SAS DI Studio — A Consultant’s Take
SAS DI Studio (the DI stands for Data Integration) is the SAS tool that allows for the creation and maintenance of Extract, Transform and Load (ETL) jobs in a data warehousing environment. The idea is that companies have lots of operational data that needs to be manipulated in a batch fashion and then loaded into a read-only data warehouse repository. Once loaded, the data can be reported on by a wide variety of visualization tools. SAS DI Studio allows one to point-and-click through the process of getting data out of those operational systems and into the warehouse.
The concept behind DI Studio is solid – provide the user with a set of canned widgets that can be pieced together to create a data flow. Those widgets might be things like SQL Joins, Appends or Lookups. One can also create custom code modules to implement non-standard transformation logic. For example, calculate a 20% commission for senior sales people and a 10% commission otherwise.
Under the covers, DI Studio is a code generator. Each time that you deploy one of the transformation widgets, the (mostly) appropriate SAS code is generated. After you piece together several of the widgets, you end up with a flow of SAS code that can be deployed as part of a batch process and run nightly (or as frequently as needed).
The graphical interface for DI studio really promotes understanding of how the data travels from start to finish. It’s easy to see and thus maintain where each piece of code exists and what might need to be modified if something goes amiss. Here is a screen shot of the workspace area where you build your flow. Each orange circle represents a dataset or a table while each blue square is some type of extract, transformation or loading module.
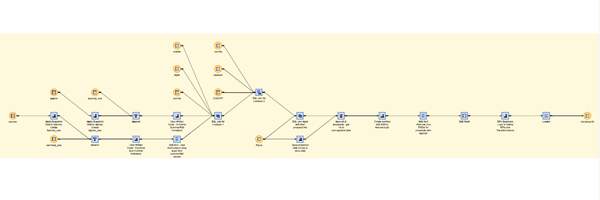
The DI studio tool is not without its labor-intensive tasks. Before you even begin to piece together your transformations you have to clearly define the source and target data sets for your flow. Although this can be done through a series of import wizards it can be a bit tedious and requires you to have thoroughly thought through your design. You can make changes to your flow after you have it in place but any substantial shifts like moving a dataset from one join to another sometimes gets the tool confused and requires close inspection of each of the transformation widgets to get everything back the way it should be.
Overall the SAS DI Studio tool is an effective mechanism for building and maintaining your ETL flows. Its positives far out-weigh its negatives and it is an essential ingredient of any SAS Intelligence platform.
Blue Chip Solutions has lots of experience with SAS DI Studio. As a matter of fact, we worked as a subcontractor and did most of the work for this project.
If you would like to use us and gain similar success, check out our consulting page and give us a call. We’re the best.
Интегрируем SAS и Greenplum
Данная статья может быть интересна тем, кто использует ETL средства SAS при построении хранилища данных. Недавно у нас завершилась активная фаза проекта по переводу хранилища на БД Greenplum. До этого в качестве базы данных использовались SAS datasets, т.е. фактически таблицы представляли собой файлы на файловой системе. В какой-то момент стало понятно, что скорость роста объемов данных больше той скорости, с которой мы можем увеличивать производительность файловой системы, и было принято решение о переходе на специализированную БД.

Когда мы начинали проект, в интернете было совершено невозможно найти что-нибудь, касающееся связки SAS DIS и Greenplum. Основные моменты перехода и возникшие в процессе трудности и хотелось бы осветить в этой статье.
Дополнительную сложность проекту придавало то, что надо было не строить процессы с нуля, а переделывать существующие, иначе бы сроки и стоимость проекта получились неприемлемыми. Исторически сложилось, что в качестве ETL средства мы используем SAS, и в частности SAS Data Integration Studio. Каждый ETL процесс здесь представляет собой т.н. job, в котором есть входные таблицы, логика их обработки, выходная таблица(ы). Ежедневный процесс загрузки хранилища состоит из ~800 таких job’ов. Их нам и предстояло переделать так, чтобы выиграть он переноса входных/выходных таблиц на Greenplum.
SAS/Access for Greenplum
- Схема БД определяется через SAS libname и с таблицами можно работать как с обычными SAS datasets. В этом случае SAS-код неявно транслируется в инструкции для БД, но, в случае невозможности такой трансляции (например, если используется какая-то функция SAS, отсутствующая в Greenplum), будет применена обработка запроса на стороне SAS.
- SQL pass-through. В proc sql можно писать код, который будет передан в ODBC-драйвер фактически as is.
Work -> Greenplum Work
По умолчанию принцип работы job’ов в SAS такой, что в качестве места для временных таблиц используется Work — создаваемая при старте сессии на диске директория, доступная только текущему владельцу процесса и удаляемая сразу по его завершении. В work’е содержатся SAS datasets, к которым применим язык SAS Base, что позволяет вести разработку ETL очень быстро. Также такое изолирование позволяет легко «чистить» место за упавшими job’ами, контролировать объемы используемого дискового пространства. При переводе job’ов на Greenplum часть (или все) промежуточные таблицы переезжали из WORK в Greenplum, и возник вопрос, куда эти таблицы складывать в БД?
- Автоматическая кодогенерация в SAS DI Studio не удаляет таблицы, которые больше не нужны. Потребовалась бы какая-то процедура, встраиваемая в каждый job, т.к. постоянно держать в базе полный объем вспомогательных таблиц ETL — слишком расточительно.
- Возможны конфликты имен у параллельно работающих job’ов.
- В случае каких-то проблем сложно идентифицировать, кому (какому job’у) принадлежит таблица.
- Одна такая «work» схема соответствует одной сессии SAS. На старте SAS-сессии в Greenplum создается схема, и на нее назначается SAS-библиотека.
- В имени создаваемой схемы кодируется необходимая информация, такая как путь до SAS work, хост, пользователь, процесс: %let LOAD_ETL_WRK_SCH_NAME = work_%substr(%sysfunc(pathname(work)),%sysfunc(prxmatch(/(?<=SAS_work)./,%sysfunc(pathname(work)))),12)_&SYSUSERID._srv%substr(&SYSHOSTNAME., %eval(%length(&SYSHOSTNAME.) — 1))_&SYSJOBID.;
- На крон ставим «чистильщик» временных схем Greenplum. Он для каждой «work_» схемы Greenplum проверяет наличие соответствующей ей сессии SAS и, в случае ее отсутствия, удаляет «work_» схему.
Передача данных между SAS и Greenplum
При такой схеме работы одним из главных вопросов становится скорость передачи данных между SAS и Greenplum. Передача данных из Greenplum в SAS всегда идет через master node и ограничена скоростью работы драйвера. Скорость зависит от ширины и составу полей выгружаемых таблиц, в среднем у нас получается порядка 50MB/s.
С загрузкой данных из SAS в Greenplum все значительно интересней. Greenplum позволяет делать bulk loading из текстовых файлов. Суть этого механизма в том, что внешний файл определяется как внешняя таблица (доступ к нему для Greenplum предоставляет специальная утилита, устанавливаемая на ETL хостах) и грузится напрямую на хосты с данными, минуя master. За счет этого скорость загрузки сильно возрастает. Со стороны SAS процесс выглядит так: таблица выгружается в csv-файл, а затем силами Greenplum этот файл затягивается в базу. Однако оказалось, что скорость этого процесса очень сильно зависит от скорости выгрузки таблицы из SAS в csv-файл. Выгрузка в файл идет со скоростью до 20-30MB/s (упирается в процессор), скорость загрузки csv в Greenplum превосходит 150 MB/s. Для больших таблиц это в итоге давало совершенно неудовлетворительную скорость загрузки. Ускорение было получено за счет разделения загружаемой таблицы на части: запускаются несколько параллельных потоков, каждый из которых работает со своим куском таблицы — выгружают его в csv и делают insert в Greenplum. Это позволило увеличить скорость загрузки данных в Greenplum до ~90-100 MB/s.
ETL primitives
Для работы в DI Studio нам пришлось переписать некоторые трансформы, т.к. стандартные генерировали код, который либо неоптимально работал, либо работал с ошибками. Речь идет о Table Loader и SCD Type2 Table Loader. В некоторых местах из-за переноса таблиц на Greenplum пришлось править job’ы: стандартный трансформ «Lookup», например, работает неэффективно, если обе входные таблицы лежат в БД.
Вместо заключения
В статье описаны основные из задач, которые пришлось решать в процессе миграции. Многое осталось за рамками статьи. Проблема с hash join, блокировки таблиц пользовательскими запросами, партицирование и сжатие. При наличии интереса опишем это более детально в следующих постах.
SAS Data Integration Development for SAS 9

Working with Tables and the Table Loader Transformation
- Discuss reasons to use the Table Loader transformation.
- Discuss various load styles provided by the Table Loader transformation.
- Discuss various types of keys and how to define in SAS Data Integration Studio.
- Discuss indexes and how to define in SAS Data Integration Studio.
- Discuss Table Loader options for keys and indexes.
- Discuss the Bulk Table Loader transformation.
- Discuss and use the components of the Join’s Designer Window related to in-database processing.
Working with Slowly Changing Dimensions
- List the functions of the SCD Type 2 transformation.
- Define business keys.
- Detect and track changes.
- Discuss the Lookup transformation.
- Discuss the SCD Type 1 Loader.
Defining Generated Transformations
- Define SAS code transformation templates.
- Create a custom transformation
Deploying Jobs
- Discuss the types of job deployment available for SAS Data Integration Studio Jobs.
- Provide an overview of the scheduling process.
- Discuss the types of scheduling servers.
- Discuss the Schedule Manager in SAS Management Console.
- Discuss batch servers.
- Describe deployment of SAS Data Integration Studio jobs as a SAS Stored Process.
In Database Processing
- Define in-database processing
- Enable in-database processing
- Define and discuss ELT methods
- Use a DBMS function in a SAS DI job
При подготовке материала использовались источники:
https://bluechipsolutions.com/SAS_Cheatsheets/SAS_DI_Studio_A_Consultants_Take.htm
https://habr.com/ru/companies/tinkoff/articles/155763/
https://www.sas.com/ru_ru/certification/exam-content-guides/data-integration-development.html