Spark
Apache Spark или просто Spark — это фреймворк (ПО, объединяющее готовые компоненты большого программного проекта), который используют для параллельной обработки неструктурированных или слабоструктурированных данных.

Освойте профессию «Data Scientist»
Например, если нужно обработать данные о годовых продажах одного магазина, то программисту хватит одного компьютера и кода на Python, чтобы произвести расчет. Но если обрабатываются данные от тысяч магазинов из нескольких стран, причем они поступают в реальном времени, содержат пропуски, повторы, ошибки, тогда стоит использовать мощности нескольких компьютеров и Spark. Группа компьютеров, одновременно обрабатывающая данные, называется кластером, поэтому Spark также называют фреймворком для кластерных вычислений.
Профессия / 24 месяца
Data Scientist
Дата-сайентисты решают поистине амбициозные задачи. Научитесь создавать искусственный интеллект, обучать нейронные сети, менять мир и при этом хорошо зарабатывать. Программа рассчитана на новичков и плавно введет вас в Data Science.

Зачем нужен Spark
Области использования Spark — это Big Data и технологии машинного обучения, поэтому им пользуются специалисты, работающие с данными, например дата-инженеры, дата-сайентисты и аналитики данных.
Примеры задач, которые можно решить с помощью Spark:
- изучить потребительское поведение;
- спрогнозировать прибыль и финансовые риски;
- обработать данные сенсоров и датчиков в системе интернета вещей;
- проанализировать информацию о транзакциях, безопасности финансовых операций и утечках.
Spark поддерживает языки программирования Scala, Java, Python, R и SQL. Сначала популярными были только первые два, так как на Scala фреймворк был написан, а на Java позже была дописана часть кода. С ростом Python-сообщества этим языком тоже стали пользоваться активнее, правда обновления и новые фичи в первую очередь доступны для Scala-разработчиков. Реже всего для работы со фреймворком используют язык R.
В структуру Spark входят ядро для обработки данных и набор расширений:
- Spark Core или ядро — это как раз движок. Он отвечает за хранение данных, управление памятью, распределение и отслеживание задач в кластере;
- MLlib — набор библиотек для машинного обучения;
- SQL — компонент, который отвечает за запрос данных;
- GraphX — модуль для работы с графами (абстрактными представлениями связей между множеством объектов);
- Streaming — средство для обработки потоков Big Data в реальном времени.
Как работает Spark
Спарк интегрирован в Hadoop — экосистему инструментов с открытым доступом, в которую входят библиотеки, система управления кластером (Yet Another Resource Negotiator), технология хранения файлов на различных серверах (Hadoop Distributed File System) и система вычислений MapReduce. Классическую модель Hadoop MapReduce и Spark постоянно сравнивают, когда речь заходит об обработке больших данных.

Станьте дата-сайентистом и решайте амбициозные задачи с помощью нейросетей
Принципиальные отличия Spark и MapReduce
Hadoop MapReduce
Пакетная обработка данных
Хранит данные на диске
Написан на Java
Spark
В 100 раз быстрее, чем MapReduce
Обработка данных в реальном времени
Хранит данные в оперативной памяти
Написан на Scala
Пакетная обработка в MapReduce проходит на нескольких компьютерах (их также называют узлами) в два этапа: на первом головной узел обрабатывает данные и распределяет их между рабочими узлами, на втором рабочие узлы сворачивают данные и отправляют обратно в головной. Второй шаг пакетной обработки не начнется, пока не завершится первый.
Обработка данных в реальном времени с помощью Spark Streaming — это переход на микропакетный принцип, когда данные постоянно обрабатываются небольшими группами.
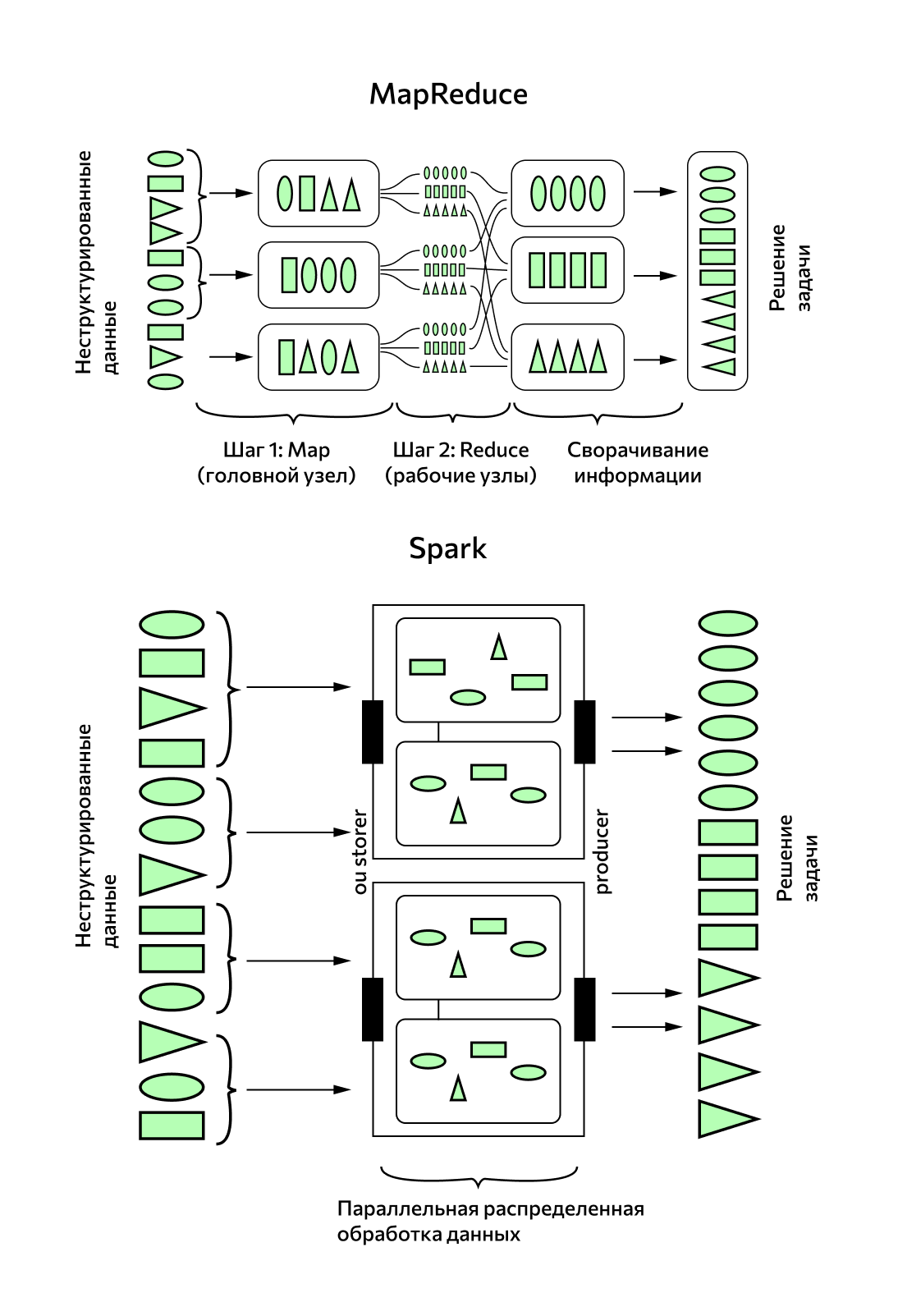
Кроме этого, вычисления MapReduce производятся на диске, а Spark производит их в оперативной памяти, и за счет этого его производительность возрастает в 100 раз. Однако специалисты предупреждают, что заявленная «молниеносная скорость работы» Spark не всегда способна решить задачу. Если потребуется обработать больше 10 Тб данных, классический MapReduce доведет вычисление до конца, а вот у Spark может не хватить памяти для такого вычисления.
Но даже сбой в работе кластера не спровоцирует потерю данных. Основу Spark составляют устойчивые распределенные наборы данных (Resilient Distributed Dataset, RDD). Это значит, что каждый датасет хранится на нескольких узлах одновременно и это защищает весь массив.
Разработчики говорят, что до выхода версии Spark 2.0 платформа работала нестабильно, постоянно падала, ей не хватало памяти, и проблемы решались многочисленными обновлениями. Но в 2021 году специалисты уже не сталкиваются с этим, а обновления в основном направлены на расширение функционала и поддержку новых языков.
Как правильно?
✅ «Наша компания использует Spark для прогнозирования финансовых рисков»
❌ «Я учусь работать в программе Spark»
Data Scientist
Дата-сайентисты решают поистине амбициозные задачи. Научитесь создавать искусственный интеллект, обучать нейронные сети, менять мир и при этом хорошо зарабатывать. Программа рассчитана на новичков и плавно введет вас в Data Science.

Статьи по теме:
ТОП-7 причин использовать Apache Spark для анализа больших данных и разработки распределенных приложений

В этой статье поговорим про Apache Spark – популярный Big Data фреймворк с открытым исходным кодом для обработки больших массивов данных. Он входит в экосистему проектов Apache Hadoop, однако выгодно отличается от ее других компонентов. Читайте далее, какие ключевые особенности Apache Spark делают его настолько привлекательным для практического применения в Data Science.
Чем хорош Apache Spark: главные преимущества
Одним из наиболее значимых достоинств Apache Spark является его скорость – в отличие от классического Hadoop MapReduce, он позволяет обрабатывать данные непосредственно в оперативной памяти. За счет этого многие задачи по обработке больших данных выполняются быстрее, что особенно важно в машинном обучении (Machine Learning). Однако, это далеко не единственный плюс рассматриваемого фреймворка. С практической точки зрения весьма полезны следующие его свойства, каждое из которых мы подробнее рассмотрим далее:
- богатый API;
- широкие функциональные возможности за счет многокомпонентного состава в виде модулей Spark SQL, Spark Streaming, MLLib;
- отложенные или ленивые вычисления (lazy evaluation);
- распределенная обработка данных;
- простые вращения данных при матричных и векторных операциях;
- легкие преобразования одних структур данных в другие;
- статус динамично развивающегося open-source проекта с активным профессиональным сообществом.
Богатый API
Apache Spark предоставляет разработчику довольно обширный API, позволяя работать с разными языками программирования: Python, R, Scala и Java. Spark предлагает пользователю абстракцию датафрейма (dataframe), для которых используются объектно-ориентированные методы преобразований, объединения данных, их фильтрации, а также много других полезных возможностей. Также объектный подход позволяет разработчику создавать настраиваемый и повторно используемый код, который можно тестировать с помощью различных специализированных методов и средств, например, отправка параметризованных запросов и создание разных окружений для одних и тех же запросов.
Также возможна интеграция Spark с такими BigData фреймворками, как Apache Kafka и Apache KUDU, а также с СУБД MySQL посредством компонента Spark SQL.
Широкий функционал
Spark обладает довольно широкими функциональными возможностями за счет следующих компонентов:
- Spark SQL – модуль, который служит для аналитической обработки данных с помощью SQL-запросов;
- Spark Streaming – модуль, обеспечивающий надстройку для обработки потоковых данных в режиме онлайн;
- MLib – модуль, предоставляющий набор библиотек машинного обучения.
Ленивые вычисления
Ленивые вычисления (lazy evaluations) позволяют снизить общий объем вычислений и повысить производительность программы за счет снижений требований к памяти. Такие вычисления весьма полезны, поскольку позволяют определять сложную структуру преобразований, представленных в виде объектов. Также можно проверить структуру конечного результата, не выполняя какие-либо промежуточные шаги. Еще Spark автоматически проверяет план выполнения запросов или программы на наличие ошибок. Это позволяет быстро отловить баги и отладить их.
Легкие преобразования
Для поддержки языка Python сообщество Apache Spark выпустило инструмент PySpark, который предлагает модуль Pyspark Shell, связывающий Python API и контекст Spark. Поэтому разработчик Big Data приложения может применять метод toPandas для беспрепятственного преобразования Spark DataFrame в Pandas. Это нужно для того, чтобы более эффективно сохранять обработанные файлы в csv-формат, а также ускорять обработку небольших массивов данных. Приведем пример такого преобразования:
import findspark findspark.init() findspark.find() import pyspark findspark.find() from pyspark.sql import SparkSession import pandas as pd from pyspark.sql.types import * conf = pyspark.SparkConf().setAppName('appName').setMaster('local') sc = pyspark.SparkContext(conf=conf) spark = SparkSession(sc) data = [] mySchema_3 = StructType([ StructField("col1", StringType(), True), StructField("col2", StringType(), True), StructField("col3", DoubleType(), True)]) data_1 = spark.createDataFrame(data,schema=mySchema_3) data_1.toPandas()
Метод toPandas позволяет вести работу в памяти после того, как Спарк разбил данные на более мелкие наборы данных. SparkSession.createDataFrame, в свою очередь, позволяет сделать наоборот:
spark = SparkSession.builder.appName('pandasToSparkDF').getOrCreate() pandas_df = pd.read_csv("test.csv") mySchema = StructType([ StructField("col1", LongType(), True)\ ,StructField("col2", IntegerType(), True)\ ,StructField("col3", IntegerType(), True)]) df = spark.createDataFrame(pandas_df,schema=mySchema)
Таким образом, PySpark расширяет функциональность языка Python до операций с массивными наборами данных, ускоряя цикл разработки.
Простые вращения данных
Вращение данных (data pivoting) считается проблемой для многих фреймворков, работающих с большими данными, например, Apache Kaflka или Flink. Как правило, такие операции требуют множества операторов case. Спарк же имеет в своем арсенале простой и интуитивно понятный способ поворота Datafame. Пользователю необходимо всего лишь выполнить операцию groupBy для столбцов с целевым индексом, поворачивая целевое поле для дальнейшего использования в качестве столбцов. Далее можно приступать непосредственно к самому агрегированию. В качестве примера приведем нахождение среднего значения в колонке:
test_data = spark.read.option('header','True').csv('test.csv',sep=';') test_data test_data.groupby(['col1', 'col2']).agg().withColumnRenamed("avg(col3)", "col3")
Метод groupBy позволил использовать колонки col1 и col2 в качестве индексов для последующего агрегирования методом agg .
Apache Spark – это фреймворк с открытым исходным кодом
Входя в линейку проектов Apache Software Foundation, Спарк продолжает активно развиваться за счет сообщества разработчиков. Энтузиасты open-source улучшают основной софт и предлагают дополнительные пакеты. Например, в октябре 2017 года была опубликована библиотека обработки нативного языка для Spark. Это избавило пользователя от необходимости применять другие библиотеки или полагаться на медленные пользовательские функции для таких пакетов Python, как Natural Language Toolkit.
Реализация распределенной обработки данных
Наконец, что особенно важно в разработке Big Data приложений, Apache Spark предусматривает распределенную обработку данных, включая концепцию RDD (resilient distributed dataset) – это распределенная структура данных размещаемая в оперативной памяти. Каждый RDD содержит фрагмент данных, распределенных по узлам кластера. За счет этого он является отказоустойчивым: если раздел теряется в результате сбоя узла, он может быть восстановлен из исходных источников. Таким образом, Спарк сам раскидывает код по всем узлам кластера, разбивает его на подзадачи, создает план выполнения и отслеживает успешность выполнения. В случае сбоя на каком-нибудь из узлов или неуспешном завершении подзадачи, она будет перезапущена автоматически.
В следующей статье мы продолжим разговор про Apache Spark и рассмотрим основные компоненты этого фреймворка.
Освоить Apache Spark на профессиональном уровне для практического использования в своих проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Apache Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.
Из чего состоит Apache Spark: краткий обзор компонентов

В этой статье мы поговорим про компоненты, которые входят в популярный Big Data фреймворк Apache Spark, составляя его унифицированный стек. Благодаря им Spark обладает широкими функциональными возможностями и способен поддерживать множество вариантов использования. Читайте далее, какие компоненты делают Spark настолько мощным средством обработки больших данных (Big Data).
Что представляет собой стек Apache Spark: главные компоненты
Компоненты Спарк тесно интегрированы друг с другом, предоставляя разработчику возможность объединять их, подобно коллекции библиотек в программном проекте. Это дает возможность библиотекам извлекать выгоды от улучшений в слоях более низкого уровня. Например, когда в ядро Спарк вносятся какие-либо оптимизации, то библиотеки, поддерживающие SQL и машинное обучение, автоматически увеличивают производительность такого кода. Итак, в стек Спарк входят следующие компоненты:
- основной функционал Ядра Спарк;
- пакет поддержки SQL-запросов Spark SQL;
- обработчик потоковых данных Spark Streaming;
- библиотека для машинного обучения MLlib;
- библиотека для работы с графами GraphX;
- компоненты HadoopYARN, Apache Mesos, Standalone Scheduler, обеспечивающие распределенную работу на множестве кластерных узлов.
Как работает каждый из вышеперечисленных компонентов, мы рассмотрим далее.
Spark Core
Основной задачей Ядра Спарк является реализация основных функциональных возможностей фреймворка Спарк, с помощью которых осуществляется планирование заданий, управление памятью, обработка ошибок, а также взаимодействие с системами хранения данных. Ядро Спарк также служит основой API устойчивых распределенных наборов данных (Resilient Distributed Datasets), которая является базовой абстракцией и структурой данных в Спарке. Наборы RDD представляют собой коллекции элементов, которые распределяются в пределах некоторого множества вычислительных узлов, а также поддерживают параллельную обработку. В техническом плане Spark Core представляет собой большую библиотеку с множеством функций для управления такими коллекциями.
Spark SQL
Spark SQL – это пакет для работы и анализа структурированных данных, который позволяет извлекать данные с помощью инструкций на языке запросов SQL и его диалекте Hive Query Language (HQL). Spark SQL также поддерживает множество популярных Big Data форматов, таких как Hive, Parquet и JSON. Помимо интерфейса SQL, компонент Spark SQL позволяет смешивать в одном приложении запросы на языке SQL с программными конструкциями на Python, JAVA и Scala, которые поддерживаются абстракцией RDD. Spark SQL позволяет анализировать большие коллекции данных с помощью стандартного механизма SQL-запросов, который знаком каждому аналитику. Spark SQL отлично интегрируется с любой СУБД посредством интерфейса соединения.
Spark Streaming
Фреймворк позволяет вести обработку потоковых данных в режиме онлайн благодаря компоненту Spark Streaming. Источниками таких данных могут служить файлы журналов, которые заполняются действующими веб-серверами, а также очереди сообщений, посылаемые пользователями различных веб-служб. Spark Streaming имеет API для управления потоками данных, который похож на RDD, поддерживаемый ядром (Core). Это очень облегчает изучение самого проекта и различных приложений обработки данных, которые хранятся в памяти. Spark Streaming отлично интегрируется с Apache Kafka, позволяя строить потоковые data pipelines, например, в системах интернета вещей (IoT, Internet of Things) и прочих бизнес-приложениях.
MLlib
Библиотека MLlib делает возможным реализацию механизмов машинного обучения (Machine Learning). MLlib поддерживает множество алгоритмов машинного обучения, включая классификацию (classification), регрессию (regression), кластеризацию (clustering), совместную фильтрацию (collaborative filtration) и прочие популярные методы. Этот компонент также позволяет разрабатывать нестандартные алгоритмы машинного обучения, в т.ч. на базе нейросетей. Все алгоритмы могут свободно реализовываться в пределах кластера.
GraphX
GraphX – это библиотека, отвечающая за обработку графов и выполнение параллельных вычислений. Эта библиотека отлично дополняет RDD API фреймворка Спарк тем, что предоставляет возможность создания ориентированных графов с произвольными свойствами. GraphX также позволяет управлять графами через выполнение специфических операций, таких как, например, subgraph и mapVertices. На практике GraphX активно используется для ведения статистики в социальных сетях, например, если требуется найти наиболее популярных или активных пользователей.
Диспетчеры кластеров
Внутренняя реализация Спарк обеспечивает весьма эффективное масштабирование от одного до нескольких тысяч узлов. Такая гибкость достигается благодаря диспетчерам кластеров (cluster managers):
- HadoopYARN, который отвечает за распределение системных ресурсов;
- Apache Mesos, обеспечивающий изоляцию ресурсов кластера;
- Standalone Scheduler, который можно использовать на множестве машин на начальном этапе установки для планирования задач.
Комбинация всех вышерассмотренных компонентов в рамках одного фреймворка делает Спарк полезным для каждого специалиста в области Big Data, от Data Scientist’а до разработчика распределенных приложений. В следующей статье мы расскажем про коллекции данных RDD во фреймворке Спарк.
Освоить Спарк на профессиональном уровне для практического использования в своих проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Apache Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.
При подготовке материала использовались источники:
https://spark-school.ru/blogs/top7-reasons-to-use-apache-spark/
https://spark-school.ru/blogs/apache-spark-stack/