Алгоритмы Машинного обучения
Алгоритмы машинного обучения — это фрагменты кода, которые помогают пользователям исследовать и анализировать сложные наборы данных и находить в них смысл. Каждый алгоритм — это конечный набор однозначных пошаговых инструкций, которые компьютер может выполнять для достижения определенной цели. В модели машинного обучения цель заключается в том, чтобы установить или обнаружить закономерности, с помощью которых пользователи могут создавать прогнозы либо классифицировать информацию. Что такое машинное обучение? В алгоритмах машинного обучения используются параметры, основанные на учебных данных (подмножество данных, представляющее более широкий набор). При расширении учебных данных для более реалистичного представления мира с помощью алгоритма вычисляются более точные результаты. В различных алгоритмах применяются разные способы анализа данных. Они часто группируются по методам машинного обучения, в рамках которых используются: контролируемое обучение, неконтролируемое обучение и обучение с подкреплением. В наиболее популярных алгоритмах для прогнозирования целевых категорий, поиска необычных точек данных, прогнозирования значений и обнаружения сходства используются регрессия и классификация.
Методики машинного обучения
По мере изучения алгоритмов машинного обучения вы обнаружите, что они обычно относятся к одной из трех методик:
Контролируемое обучение
При контролируемом обучении алгоритмы обеспечивают прогнозирование на основе набора помеченных примеров. Эта методика полезна, если вы знаете, как должен выглядеть результат.
Например, вы предоставляете набор данных, в котором указано население городов за последние 100 лет, и хотите узнать численность населения определенного города через четыре года. При получении результата используются метки, которые уже есть в наборе данных: население, город и год.
Неконтролируемое обучение
При неконтролируемом обучении точки данных помечать не нужно. Алгоритм помечает их автоматически, упорядочивая данные или описывая их структуру. Этот метод полезен, если неизвестно, каким должен быть результат. Например, вы указываете данные о клиентах и хотите создать сегменты клиентов, которым нравятся похожие продукты. Данные, которые вы предоставляете, не помечаются. Метки в результатах формируются на основе сходств, обнаруженных между точками данных.
Обучение с подкреплением
При обучении с подкреплением используются алгоритмы, которые обучаются на результатах и определяют, какое действие следует предпринять. После каждого действия алгоритм получает отзыв, помогающий определить, является ли сделанный выбор правильным, нейтральным или неправильным. Этот метод удобно использовать в автоматизированных системах, которые должны принимать много мелких решений без вмешательства человека.
Например, вы разрабатываете беспилотный автомобиль, который должен соблюдать правила дорожного движения и обеспечивать безопасность людей. По мере того, как автомобиль накапливает опыт и историю подкрепления, он обучается соблюдать рядность движения, не превышать ограничение скорости и тормозить перед пешеходами.
Что можно делать с помощью алгоритмов машинного обучения
Алгоритмы машинного обучения помогают ответить на вопросы, на которые сложно ответить с помощью анализа, выполняемого вручную. Есть множество типов алгоритмов машинного обучения, но варианты их использования обычно относятся к одной из указанных ниже категорий.
Прогнозирование целевой категории
- Выйдет ли из строя эта шина на следующих 1000 км: да или нет?
- Что привлекает больше клиентов: 10 долл. США на счете или скидка 15%?
С помощью алгоритмов многоклассовой (полиномиальной) классификации можно разделить данные на три категории или более. Такие алгоритмы полезны для решения вопросов, у которых есть не менее трех взаимоисключающих ответов. Вот примеры:
- В каком месяце большинство путешественников покупают авиабилеты?
- Какую эмоцию выражает лицо человека на этой фотографии?
Поиск необычных точек данных
Алгоритмы обнаружения аномалий позволяют определить точки данных, которые выходят за пределы заданных параметров «нормы». С помощью алгоритмов обнаружения аномалий, к примеру, можно получить ответы на такие вопросы:
- Какие детали из этой партии бракованные?
- Какие покупки с помощью кредитной карты могут быть мошенническими?
Прогнозирование значений
С помощью алгоритмов регрессии можно спрогнозировать значение новой точки данных на основе исторических данных. Эти алгоритмы помогают получить ответ на такие вопросы:
- Какой будет средняя стоимость дома с двумя спальнями в моем городе в следующем году?
- Сколько пациентов примет клиника во вторник?
Изменение значений со временем
Алгоритмы временных рядов показывают, как заданное значение изменяется с течением времени. При анализе и прогнозировании временных рядов данные собираются через регулярные интервалы времени и используются для прогнозирования и определения тенденций, сезонности, цикличности и неравномерности. С помощью алгоритмов временных рядов можно получить ответы на такие вопросы:
- В следующем году цена определенной акции с большей вероятностью повысится или понизится?
- Какие у меня будут расходы в следующем году?
Обнаружение сходства
Алгоритмы кластеризации позволяют разделить данные на несколько групп, определяя степень сходства между точками данных. Алгоритмы кластеризации подходят для решения таких вопросов:
- Какие зрители предпочитают одинаковые типы фильмов?
- Какие модели принтеров выходят из строя аналогичным образом?
Классификация
Алгоритмы классификации используют прогнозные вычисления для присвоения данных предварительно заданным категориям. Алгоритмы классификации обучаются на входных данных и используются для получения ответов на такие вопросы:
- Это письмо — спам?
- Какова тональность (положительная, отрицательная или нейтральная) определенного текста?
Как работать с алгоритмами машинного обучения в Python

Машинное обучение — это процесс разработки и использования алгоритмов, которые позволяют компьютерам обучаться на основе данных и делать прогнозы или принимать решения. Python — один из самых популярных языков программирования для работы с алгоритмами машинного обучения, благодаря своей простоте и многочисленным библиотекам. В этой статье мы рассмотрим основные шаги по работе с алгоритмами машинного обучения в Python.
1. Импортирование библиотек
Для начала работы с машинным обучением в Python необходимо импортировать соответствующие библиотеки. Основные библиотеки, которые могут понадобиться, это:
- numpy для работы с массивами
- pandas для работы с данными
- matplotlib и seaborn для визуализации данных
- scikit-learn для алгоритмов машинного обучения
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error
Python-разработчик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT

2. Загрузка и предобработка данных
После импортирования библиотек следует загрузить и предобработать данные. Для этого используйте функцию read_csv() из библиотеки pandas :
data = pd.read_csv('path/to/your/data.csv')
Проверьте данные на наличие пропусков и обработайте их, если необходимо:
data.isnull().sum() data.dropna(inplace=True)
3. Визуализация данных
Визуализация данных позволяет получить представление о распределении и зависимости переменных. Используйте библиотеки matplotlib и seaborn для создания графиков, таких как гистограммы, диаграммы рассеяния или boxplot:
sns.pairplot(data) plt.show()
4. Разделение данных на обучающую и тестовую выборки
Перед обучением алгоритма машинного обучения разделите данные на обучающую и тестовую выборки с помощью функции train_test_split() :
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
5. Обучение алгоритма и оценка качества
Выберите алгоритм машинного обучения, обучите его на обучающей выборке и оцените качество на тестовой выборке:
model = LinearRegression() model.fit(X_train, y_train) y_pred = model.predict(X_test) mse = mean_squared_error(y_test, y_pred) print("Mean Squared Error:", mse)
😉 Теперь вы знаете основные шаги по работе с алгоритмами машинного обучения в Python. Удачи вам в изучении и практическом применении машинного обучения!
Памятка по алгоритмам машинного обучения при работе с конструктором Машинного обучения Azure
Памятка по алгоритмам Машинного обучения Azure поможет выбрать в конструкторе правильный алгоритм для модели прогнозирования.
Designer поддерживает два типа компонентов: классические предварительно созданные компоненты (версия 1) и пользовательские компоненты (версия 2). Эти два типа компонентов НЕ совместимы.
Классические предварительно созданные компоненты предоставляют предварительно созданные компоненты в основном для обработки данных и традиционных задач машинного обучения, таких как регрессия и классификация. Этот тип компонента по-прежнему поддерживается, но новые компоненты добавляться не будут.
Пользовательские компоненты позволяют создать оболочку для собственного кода в качестве компонента. Она поддерживает совместное использование компонентов в рабочих областях и удобную разработку в интерфейсах Studio, CLI версии 2 и ПАКЕТА SDK версии 2.
Для новых проектов настоятельно рекомендуется использовать настраиваемый компонент, который совместим с AzureML версии 2 и будет продолжать получать новые обновления.
Эта статья относится к классическим предварительно созданным компонентам и несовместима с CLI версии 2 и пакетом SDK версии 2.
Машинное обучение Azure имеет большую библиотеку алгоритмов из семейств классификации, рекомендательных систем, кластеризации, обнаружения аномалий, регрессии и анализа текста. Каждое семейство предназначено для решения определенного типа проблем, связанных с машинным обучением.
Дополнительные сведения см. в статье Выбор алгоритмов.
Скачивание памятки по алгоритмам Машинного обучения Microsoft Azure
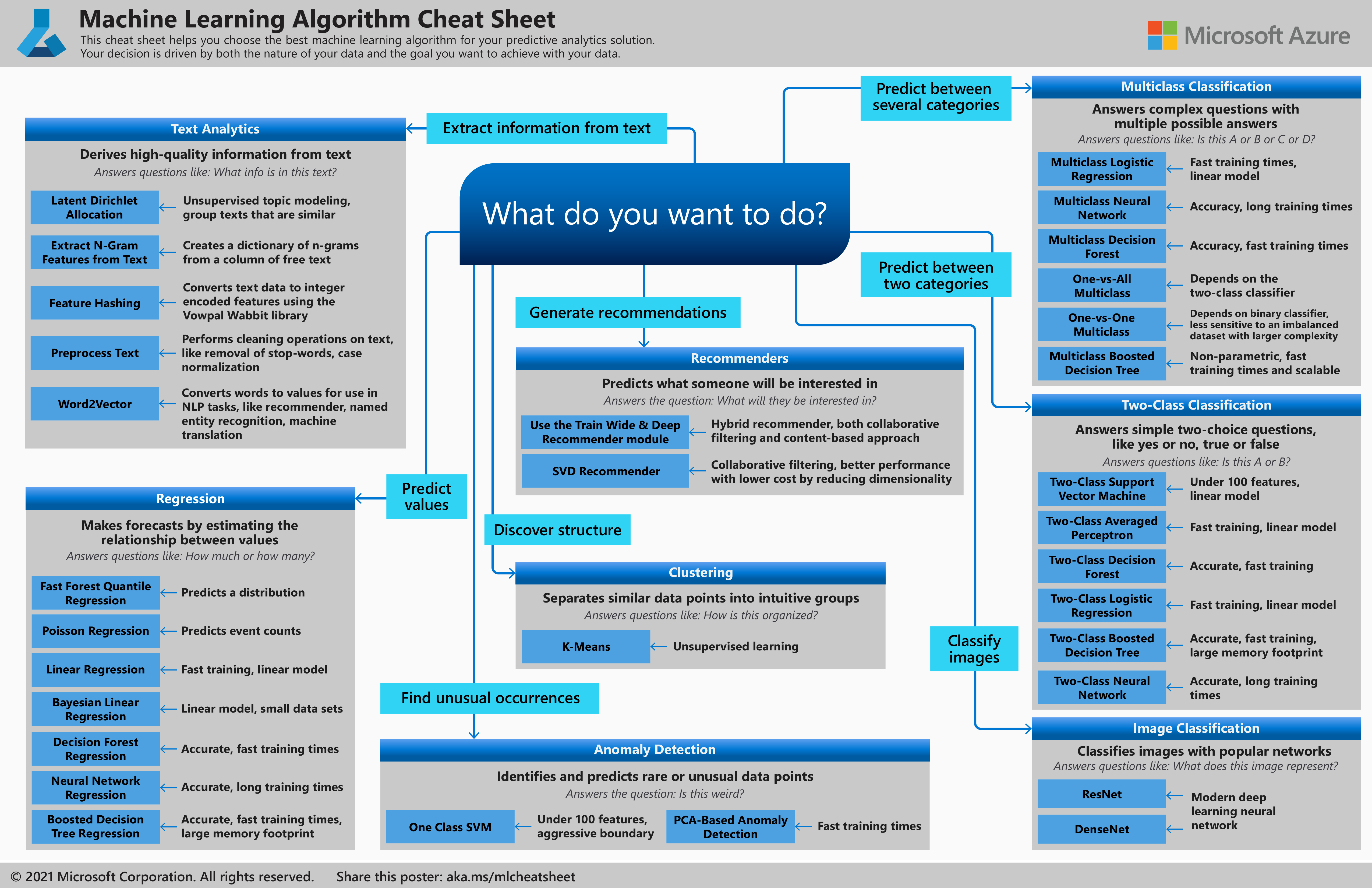
Скачайте и распечатайте памятку по алгоритмам машинного обучения размером 27,94 x 43,18 см (примерно A3), чтобы вы всегда могли обратиться к ней при выборе алгоритма.
Использование памятки по алгоритмам машинного обучения
Рекомендации, предлагаемые в этой памятке алгоритмов, представляют собой общие правила. Некоторые можно приспособить к конкретной ситуации, а некоторые можно грубо нарушать. Эта памятка предназначена для начала работы. Не бойтесь использовать несколько алгоритмов одновременно при обработке данных. Вам просто нужно понять принцип действия каждого алгоритма, а также систему, создающую данные.
Каждому алгоритму машинного обучения присущ собственный стиль индуктивного смещения. Для решения конкретной проблемы могут подходить несколько алгоритмов, но один из них может подходить лучше других. Но не всегда можно узнать заранее, какой именно подходит лучше. В подобных случаях в памятке указано сразу несколько алгоритмов. Лучше всего будет использовать один алгоритм, и если результаты неудовлетворительные, применить другие алгоритмы.
Дополнительные сведения об алгоритмах в конструкторе машинного обучения Azure см. в Справочнике по алгоритмам и компонентам.
Виды машинного обучения
Существуют три основные категории машинного обучения: контролируемое, неконтролируемое и обучение с подкреплением.
Контролируемое обучение
В контролируемом обучении каждая точка данных помечается или привязывается к интересующей категории или значению. Пример категориальной метки — назначение изображению значения cat или dog. Пример метки значения — цена продажи, связанная с подержанным автомобилем. Цель контролируемого обучения заключается в изучении множества помеченных таким образом примеров, а затем в возможности прогнозирования будущих точек данных. Например, чтобы правильно определить животных для новых фотографий или назначить точные цены продажи для других подержанных автомобилей. Это популярный и полезный тип машинного обучения.
Неконтролируемое обучение
При неконтролируемом обучении точкам данных не присваиваются метки. Вместо этого цель алгоритма неконтролируемого обучения — определенное упорядочивание данных или описание их структуры. Неконтролируемое обучение группирует данные в кластеры, как при использовании метода K-means, или находит разные способы просмотра сложных данных, чтобы они казались более простыми.
Обучение с подкреплением
В обучении с подкреплением алгоритм выбирает действие в ответ на каждую точку данных. Это наиболее распространенный подход в робототехнике, где набор показаний датчиков в один момент времени представляет собой точку данных, а алгоритму необходимо выбрать следующее действие робота. Кроме того, он естественным образом подходит для приложений из Интернета вещей. Алгоритм обучения также вскоре получает сигнал, оповещающий об успехе, который дает понять, насколько удачно было принято решение. На основе этого сигнала алгоритм изменяет свою стратегию для достижения лучшего результата.
Дальнейшие действия
- Дополнительные сведения см. в статье Выбор алгоритмов
- Сведения о студии при использовании Машинного обучения Azure и портала Azure.
- Учебник. Создание модели прогнозирования в конструкторе Машинного обучения Azure.
- Сравнение глубокого и машинного обучения.
При подготовке материала использовались источники:
https://azure.microsoft.com/ru-ru/resources/cloud-computing-dictionary/what-are-machine-learning-algorithms
https://sky.pro/media/kak-rabotat-s-algoritmami-mashinnogo-obucheniya-v-python/
https://learn.microsoft.com/ru-ru/azure/machine-learning/v1/algorithm-cheat-sheet?view=azureml-api-1