Fruitful and Fun
Build data analysis workflows visually, with a large, diverse toolbox.
Updates in the dask project, integrating machine learning methods and enhancing efficiency in a data preprocessor. Read more >
One thousand Slovenian students took part in a data mining challenge Read more >
Orange speaks Slovenian! Read more >
Interactive Data Visualization
Perform simple data analysis with clever data visualization. Explore statistical distributions, box plots and scatter plots, or dive deeper with decision trees, hierarchical clustering, heatmaps, MDS and linear projections. Even your multidimensional data can become sensible in 2D, especially with clever attribute ranking and selections.
Learn More
Visual Programming
Interactive data exploration for rapid qualitative analysis with clean visualizations. Graphic user interface allows you to focus on exploratory data analysis instead of coding, while clever defaults make fast prototyping of a data analysis workflow extremely easy. Place widgets on the canvas, connect them, load your datasets and harvest the insight!
Learn More
Watch Video
Teachers and Students Love It
When teaching data mining, we like to illustrate rather than only explain. And Orange is great at that. Used at schools, universities and in professional training courses across the world, Orange supports hands-on training and visual illustrations of concepts from data science. There are even widgets that were especially designed for teaching.
Learn More
Add-ons Extend Functionality
Use various add-ons available within Orange to mine data from external data sources, perform natural language processing and text mining, conduct network analysis, infer frequent itemset and do association rules mining. Additionally, bioinformaticians and molecular biologists can use Orange to rank genes by their differential expression and perform enrichment analysis.
Watch Video
Single Cell
Ferenc Borondics, Ph.D.
Principal beamline scientist at SMIS
SOLEIL synchrotron, France
«The scientific community is in need of tools that allow easy construction of workflows and visualizations and are capable of analyzing large amounts of data. Orange is a powerful platform to perform data analysis and visualization, see data flow and become more productive. It provides a clean, open source platform and the possibility to add further functionality for all fields of science.»
Francesca Vitali, Ph.D.
Research Assistant Professor
Center for Biomedical Informatics & Biostatistics, The University of Arizona
«I teach Orange workshops monthly to a diverse audience, from undergrad students to expert researchers. Orange is very intuitive, and, by the end of the workshop, the participants are able to perform complex data visualization and basic machine learning analyses. Most of our attendees have been able to incorporate this tool in their research practice.»
Gad Shaulsky, Ph.D.
Molecular biologist and Director of Graduate Studies
Baylor College of Medicine, Houston, USA
«My laboratory produces large amounts of data from RNA-seq, ChIP-seq and genome resequencing experiments. Orange allows me to analyze my data even though I don’t know how to program. It also allows me to communicate with my collaborators, who are experts in data mining, and with my colleagues and trainees.»
Интеллектуальный анализ данных — используем Orange

Orange — это инструмент для визуализации и анализа данных с открытым исходным кодом. Orange разрабатывается в лаборатории биоинформатики на факультете компьютерных и информационных наук Университета Любляны, Словения, вместе с сообществом открытого исходного кода.
Orange — это библиотека Python. Интеллектуальный анализ данных (Data mining) осуществляется с помощью визуального программирования или сценариев Python. Сценарии Python могут выполняться в окне терминала, интегрированных средах, таких как PyCharm и PythonWin, или оболочках, таких как iPython.
Категория — Data Mining Software.
Лицензия — Open Source.
Стоимость — бесплатно.
Преимущества Orange для машинного обучения и анализа данных
• Для всех — начинающих и профессионалов.
• Выполнить простой и сложный анализ данных.
• Создавайте красивую и интересную графику.
• Использование в лекции анализа данных.
• Доступ к внешним функциям для расширенного анализа.
Лучшая и отличительная черта Orange — это замечательные визуальные эффекты.
Этот инструмент содержит компоненты для машинного обучения, дополнения для биоинформатики и интеллектуального анализа текста, а также множество функций для анализа данных. Orange состоит из интерфейса Canvas, на который пользователь помещает виджеты и создает рабочий процесс анализа данных.
Виджеты предлагают базовые функции, такие как чтение данных, отображение таблицы данных, выбор функций, предикторы обучения, сравнение алгоритмов обучения, визуализация элементов данных и т. д. Пользователь может интерактивно исследовать визуализации или передавать выбранное подмножество в другие виджеты.
В Orange процесс анализа данных (Data mining) может быть разработан с помощью визуального программирования.
Orange запоминает выбор, предлагает часто используемые комбинации. Orange имеет функции для различных визуализаций, таких как диаграммы рассеяния, гистограммы, деревья, дендрограммы, сети и тепловые карты.
Комбинируя виджеты, создайте структуру аналитики данных. Существует более 100 виджетов с охватом большинства стандартных и специализированных задач анализа данных для биоинформатики.
Orange читает файлы в собственном и других форматах данных.
Классификация использует два типа объектов: ученики и классификаторы. Учащиеся рассматривают данные, помеченные классом, и возвращают классификатор.
Методы регрессии в Orange очень похожи на классификацию. Они предназначены для интеллектуального анализа данных (Data mining), помеченных классом.
Обучение базовых наборов обучающих данных включает прогнозы отдельных моделей, чтобы достичь максимальной точности.
Модели могут быть получены из разных выборок обучающих данных или могут использовать разных учеников в одних и тех же наборах данных.
Учащиеся также могут быть разнообразны, изменяя свои наборы параметров.
Чем Orange поможет SEO-специалисту:
• Анализ и визуализация данных при аудите своего сайта или сайтов конкурентов;
• Анализ ссылочного, выявление связей в группе сайтов;
• Интеллектуальный анализ текстового контента (text-mining).
• Кластеризация данных.
Настройка системы Orange для анализа данных
Orange поставляется со встроенным инструментом Anaconda, если вы его предварительно установили. Если нет, выполните следующие действия для загрузки Orange.
Шаг 1: Перейдите на https://orange.biolab.si и нажмите «Скачать».
Шаг 2: Установите платформу и установите рабочий каталог, в котором Orange будет хранить свои файлы.
Прежде чем углубимся в работу Orange, давайте определим ключевые термины, которые помогут в дальнейшем понимании:
Виджет — основная точка обработки любых действий с данными. Виджет выполняет действия в зависимости от того, что вы выберете в селекторе виджетов в левой части экрана.
Рабочий процесс — это последовательность шагов или действий, которые вы выполняете на платформе для решения задачи.
Перейдите к разделу «Примеры рабочих процессов» на начальном экране, чтобы изучить варианты дополнительных рабочих процессов и используемых моделей.
Создание первого рабочего процесса
Нажмите «New» и создайте первый рабочий процесс.
Это первый шаг на пути к решению любой задачи. Обдумайте, какие шаги необходимо предпринять для достижения конечной цели — алгоритм построения процесса.

Импорт данных в Orange
Шаг 1: Нажмите на вкладку «Data» в меню выбора виджетов и перетащите виджет «File» в пустой рабочий процесс.
Шаг 2: Дважды щёлкните виджет «File» и выберите файл с данными, который вы хотите загрузить в рабочий процесс.
Шаг 3: Как только вы сможете увидеть структуру набора данных с помощью виджета, вернитесь, закрыв это меню.
Шаг 4: Поскольку нам нужна таблица данных, чтобы лучше визуализировать наши результаты, мы нажимаем на виджет «Data Table».
Шаг 5. Теперь дважды щёлкните виджет, чтобы визуализировать таблицу.

Визуализация данных при помощи Orange
Виджет Scatter Plot один из самых популярных в среде Orange. Нажмите на полукруг перед виджетом «File», перетащите его в пустое место в рабочем процессе и выберите виджет «Scatter Plot».
Как только создадите виджет Scatter Plot, дважды щёлкните по нему и изучите данные. Вы можете выбрать оси X и Y, цвета, формы, размеры и другие настройки.

Экспериментируйте, добавляя или меняя виджеты в вашем рабочем процессе.
Это только первая (вводная) статья об интеллектуальном анализе данных (Data mining) с использованием Orange. В следующей статье рассмотрим пример использования Orange для поисковой оптимизации сайтов.
Визуализация данных
Система Orange является инструментом для визуализации и анализа данных с открытым исходным кодом. Интеллектуальный анализ данных проводится путем визуального программирования и с помощью Python сценариев.
На рисунке представлен скриншот главного окна программы Orange3.
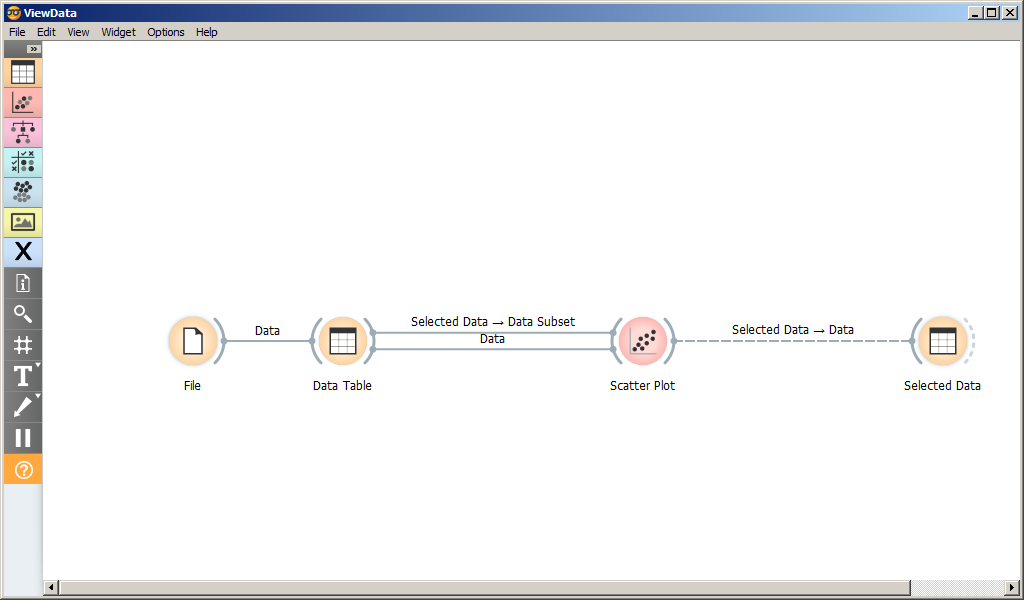
Рабочее пространство состоит из виджетов и связей между ними.
Каждый виджет имеет свой тип. Тип виджета можно определить по его иконке.
Виджеты сгруппированы по разделам: Data, Visualization, Predictions и пр. Группа виджета определяет цвет иконки.
Каждый виджет имеет множество (возможно, пустое) входных и множество выходных сигналов. Сигнал определяет данные, которые поступают на вход виджету или являются его результатом. При получении входного сигнала виджет выполняет определенные действия и оповещает связанные с ним виджеты путем отправки им соответсвующих сигналов.
Сигнал представляет собой экземпляр класса-наследника Orange.util.Reprable .
Для загрузки датасета имеется множество виджетов. Самый простой (File) считывает данные из файла или загружает по URL. Существуют виджеты для получения данных из базы данных PostgreSQL, Google Docs и других источников.
Скриншот параметров виджета File представлен на рисунке. Виджет позволяет выбрать файл с жесткого диска или загрузить из интернета по URL, а также выводит основные параметры датасета.
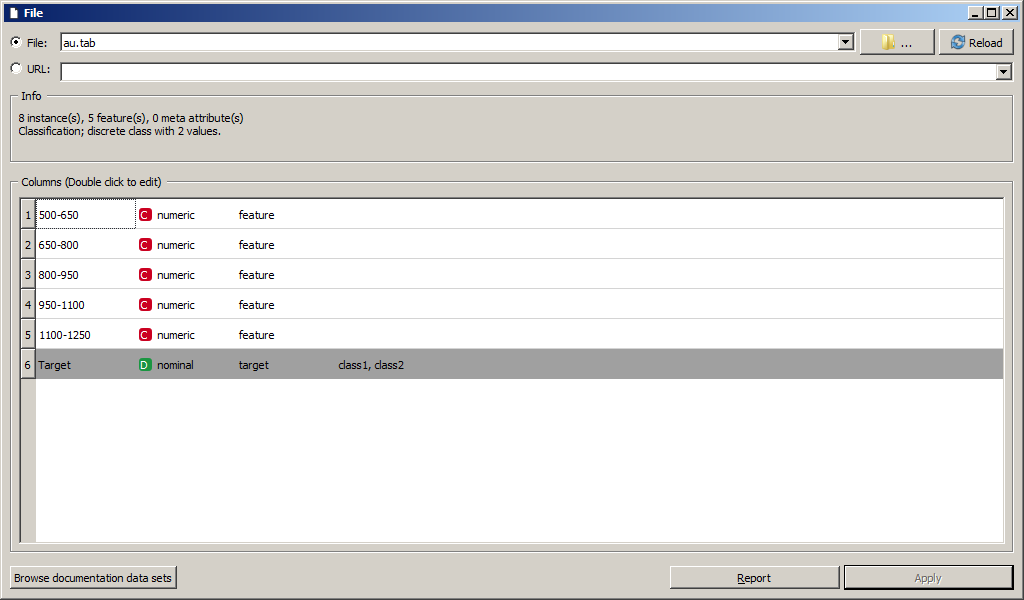
Виджет File имеет единственный выходной сигнал Data (тип Orange.data.Table ). Он связан с единственным входным сигналом Data виджета Data Table.
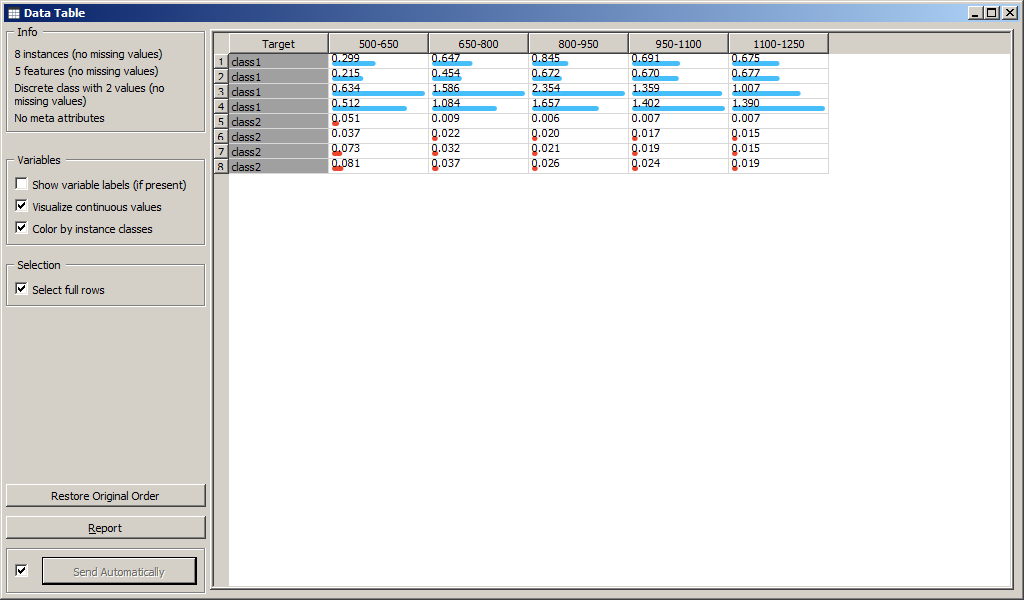
Виджет Data Table выводит данные из файла на экран.
При обновлении файла обновляется Data Table. При создании связи между виджетами входной и выходной сигналы выбираются автоматически. Если сигналов виджета много, то могут возникнуть ошибки. Для редактирования связи необходимо дважды кликнуть по ней мышью (рисунок [view1a]).
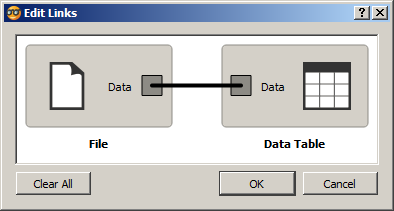
Связь между двумя виджетами подписывается над стрелкой. Если названия входного и выходного сигнала совпадают, то указывается это название. Если не совпадают, то указываются оба сигнала.
Виджет Scatter Plot позволяет строить двумерные графики по выбранным признакам.
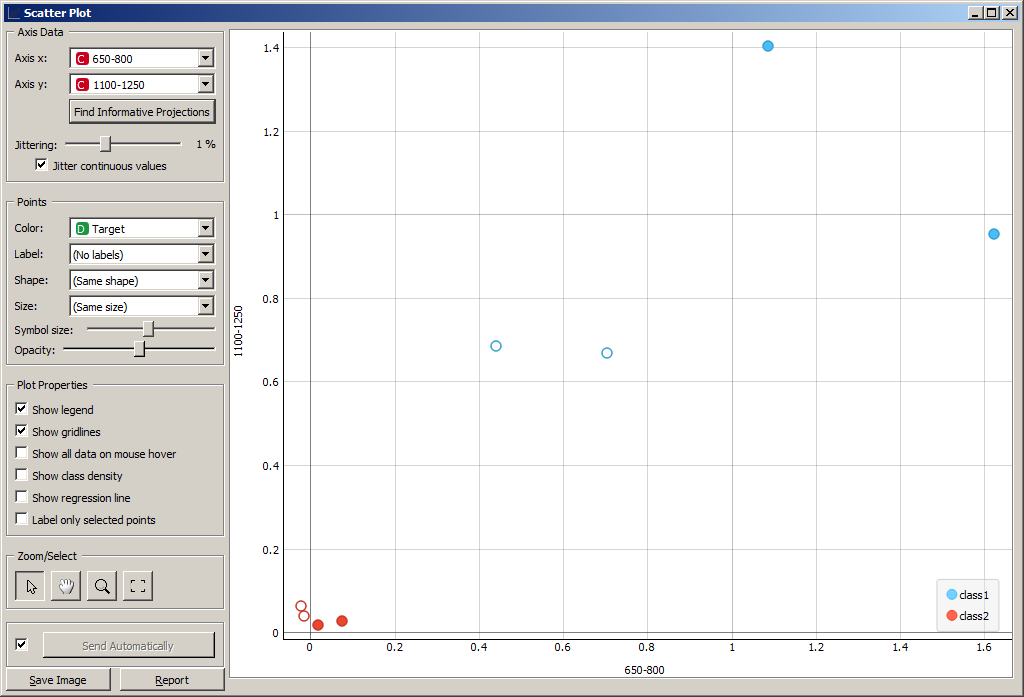
Виджет Scatter Plot имеет три входных сигнала:
- Data ( Orange.data.Table );
- Data Subset ( Orange.data.Table );
- Features ( Orange.widgets.widget.AttributeList ).
Сигнал Data принимает данные для отображения на графике, а сигнал Data Subset – подмножество данных. Если Data Subset определен, то на графике будут заштрихованы точки, соответствующие Data Subset.
Так, можно выбрать некоторые элементы из таблицы данных Data Table, и увидеть, как они расположены на графике по отношению к другим точкам. В примере на рисунке выбраны образы 3, 4, 5, 6.
Можно выделить некоторые точки на графике и изучить значения признаков соответствующих им объектов в таблице.
Система Orange содержит большое количество виджетов для визуализации данных, не рассмотренных выше. Среди них:
- Box Plot для построения диаграммы размаха (>);
- Distributions для построения диаграммы частотного распределения признака;
- Heat Map для построения тепловой диаграммы;
- Venn Diagram для построения диаграммы Венна;
- Sieve Diagram для построения паркетной диаграммы Ридвиля и Шюпбаха;
- Pythagorean Tree и Pythagorean Forest для построения деревьев Пифагора;
- Mosaic Display для построения мозаичной диаграммы;
- Tree Viewer для визуального представления древовидных структур;
- FreeViz и Radviz для визуализации многомерных данных;
Тестирование классификаторов
Схема программы для тестирования классификаторов приведена на рисунке.
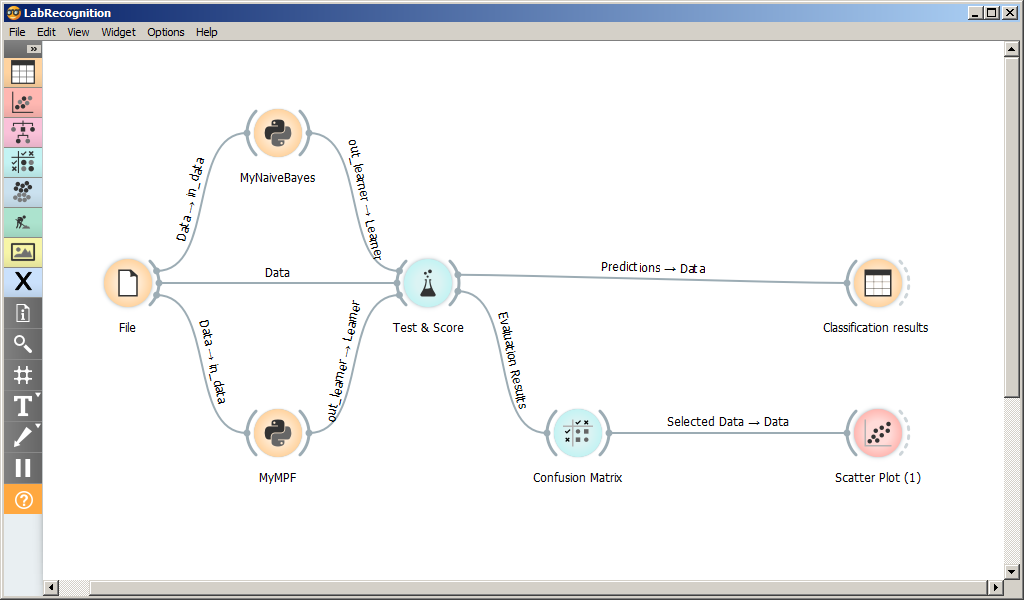
На форме размещены следующие виджеты:
- File для чтения датасета из файла;
- Python-скрипты MyNaiveBayes и MyMPF, классификаторы Байеса и методом потенциальных функций;
- Test and Score, виджет для сравнения и оценки классификаторов;
- Confusion Matrix, Scatter Plot, Classification results виджет для вывода результатов классификации;
MyNaiveBayes и MyMPF подробно рассмотрены в следующем разделе.
Виджет Test and Score принимает следующие входные сигналы @tas:
- Data ( Orange.data.Table ) – данные, на которых будет обучена модель;
- Test Data ( Orange.data.Table ) – данные для проверки модели;
- Learner ( Orange.classification ) – один или несколько > – обученных моделей классификации, которые будут тестироваться.
В качестве результата виджет имеет следующие выходные сигналы:
- Evaluation results ( Orange.evaluation.Results ) – результаты проверки классификаторов;
- Predictions ( Orange.data.Table ) – размеченная тестовая выборка.
Виджет Test and Score позволяет тестировать классификаторы одним из следующих методов:
- кросс-валидация;
- выделение одного;
- случайная разбивка в заданном соотношении;
- проверка на обучающей выборке;
- проверка на тестовой выборке.
Проверка классификатора осуществлялась методом случайного деления обучающей выборки в соотношении 33:66, т.е. треть данных была выделена для тестирования. Операция повторится два раза без сохранения промежуточной информации.
Результаты классификации приведены на рисунке.
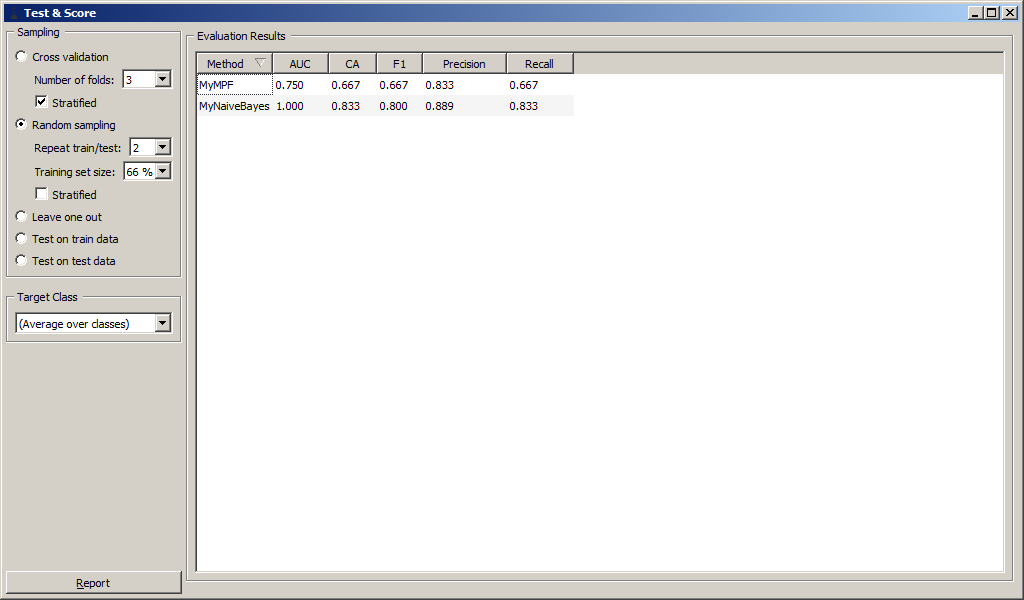
Были вычислены численные характеристики классификации:
- Area under ROC;
- Classification accuracy;
- F-1;
- Precision;
- Recall.
Для более детального анализа воспользуемся виджетом Confusion Matrix для сравнения количества правильно и неправильно распознанных образов. Результаты классификации MyMPF и MyNaiveBayes приведены на рисунках.
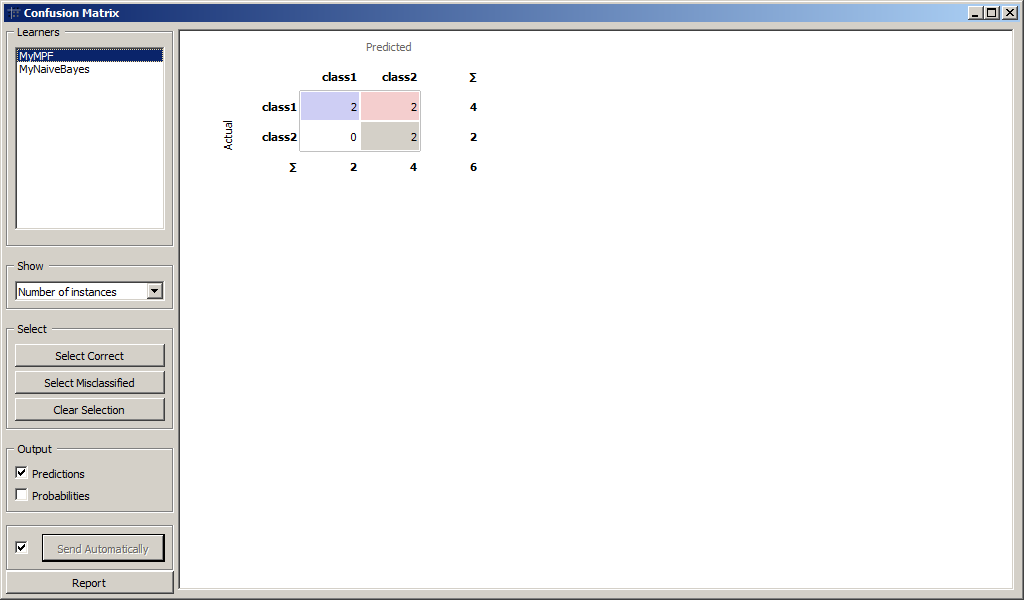
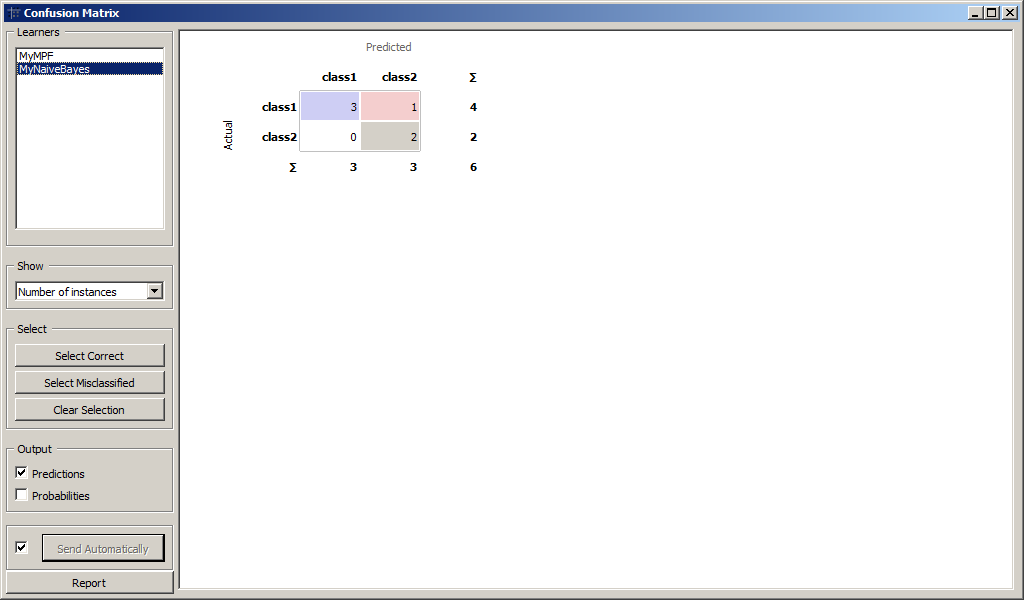
Образы, которые были подвергнуты классификации приведены на рисунках.
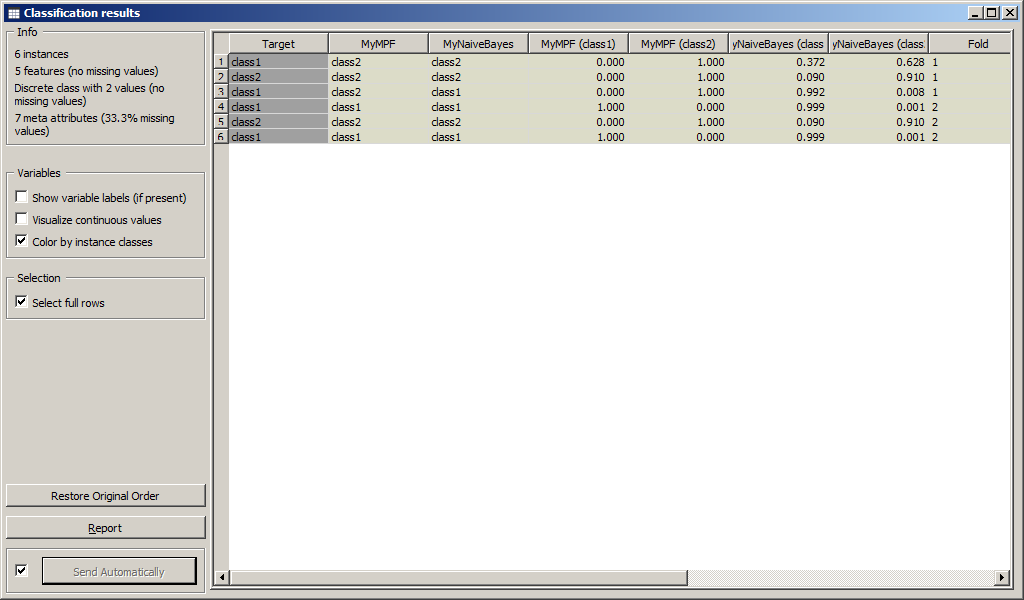
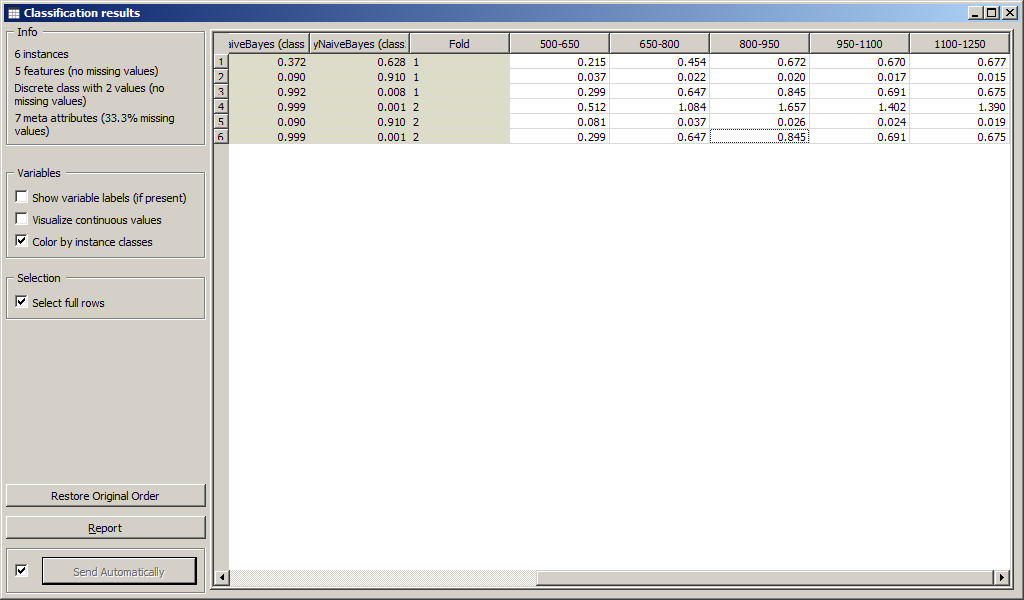
Результаты
Файлы orange-проектов можно скачать по ссылкам:
При подготовке материала использовались источники:
https://orangedatamining.com/
https://ansmirnov.ru/python-orange-anaconda-overview/