Mail.Ru Group запустила систему для хранения данных Tarantool Статьи редакции
Mail.Ru Group начала предоставлять своим клиентам услуги хранения данных на базе opensource-системы управления базами данных (СУБД) Tarantool. Об этом vc.ru сообщили в холдинге.
Tarantool позволяет компаниям оптимизировать работу и сократить расходы на ИТ-инфраструктуру. По словам представителей Mail.Ru Group, один сервер с Tarantool способен заменить от тридцати и более серверов с классической СУБД.
«Tarantool делает разработку проще и быстрее. Разработчику не надо создавать сложную гетерогенную систему из SQL СУБД + NoSQL СУБД + кэш. Не надо создавать огромные кластера и платить миллионы за железо. Достаточно одного «Тарантула» — мощного, высокопроизводительного решения, который является SSOT (single source of truth) и не требует других СУБД в качестве бэкенда», — утверждает технический директор сервиса «Почта Mail.Ru» Денис Аникин.
Система доступна в открытом доступе под лицензией BSD. Зарабатывать Mail.Ru Group планирует за счет платной технической поддержки клиентов Tarantool и кастомизации системы под специфические запросы. Партнёрами холдинга по использованию системы стали сайт частных объявлений Avito, сервис знакомств Badoo и компания Wallarm, которая занимается защитой от хакерских атак.
Tarantool используется в большинстве проектов Mail.Ru Group, таких как «Почта», «Облако Mail.Ru», myTarget и многих других. Например, он обеспечивает хранение пользовательских сессий и профилей, работу таких систем, как портальная аутентификация, антибрутфорс, антифишинг и антиспам, где он доказал свою способность эффективно работать с большими объемами данных и под высокими нагрузками, позволив нам добиться колоссального сокращения затрат, ускорить разработку и улучшить пользовательский опыт.
— Владимир Габриелян, вице-президент и технический директор Mail.Ru Group
Зачем вам Tarantool: разгоняем большие данные с помощью In-Memory database

В этой статье мы рассмотрим резидентные (In-Memory) базы данных на примере Tarantool и Arenadata Grid: что это, как они работают и где используются. Еще поговорим, каким образом эти Big Data системы могут ускорить работу распределенных приложений без замены существующих СУБД, а также при чем здесь промышленный интернет вещей и экосистема Apache Hadoop для хранения больших данных.
Who is who на рынке In-Memory DataBase: краткий обзор самых популярных решений
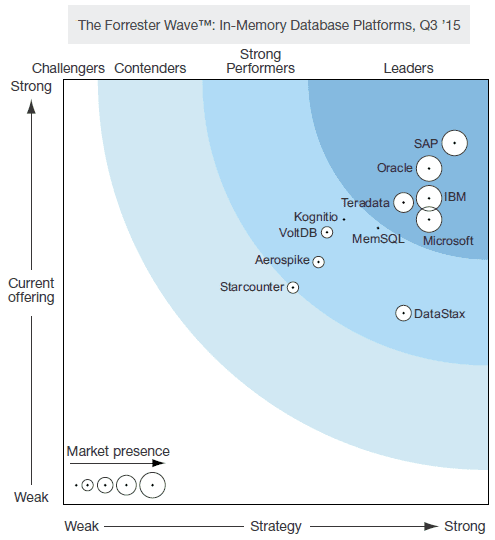
В 2019 году аналитическое агентство Gartner включило резидентные базы данных, в которых информация размещается в памяти, в перечень наиболее перспективных технологий в области Data Management. При этом на графике технологической зрелости (Hype Cycle) In-Memory database (IMDB) расположены на восходящем участке по пути к плато продуктивности [1]. Это не удивительно с учетом длительной истории таких СУБД: впервые они появились еще в 90-е годы прошлого века: SolidDB, Timesten. Удешевление стоимости серверных модулей оперативной памяти вместе с популяризацией технологий Big Data стали новыми драйверами развития IMDB [2]. Наиболее крупными игроками на современном рынке резидентных баз данных считаются коммерческие решения от IBM (DB2 with BLU Acceleration and dashDB), Microsoft (SQL Server 2014), Oracle (TimesTen), SAP (Hana), Pivotal (GemFire XD) и Teradata (Intelligent Memory). Еще в ТОП-19 лучших IMDB-СУБД от Gartner вошли широко известные open-source продукты (VoltDB, Redis, Aerospike, Altibase, Couchbase Server) и некоторые проприетарные, в т.ч. облачные, решения: Unicom Systems solidDB, Quartet FS ActivePivot, ParStream, MemSQL, Kognitio Analytical Platform, McObject eXtremeDB, DataStax Enterprise [3]. Разумеется, это далеко не все резидентные СУБД: сюда же относится Apache Ignite, InfinityDB, Memcached, SQLite, MySQL NDB Cluster, Mnesia и прочие открытые и проприетарные решения, в частности Tarantool [4], который мы рассмотрим далее.
Вездесущий Tarantool: от email до IIoT
В отличие от всех вышеперечисленных IMDB, Tarantool является отечественным продуктом, разработанным в Mail.ru Group еще в 2008 году для внутреннего пользования. В частности, эта Big Data система применяется в Почте, Облаке, myTarget и других сервисах Mail.ru. В апреле 2016 года компания опубликовала исходный код Tarantool в открытом доступе под лицензией BSD. Вообще эта СУБД широко применяется в российских Big Data проектах. Например, ее используют соцсети Badoo и Одноклассники [5], мобильные операторы Билайн, Yota и Мегафон, Avito, Qiwi, Аэрофлот и Альфа-банк. Практическое признание Тарантул получил за способность эффективно работать при высоких нагрузках и с большими объемами данных, обеспечивая производительность на уровне миллион транзакций в секунду на одном ядре простейшего сервера. Таким образом, Tarantool позволяет снизить расходы на hardware в распределенном кластере Big Data [6].
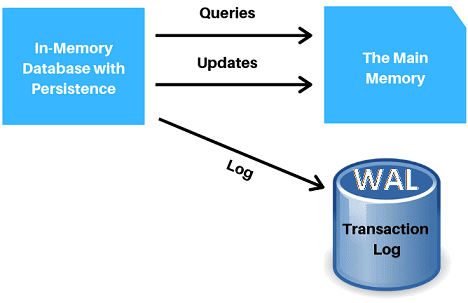
Подобное быстродействие обеспечивается тем, что данные в Tarantool хранятся в оперативной памяти. Благодаря этому запросы на чтение выполняются очень быстро. Запросы на запись также проходят оперативно за счет синхронизации обновлений и последовательного добавления в конец журнала транзакций (Write Ahead Log, WAL), который расположен на жестком диске. Таким образом, данные на диске и в памяти всегда синхронизированы. Последовательная WAL-запись позволяет Tarantool заполнять журнал со скоростью 100 Мбайт/с, соблюдая требования ACID (atomicity, consistency, isolation, durability — «атомарность, согласованность, изоляция и долговечность») [7].
Важно, что Тарантул может работать как на мощных серверах с сотнями гигабайт оперативной памяти, так и на виртуальных машинах от облачных провайдеров, а также на устройствах интернета вещей (Internet of Things, IoT), в т.ч. промышленного (Industrial IoT, IIoT). Tarantool IIoT поддерживает MQTT- и MRAA-протоколы работы с датчиками, генерирующими большие объемы данных для обработке в режиме real time. Еще средства Tarantool IIoT позволяют создавать скрипты для описания процессов сбора технологических показателей с конечных устройств, их обработки и сохранения, обеспечивают репликацию и отправку в облачные ЦОД. Эти возможности делают Tarantool отличным инструментом для разработки IIoT-решений [7].
Обратной стороной всех этих достоинств являются специфические недоставки, характерные как для всех IMDB-систем вообще, так и для Тарантул в частности. Об этом мы поговорим в следующей статье, а сейчас разберем, как связаны Tarantool и Arenadata – отечественный разработчик Big Data решений.
Поскольку Tarantool является open-source решением, исходный код этой системы используется для создания новых Big Data продуктов. В частности, российская компания «Аренадата Софтвер», которая разработала первый отечественный дистрибутив Apache Hadoop (Arenadata Hadoop), массивно-параллельную СУБД Arenadata DB на базе Greenplum и Arenadata QuickMarts – кластерную колоночную СУБД для генерации аналитических отчетов по большим данным в реальном времени, на базе Tarantool создала собственную платформу резидентных вычислений — Arenadata Grid [8]. Чем эта Big Data система отличается от оригинала и как она интегрирована с другими компонентами экосистемы Apache Hadoop, мы рассмотрим завтра.
А обучиться работе с продуктами компании Arenadata и получить сертификат специалиста можно в нашем лицензированном учебном центре повышения квалификации «Школа Больших Данных» в Москве:
- Администрирование кластера Arenadata Hadoop
- Основы Arenadata Hadoop
- Эксплуатация Arenadata DB
- Администрирование кластера Arenadata Streaming Kafka
- Администрирование Arenadata Streaming NiFi
Источники
- https://www.gartner.com/en/documents/3955768/hype-cycle-for-data-management-2019
- https://ru.wikipedia.org/wiki/Резидентная_база_данных
- https://www.information-management.com/news/gartners-19-leading-in-memory-databases-for-big-data-analytics
- https://en.wikipedia.org/wiki/List_of_in-memory_databases
- https://ru.wikipedia.org/wiki/Tarantool
- https://www.cnews.ru/news/top/2019-09-09_iz_mailru_ushel_sozdatel_samogo
- https://www.osp.ru/os/2017/02/13052224/
- https://arenadata.tech/products/adg/
Tarantool
Tarantool – open-source продукт российского происхождения, сервер приложений на языке Lua, интегрированный с резидентной NoSQL-СУБД, которая содержит все обрабатываемые данные и индексы в оперативной памяти, а также включает быстрый движок для работы с постоянным хранилищем (жесткие диски). Благодаря своим архитектурным особенностям, Тарантул позволяет быстро обрабатывать большие объемы данных, поэтому эта СУБД широко применяется в различных Big Data проектах [1].
История разработки и развития
Отметим наиболее значимые вехи развития проекта Tarantool [2]:
- 2008 год – отечественная компания Mail.ru Group начала разработку программного продукта для своих внутренних нужд и собственных сервисов;
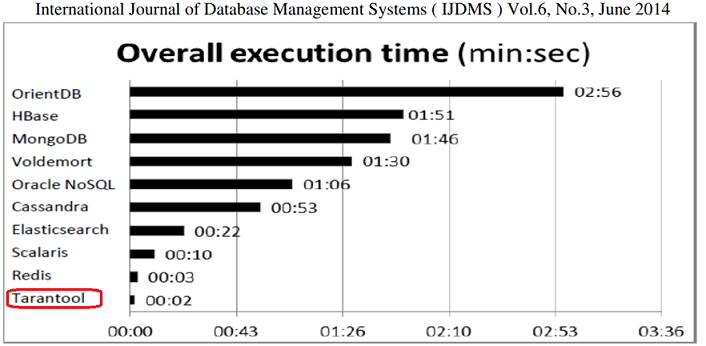
- 2014 год – участие системы в первом официальном независимом тесте на производительности NoSQL-СУБД, который проводили исследователи португальских университетов. Вместе с Tarantool также тестировались и другие популярные Big Data системы класса NoSQL: Cassandra, Apache HBase, MongoDB, Elasticsearch, Redis, Voldemort, Scalaris, Oracle NoSQL и Примечательно, что Tarantool показал наилучшие результаты в 4 из из 5 тестов на обработку 600 тысяч записей под нагрузкой, продемонстрировав свое главное преимущество – высочайшую скорость [3].
- 2014 год – Тарантул внедрен в сервисы соцсетей Badoo и Одноклассники;
- 2016 год – корпорация Mail.ru Group опубликовала исходный код Tarantool в открытом доступе под лицензией BSD;
- 2018 год – Tarantool используется в Мегафоне, Аэрофлоте и Альфа-банке;
- 2019 год – компания Arenadata, разработчик первого отечественного дистрибутива Apache Hadoop и других Big Data Решений, на основе Tarantool создала собственную платформу резидентных вычислений – Arenadata Grid [4].
Как устроен Tarantool: архитектура и принципы работы
Прежде всего отметим наиболее важные концепции Tarantool с точки зрения разработчика Big Data приложений [2]:
- поддержка SQL и документо-ориентированных запросов на скриптовом мультипарадигмальном языке Lua;
- поддержка ACID-транзакций (Atomicity, Consistency, Isolation, Durability – атомарность, согласованность, изоляция, стойкость);
- индексация по первичным ключам, с поддержкой неограниченного числа вторичных ключей и составными ключами в индексах;
- разделение доступа на основе ACL-модели (Access Control List);
- единый механизм упреждающей записив журнал (WAL, Write Ahead Log), который обеспечивает согласованность и сохранность данных в случае сбоя – изменения не считаются завершенными, пока не проходит запись в WAL;
- синхронная и асинхронная репликация локально и на удаленных серверах, когда сразу несколько узлов могут обрабатывать входящие данные и получать информацию от других узлов.
Основными программными компонентами Tarantool являются следующие [1]:
- JIT (Just In Time) Lua-компилятор – LuaJIT;
- Lua-библиотеки для самых распространенных приложений;
- сервер документоориентированной NoSQL-СУБД Tarantool с 2-мя движками – резидентным (In-memory, memtx), который хранит все данные в оперативной памяти, и дисковый (vinyl), который эффективно сохраняет данные на жесткий диск, используя разделение на диапазоны, журнально-структурированные деревья со слиянием (log-structured merge trees) и классические B-деревья.
Перейдем к архитектуре: распределенный кластер Tarantool состоит из подкластеров, которые называются шарды (shard). Каждый шард хранит некоторую часть данных и представляет собой набор реплик, одна из которых является ведущим узлом, обрабатывающим все запросы на чтение и запись. При разделении (шардинге) данных они распределяются на заданное количество виртуальных сегментов с уникальными номерами. Рекомендуется задавать количество сегментов в 100-1000 раз больше, чем потенциальное число кластерных узлов с учетом масштабирования кластера в перспективе. Однако, слишком большое число сегментов может потребовать дополнительную память для хранения информации о маршрутизации, а слишком маленькое – привести к снижению степени детализации балансировки.
Итак, каждый шард хранит уникальное подмножество сегментов, причем один сегмент не может относиться к нескольким шардам одновременно. Таким образом, с архитектурной точки зрения сегментированный кластер Tarantool включает следующие компоненты [5]:
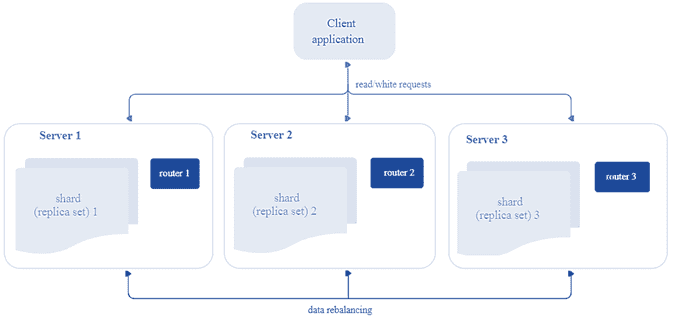
- хранилище (storage) – узел, который хранит подмножество набора данных. Несколько реплицируемых хранилищ составляют набор реплик (шард, shard). У каждого хранилища в наборе реплик есть роль: мастер или реплика. Мастер обрабатывает запросы на чтение и запись. Реплика обрабатывает запросы только на чтение.
- Роутер(router) – автономный компонент, который обеспечивает маршрутизацию запросов чтения и записи от клиентского приложения к шардам. В зависимости от функций приложения, роутер работает на его уровне или на уровне хранилища. Он сохраняет топологию сегментированного кластера прозрачной для приложения, скрывая такие детали, как номер и местоположение шардов, процесс балансировки данных, отказы реплики и восстановление после них. Роутер может сам идентифицировать сегмент, если приложение четко определяет правила вычисления идентификатора сегмента на основе запроса. Для этого роутеру необходимо знать схему данных. У роутера нет постоянного статуса, он не хранит топологию кластера и не выполняет балансировку данных. Роутер поддерживает постоянный пул соединений со всеми хранилищами, созданными при запуске, что помогает избежать ошибок конфигурации.
- Балансировщик – фоновый процесс равномерного распределения сегментов по шардам, во время которого выполняется миграция сегментов по наборам реплик. Балансировщик запускает периодически, перераспределяя данные из наиболее загруженных узлов в менее загруженные, когда предел дисбаланса в наборе реплик превышает показатель, указанный в конфигурации.
Основные сценария использования в Big Data и примеры внедрения
Благодаря высокой скорости обработки данных, типовыми сценариями применения Tarantool в Big Data считаются следующие:
- ускорение распределенных вычислений, в т.ч. на Apache Hadoop и Spark, а также выполнение аналитических SQL-запросов с большими данными в MPP-СУБД, таких как Arenadata DB на базе Greenplum;
- гибридная транзакционно-аналитическая обработка больших данных;
- оперативное кэширование для систем потоковой передачи и шин данных.
На практике это встречается в следующих бизнес-задачах:
- управление телекоммуникационным оборудованием;
- биржевые торги на финансовых рынках и аукционах интернет-рекламы;
- персонализированный маркетинг – формирование персональных маркетинговых предложений с привязкой ко времени и месту;
- игровые рейтинговые таблицы.
Также Tarantool может использоваться и в системах интернета вещей (Internet of Things, IoT), в т.ч. промышленного (Industrial IoT, IIoT). Tarantool IIoT поддерживает основные протоколы работы с датчиками (MQTT и MRAA), которые генерируют большие объемы данных для обработки в реальном времени. Еще эта версия Тарантул позволяет создавать скрипты для описания процессов получения показателей с промышленных устройств, их обработки, сохранения и передачи [6].
Подробнее про примеры использования Tarantool в реальных проектах мы рассказываем в отдельной статье.
Источники
- https://www.tarantool.io/ru/doc/2.3/intro/
- https://ru.wikipedia.org/wiki/Tarantool
- http://airccse.org/journal/ijdms/papers/6314ijdms01.pdf
- https://www.cnews.ru/news/line/2019-11-11_mailru_group_i_ibs_podpisali_soglashenie
- https://www.tarantool.io/ru/doc/2.2/reference/reference_rock/vshard/vshard_architecture/
- https://www.osp.ru/os/2017/02/13052224/
При подготовке материала использовались источники:
https://vc.ru/flood/14639-mrg-tarantool
Зачем вам Tarantool: разгоняем большие данные с помощью In-Memory database