Как работают Spark-приложения в кластере
В этой статье мы поговорим о том, как выполняются приложения, которые создавались на базе фреймворка Apache Spark. Читайте далее про архитектуру среды выполнения Spark, а также про компоненты, из которых она состоит.
Как устроены приложения Apache Spark: базовые компоненты архитектуры
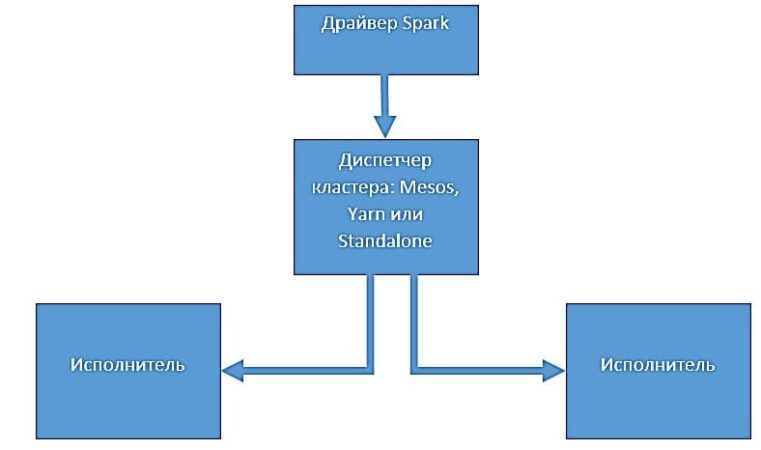
Приложения, которые создаются на базе среды Spark, предназначены для выполнения в распределенных системах. Архитектура такой среды включает в себя следующие компоненты:
- драйвер;
- исполнители;
- диспетчер кластера.
Каждый из этих компонентов подробнее мы рассмотрим далее.
Драйвер Spark
Драйвер Spark представляет собой процесс, который запускает метод main() нашего приложения. Этот процесс запускает код, который создает объект классов SparkContext и SparkConf . Когда запускается интерактивная оболочка Spark, создается экземпляр программы-драйвера:
from pyspark import SparkContext, SparkConf conf = pyspark.SparkConf().setAppName('Application1').setMaster('local') sc = pyspark.SparkContext(conf=conf)
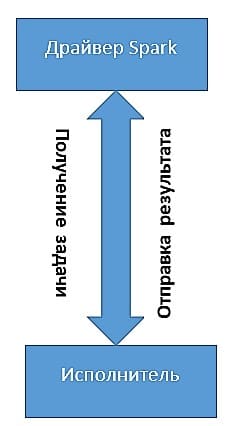
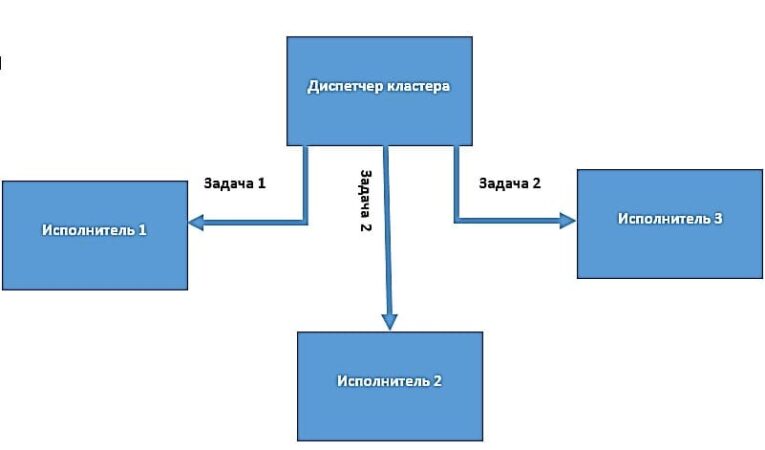
Драйвер Spark преобразует пользовательское приложение на единицы исполнения, которые называются задачами (tasks). На верхнем уровне все приложения Spark создают наборы RDD на основе исходных данных, тем самым порождая новые RDD с применением некоторых преобразований и выполняют действия для сбора и последующего хранения данных. Таким образом, создается неявный ориентированный ациклический граф (Directed Acyclic Graph, DAG) всех операций. В процессе выполнения программа-драйвер преобразует этот граф в план выполнения. Драйвер Spark выполняет оптимизации преобразований и преобразует DAG в несколько этапов. Каждый такой этап состоит из нескольких задач. Задача считается наименьшей пользовательской единицей выполнения в Spark. Приложение может разбиваться на несколько сотен и даже тысяч заданий (в зависимости от функционала). На основе составленного плана со всеми задачами драйвер Spark контролирует передачу этих задач исполнителям. При запуске каждый исполнитель регистрирует себя в драйвере.
Исполнители
Исполнители в Spark – это рабочие процессы, которые ответственны за выполнение задач, присланных драйвером. Исполнители запускаются только один раз при запуске приложения Spark и продолжают свою работу на протяжении всего жизненного цикла программы. Они выполняют задачи, приходящие от драйвера и возвращают результат обратно драйверу Spark. Исполнители также обеспечивают хранение данных в памяти наборов RDD, которые кэшируются через службу Block Manager, функционирующую внутри каждого из исполнителей.
Диспетчеры кластеров
Диспетчеры кластеров – это отдельно подключаемые внешние программы. Они отвечают за масштабирование вычислительных узлов и распределение задач, идущих от драйвера к исполнителям. Когда приложение Spark делает запрос к диспетчеру кластера на предоставление процессов исполнителей, оно может получить доступное количество узлов в зависимости от загруженности кластера. Диспетчеры кластеров могут определять очереди с разными приоритетами или доступными ресурсами. Благодаря диспетчерам кластеров драйвер Spark имеет возможность посылать задачи в эти очереди.
Таким образом, распределенная архитектура приложения Spark позволяет выполнять ему огромные объемы задач благодаря параллельной работе узлов. Все это делает фреймворк Apache Spark весьма полезным средством для Data Scientist’а и разработчика Big Data приложений. В следующей статье мы поговорим про развертывание Spark-приложений.
Более подробно про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.
Из чего состоит Apache Spark: краткий обзор компонентов

В этой статье мы поговорим про компоненты, которые входят в популярный Big Data фреймворк Apache Spark, составляя его унифицированный стек. Благодаря им Spark обладает широкими функциональными возможностями и способен поддерживать множество вариантов использования. Читайте далее, какие компоненты делают Spark настолько мощным средством обработки больших данных (Big Data).
Что представляет собой стек Apache Spark: главные компоненты
Компоненты Спарк тесно интегрированы друг с другом, предоставляя разработчику возможность объединять их, подобно коллекции библиотек в программном проекте. Это дает возможность библиотекам извлекать выгоды от улучшений в слоях более низкого уровня. Например, когда в ядро Спарк вносятся какие-либо оптимизации, то библиотеки, поддерживающие SQL и машинное обучение, автоматически увеличивают производительность такого кода. Итак, в стек Спарк входят следующие компоненты:
- основной функционал Ядра Спарк;
- пакет поддержки SQL-запросов Spark SQL;
- обработчик потоковых данных Spark Streaming;
- библиотека для машинного обучения MLlib;
- библиотека для работы с графами GraphX;
- компоненты HadoopYARN, Apache Mesos, Standalone Scheduler, обеспечивающие распределенную работу на множестве кластерных узлов.
Как работает каждый из вышеперечисленных компонентов, мы рассмотрим далее.
Spark Core
Основной задачей Ядра Спарк является реализация основных функциональных возможностей фреймворка Спарк, с помощью которых осуществляется планирование заданий, управление памятью, обработка ошибок, а также взаимодействие с системами хранения данных. Ядро Спарк также служит основой API устойчивых распределенных наборов данных (Resilient Distributed Datasets), которая является базовой абстракцией и структурой данных в Спарке. Наборы RDD представляют собой коллекции элементов, которые распределяются в пределах некоторого множества вычислительных узлов, а также поддерживают параллельную обработку. В техническом плане Spark Core представляет собой большую библиотеку с множеством функций для управления такими коллекциями.
Spark SQL
Spark SQL – это пакет для работы и анализа структурированных данных, который позволяет извлекать данные с помощью инструкций на языке запросов SQL и его диалекте Hive Query Language (HQL). Spark SQL также поддерживает множество популярных Big Data форматов, таких как Hive, Parquet и JSON. Помимо интерфейса SQL, компонент Spark SQL позволяет смешивать в одном приложении запросы на языке SQL с программными конструкциями на Python, JAVA и Scala, которые поддерживаются абстракцией RDD. Spark SQL позволяет анализировать большие коллекции данных с помощью стандартного механизма SQL-запросов, который знаком каждому аналитику. Spark SQL отлично интегрируется с любой СУБД посредством интерфейса соединения.
Spark Streaming
Фреймворк позволяет вести обработку потоковых данных в режиме онлайн благодаря компоненту Spark Streaming. Источниками таких данных могут служить файлы журналов, которые заполняются действующими веб-серверами, а также очереди сообщений, посылаемые пользователями различных веб-служб. Spark Streaming имеет API для управления потоками данных, который похож на RDD, поддерживаемый ядром (Core). Это очень облегчает изучение самого проекта и различных приложений обработки данных, которые хранятся в памяти. Spark Streaming отлично интегрируется с Apache Kafka, позволяя строить потоковые data pipelines, например, в системах интернета вещей (IoT, Internet of Things) и прочих бизнес-приложениях.
MLlib
Библиотека MLlib делает возможным реализацию механизмов машинного обучения (Machine Learning). MLlib поддерживает множество алгоритмов машинного обучения, включая классификацию (classification), регрессию (regression), кластеризацию (clustering), совместную фильтрацию (collaborative filtration) и прочие популярные методы. Этот компонент также позволяет разрабатывать нестандартные алгоритмы машинного обучения, в т.ч. на базе нейросетей. Все алгоритмы могут свободно реализовываться в пределах кластера.
GraphX
GraphX – это библиотека, отвечающая за обработку графов и выполнение параллельных вычислений. Эта библиотека отлично дополняет RDD API фреймворка Спарк тем, что предоставляет возможность создания ориентированных графов с произвольными свойствами. GraphX также позволяет управлять графами через выполнение специфических операций, таких как, например, subgraph и mapVertices. На практике GraphX активно используется для ведения статистики в социальных сетях, например, если требуется найти наиболее популярных или активных пользователей.
Диспетчеры кластеров
Внутренняя реализация Спарк обеспечивает весьма эффективное масштабирование от одного до нескольких тысяч узлов. Такая гибкость достигается благодаря диспетчерам кластеров (cluster managers):
- HadoopYARN, который отвечает за распределение системных ресурсов;
- Apache Mesos, обеспечивающий изоляцию ресурсов кластера;
- Standalone Scheduler, который можно использовать на множестве машин на начальном этапе установки для планирования задач.
Комбинация всех вышерассмотренных компонентов в рамках одного фреймворка делает Спарк полезным для каждого специалиста в области Big Data, от Data Scientist’а до разработчика распределенных приложений. В следующей статье мы расскажем про коллекции данных RDD во фреймворке Спарк.
Освоить Спарк на профессиональном уровне для практического использования в своих проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Apache Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.
При подготовке материала использовались источники:
https://spark-school.ru/blogs/spark-clustering/
https://spark-school.ru/blogs/apache-spark-stack/