена метки леммы и части речи (в формате lemma_POS).
Коллокаты
Во вкладке Collocates укажите слово, сочетаемость которого вы хотите изучить. Справа укажите контекстное окно поиска коллокатов (например, 0 слов слева, 2 слова справа — 2R) и частотный порог (Min. Collocate Frequency). Start!
Списки коллокатов можно сортировать по абсолютной частоте, метрике коллокационной связи (Stat) и алфавиту.
В Settings > Tool Preferences > Collocates можно выбрать метрики MI, Log-Likelihood, T-Score.- T-Score — самая консервативная метрика, при ранжировании по ней уменьшается частотный ранг самых частотных слов корпуса и несколько увеличивается частотный ранг редких слов, но в целом ранги по абсолютной частоте и по T-Score похожи.
- MI (Mutual Information) — напротив, поднимает очень высоко в рейтинге слова, которые редко встречаются в корпусе в целом. Поэтому рекомендуют использовать эту метрику вместе с порогом отсечения очень редких слов.
- Log-Likelihood (LL-score, G2) — ближе к T-Score и больше понижает в рейтиге высокочастотные слова. Превосходит T-Score по соотношению точность/полнота, как показывает ряд исследований для английского языка.
В целом, идеальной метрики для поиска коллокатов не существует. Для разных языков, корпусов разного размера и жанра, типа коллокаций та или иная метрика может быть лучше или хуже.
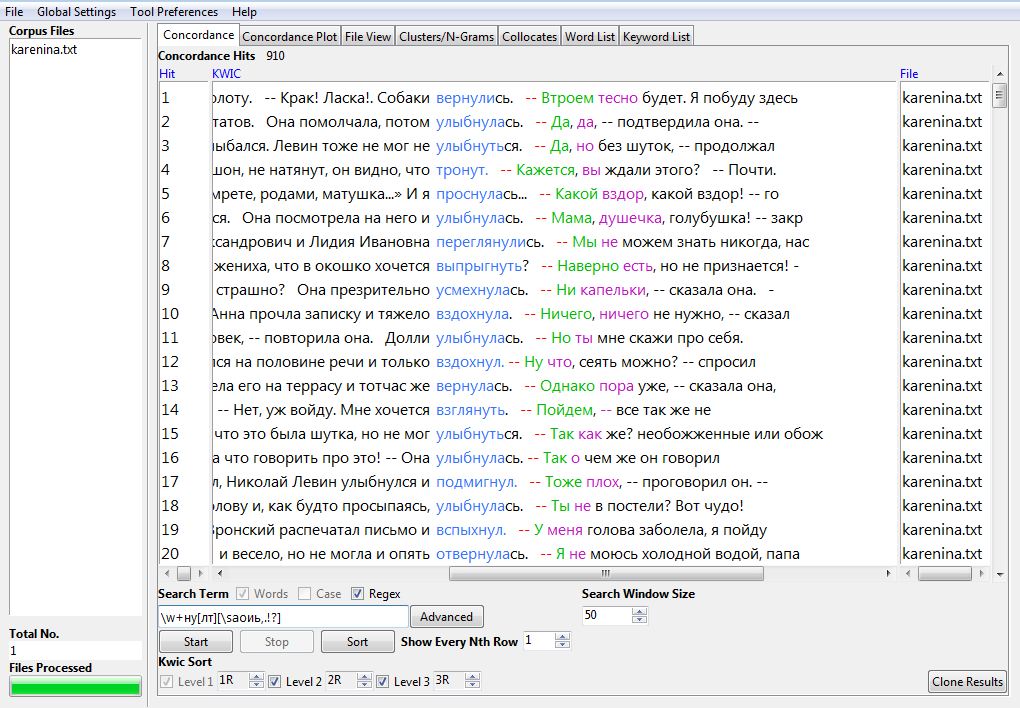
Поиск с использованием регулярных выражений
- Конкордансы и частотные списки можно строить с использованием Regex в Search Term. Например, \w+ну найдет любое слово, содержащее —ну, но не частицу ну. Вот так я предполагаю найти все глаголы на -ну-.

э+ (второй символ — плюсик, третий — пробел) позволит найти э, ээ, эээ (AntConc по умолчанию считает пробел маркером конца слова).
Материал для работы на семинаре
Война и Мир, т. 1: plain text
LiveCorpus 2021:
tokens: см. файлы livecorpus2021-text-1.txt … livecorpus2021-text-10.txt в архиве по ссылке выше. lemma_POS: см. livecorpus2021_lemma_pos.1.txt там же.Полезное
- Руководство по AntConc (на английском)
- Видео-тьюториал от автора
- Тьюториал для семинара
- Формулы и оценка коллокационных мер
Дополнительные материалы
Voyant Tools
Еще одно полезное онлайн-приложение, которое используется гуманитариями — Voyant Tools.
- Изучить основные возможности инструмента можно на примере романов Дж. Остин > Open > Choose a corpus > Austen’s Novels
- Voyant Tools умеет строить облака слов (для всего корпуса и отдельных документов)
- показывает распределение частоты слов в документах
- показывает свойства документов, такие как длина в словах, среднее количество слов в предложении и т. д. пример
- вернувшись на исходную страницу, вы можете загрузить и исследовать свой пользовательский корпус

- Справка по Voyant Tools
This project is maintained by olesar
Hosted on GitHub Pages — Theme by orderedlist
При подготовке материала использовались источники:
https://laurenceanthony.net/software/antconc/
http://wiki.fu-lab.ru/index.php/AntConc
https://olesar.github.io/lingdata/practicum-antconc.html