Посещенные ссылки. Visited links (Рейтинг: 0 )
Все в гиперпространстве связанно между собой гиперссылками. Почти каждый переход с одной страницы на другую страницу подразумевает предварительный щелчок мышью по определенной ссылке. Как дать посетителю сайта знать о том, что он уже посещал страницу, на которую ведет определенная ссылка?
Известно достаточно много методов для того, чтобы дать пользователю знать о том, что он уже посещал конкретную страницу в интернете. Какой из этих методов самый подходящий? Цветовое определение ссылок? Подчеркивание? Картинка? При ответе на этот вопрос не стоит забывать о дальтониках, о карманных компьютерах, и, конечно же, не стоит забывать о браузерах, вернее браузере — всеми любимый ослик — Internet Explorer. Появившуюся седьмую версию этого браузера можно называть уже посолидней – осел. Но эта тема для отдельной статьи.
Итак, начнем с Якоба Нильсена – эксперта по удобству и простоте использования. Краткое изложение его статьи по визуализации ссылок (Guidelines for Visualizing Links):
Текстовые ссылки должны быть цветными и подчеркнутыми для того, чтобы достигнуть необходимой воспринимаемости этих ссылок, хотя существуют несколько исключений.
По его словам можно избегать подчеркиваний в навигационном меню сайта и в списках ссылок. При этом пользователю должно быть предельно ясно, какую роль выполняют эти объекты страницы. Если для определения ссылок используются красный и зеленый цвета, то подчеркивание обязательно из-за наиболее распространенных форм дальтонизма.
Подчеркивание также обязательно, если одним из ваших приоритетов является доступность сайта, т.к. много людей имеют плохое зрение.
Примерно 74% всех сайтов используют цветовое определение для распознавания уже посещенных ссылок от еще не посещенных ссылок. Это хорошая дизайнерская традиция, к которой привыкли пользователи.
Цвет не посещенных ссылок должен быть ясным, ярким и насыщенным чем цвет посещенных ссылок, которые должны выглядеть размытыми и тусклыми. Два цвета, отличающие один тип ссылок (которые не открывались) от другого типа ссылок (которые открывались ранее) должны быть оттенком одного и того же цвета. Оттенки голубого цвета больше всего сигнализируют о том, что это ссылка.
Метод Симона Коллисона был признан как один из самых практичных и оригинальных методов. Идея достаточно проста и хорошо подходит для списков со ссылками. На сайтах можно увидеть галочку, которая появляется напротив той ссылки, по которой посетитель уже щелкал мышью или раньше был на странице, куда ведет адрес ссылки. Весь эффект полностью создается в CSS, т.е. XHTML код страницы остается нетронутым. Если внести некоторые изменения в CSS код Симона, то этот метод можно применять к обычным ссылкам, которые не находятся в списках. CSS код этого метода:
Internet Explorer тормозит широкое использование уже давно появившихся псевдо-элементов fore и :after, которые могут идеально выполнять необходимую функцию определения уже посещенных ссылок. Почти все современные браузеры поддерживают эти элементы.
Для псевдо-элементов fore и :after Майк Дэйвидсон (и несколько людей до него) предложил вместо текста использовать знак корня (радикал) – своеобразная галочка. Но эта галочка является не картинкой, а unicode символом ( \221A ), который появляется после ссылки, по адресу которой уже был определенный посетитель. Весь код также находиться в CSS и выглядит следующим образом:
a:visited:after
\00A0 означает непрерывающиеся пустое место (вместо пробела).
Я думаю, что различные галочки иногда могут вводить пользователя в заблуждение. В его понимании этот знак может нести в себе другой смысл. Поэтому необходимо дать знать посетителю сайта о том, какую роль выполняет определенный символ после ссылок.
Что такое » visited links » ?
В нашей базе содержится 4 разных файлов с именем visited links . You can also check most distributed file variants with name visited links.
Подробности о наиболее часто используемом файле с именем «visited links»
Продукт: (Пустое значение) Компания: (Пустое значение) Описание: (Пустое значение) Версия: (Пустое значение) MD5: fdcaa34886216f69bcdab9ad3148d2ca SHA1: d28e5748c6d23b36ac58712e3e9befcec23b4327 SHA256: 0c771311736438fc86d298a1c2a801575bba350eee3cfa2752bab2fa5ed03813 Размер: 131072 Папка: %USERPROFILE%\AppData\Local\Google\Chrome\User Data\Default ОС: Windows 7 Частота: Низкая
Проверьте свой ПК с помощью нашей бесплатной программы

System Explorer это наша бесплатная, удостоенная наград программа для быстрой проверки всех работающих процессов с помощью нашей базы данных. Эта программа поможет вам держать систему под контролем.
«visited links» безопасный или опасный?
Последний новый вариант файла «visited links» был обнаружен 4037 дн. назад.
Комментарии пользователей для «visited links»
У нас пока нет комментариев пользователей к файлам с именем «visited links».
Добавить комментарий для «visited links»
Для добавления комментария требуется дополнительная информация об этом файле. Если вам известны размер, контрольные суммы md5/sha1/sha256 или другие атрибуты файла, который вы хотите прокомментировать, то вы можете воспользоваться расширенным поиском на главной странице .
Если подробности о файле вам неизвестны, вы можете быстро проверить этот файл с помощью нашей бесплатной утилиты. Загрузить System Explorer.
Проверьте свой ПК с помощью нашей бесплатной программы
System Explorer это наша бесплатная, удостоенная наград программа для быстрой проверки всех работающих процессов с помощью нашей базы данных. Эта программа поможет вам держать систему под контролем. Программа действительно бесплатная, без рекламы и дополнительных включений, она доступна в виде установщика и как переносное приложение. Её рекомендуют много пользователей.
Извлечение всех ссылок web-сайта с помощью Python

Одна из задач, которая стояла в рамках проекта, нацеленного на исследование мер поисковой оптимизации (SEO, search engine optimization) информационных ресурсов дочерних структур организации, предполагала поиск всех ссылок и выявление среди них так называемых «мертвых (битых) ссылок», отсылающих на несуществующий сайт, страницу, файл, что в свою очередь понижает рейтинг информационного ресурса.
В этом посте я хочу поделиться одним из способов извлечения всех ссылок сайта (внутренних и внешних), который поможет при решении подобных задач.
Посмотрим, как можно создать инструмент извлечения ссылок в Python, используя пакет requests и библиотеку BeautifulSoup. Итак,
pip install requests bs4Импортируем необходимые модули:
import requests from urllib.parse import urlparse, urljoin from bs4 import BeautifulSoupЗатем определим две переменные: одну для всех внутренних ссылок (это URL, которые ссылаются на другие страницы того же сайта), другую для внешних ссылок вэб-сайта (это ссылки на другие сайты).
# Инициализировать набор ссылок (уникальные ссылки) int_url = set() ext_url = set()Далее создадим функцию для проверки URL – адресов. Это обеспечит правильную схему в ссылке — протокол, например, http или https и имя домена в URL.
# Проверяем URL def valid_url(url): parsed = urlparse(url) return bool(parsed.netloc) and bool(parsed.scheme)На следующем шаге создадим функцию, возвращающую все действительные URL-адреса одной конкретной веб-страницы:
# Возвращаем все URL-адреса def website_links(url): urls = set() # извлекаем доменное имя из URL domain_name = urlparse(url).netloc # скачиваем HTML-контент вэб-страницы soup = BeautifulSoup(requests.get(url).content, "html.parser")Теперь получим все HTML теги, содержащие все ссылки вэб-страницы.
for a_tag in soup.findAll("a"): href = a_tag.attrs.get("href") if href == "" or href is None: # href пустой тег continue
В итоге получаем атрибут href и проверяем его. Так как не все ссылки абсолютные, возникает необходимость выполнить соединение относительных URL-адресов и имени домена. К примеру, когда найден href — «/search» и URL — «google.com» , то в результате получим «google.com/search».
# присоединить URL, если он относительный (не абсолютная ссылка) href = urljoin(url, href)В следующем шаге удаляем параметры HTTP GET из URL-адресов:
parsed_href = urlparse(href) # удалить параметры URL GET, фрагменты URL и т. д. href = parsed_href.scheme + "://" + parsed_href.netloc + parsed_href.path Если URL-адрес недействителен/URL уже находится в int_url , следует перейти к следующей ссылке.
Если URL является внешней ссылкой, вывести его и добавить в глобальный набор ext_url и перейдти к следующей ссылке.
И наконец, после всех проверок получаем URL, являющийся внутренней ссылкой; выводим ее и добавляем в наборы urls и int_url
if not valid_url(href): # недействительный URL continue if href in int_url: # уже в наборе continue if domain_name not in href: # внешняя ссылка if href not in ext_url: print(f"[!] External link: ") ext_url.add(href) continue print(f"[*] Internal link: ") urls.add(href) int_url.add(href) return urls
Напоминаю, что эта функция захватывает ссылки одной вэб-страницы.
Теперь создадим функцию, которая сканирует весь веб-сайт. Данная функция получает все ссылки на первой странице сайта, затем рекурсивно вызывается для перехода по всем извлеченным ссылкам. Параметр max_urls позволяет избежать зависания программы на больших сайтах при достижении определенного количества проверенных URL-адресов.
# Количество посещенных URL-адресов visited_urls = 0 # Просматриваем веб-страницу и извлекаем все ссылки. def crawl(url, max_urls=50): # max_urls (int): количество макс. URL для сканирования global visited_urls visited_urls += 1 links = website_links(url) for link in links: if visited_urls > max_urls: break crawl(link, max_urls=max_urls) Итак, проверим на сайте, к которому имеется разрешение, как все это работает:
if __name__ == "__main__": crawl("https://newtechaudit.ru") print("[+] Total External links:", len(ext_url)) print("[+] Total Internal links:", len(int_url)) print("[+] Total:", len(ext_url) + len(int_url))Вот фрагмент результата работы программы:
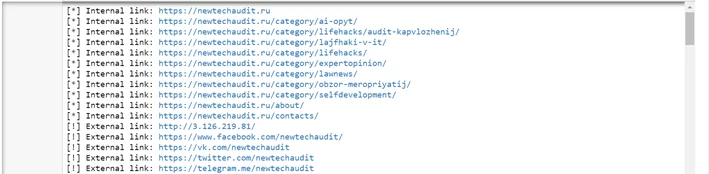
Обратите внимание, что многократный запрос к одному и тому же сайту за короткий промежуток времени может привести к тому, что ваш IP-адрес будет заблокирован. Ссылка на оригинал поста.
При подготовке материала использовались источники:
https://visavi.net/articles/292
https://systemexplorer.net/ru/file-database/file/visited%20links
https://newtechaudit.ru/izvlechenie-vseh-ssylok-veb-sajta-s-pomoshhyu-python/